你也能看懂Hadoop——Hbase
Posted Hadoop大数据应用
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你也能看懂Hadoop——Hbase相关的知识,希望对你有一定的参考价值。
上一期我们了解了Hbase是一个高可靠性、高性能、面向列、可伸缩的分布式数据库,并且对比了它与传统关系数据库的区别。本期我们来看看Hbase 背后的原理,了解它是如何实现高效I/O的。
Hbase的存储结构基于Hadoop的HDFS存储,所以Hbase的存储具备HDFS的特性。Hbase的存储结构如下图所示,我们来一一解读图中的关键角色。
Client
Hbase的客户端Client使用远程过程调用(RPC)与HMaster和HRegionServer进行通信,如果接受到用户管理类请求,则Hbase Client与HMaster进行通信,如果接受到用户数据读写类请求,则Hbase Client与HRegionSever进行通信。
Zookeepe
HMaster
HMaster和HRegionServer依然遵从简单的主从关系,其体系结构图如下所示:
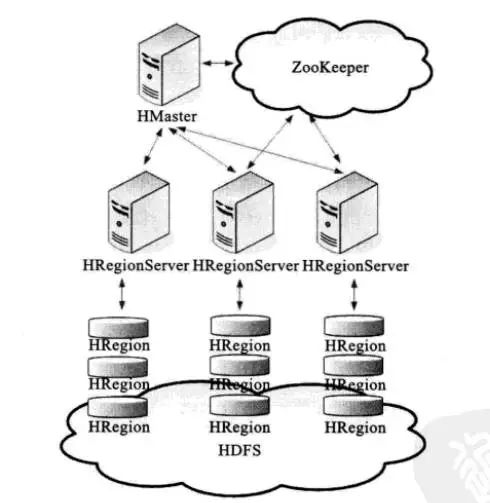
HMaster服务器负责管理所有的HRegion服务器和Table表,其本身不存储数据。HMaster主要实现的功能包括:
管理用户对Table的增删改查操作。
管理HRegionServer的负载均衡,调整HRegion的分布。
在Region 拆分以后,负责新Region的分配。
当HRegionServer停机以后,负责Region的迁移。
HRegionServer
HRegionServer主要负责响应用户I/O需求,向HDFS文件系统中读写数据,是Hbase最核心的模块。原理如下图所示:
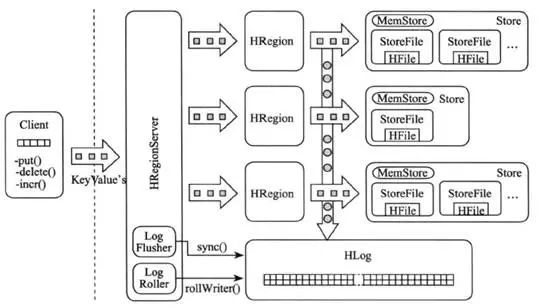
HRegionServer包含两大部分:HRegion部分和HLog部分,HRegion部分由很多个HRegion组成,每一个HRegion又由很多个Store组成,每一个Store存储的实际上是一个列族(ColumnFamily)下的数据。在此的ColumnFamily与上一期介绍的Table中的ColumnFamily对应,由此可以看出ColumnFamily是一个集中的存储单元,因此具有相同I/O特性的列应尽量设计在一个ColumnFamily中,这样最高效。
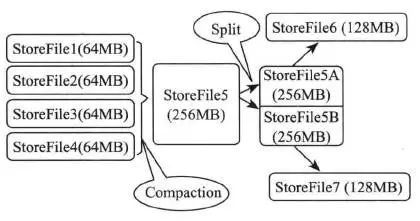
Store存储是HBase存储的核心,它由两部分组成:一部分是MemStore,一部分是StoreFile。用户写入的数据首先会放入MemStore,当MemStore写满了以后会将其变成一个StoreFile。由于MemStore运行在内存中,所以用户只要完成数据写入内存就可以立即返回,保证了Hbase I/O高性能。当StoreFile文件数量增长到一定的阈值时会触发合并操作,将多个StoreFile合并成一个StoreFile,合并的过程中会将冗余的数据进行删除或合并的操作。StoreFile在完成合并操作以后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后会触发拆分操作,同时把当前的StoreFile拆分成2个子文件,并分别分配到相应的HRegionServer上,这么做的目的是避免StoreFile文件过大导致单个Region压力较大,起到压力分担的效果。
HLog用来存储数据日志,其采用的是先写日志的方式,即数据在写入MemStore之前,会先写一份数据到HLog文件之中。HLog文件会定期滚动保存新的数据,删除已经存入StoreFile的数据。这么做的原因在于当HRegionServer出现意外终止时,MemStore仍在内存中运行,保存在其中的数据将会丢失。此时HMaster首先会处理遗留的HLog文件,将不同Region的Log数据进行拆分,分别放到相应的Region之下,再将失效的Region重新分配。领取这些Region的HRegionServer在Load Region的过程中,会发现有历史的HLog需要处理,因此会重新加载HLog中的数据到MemStore中,然后保存到StoreFile,以此完成数据恢复。
Hbase中的所有数据文件都存储在Hadoop HDFS文件系统上,主要包括HFile和HLogFile两种文件格式。
HFile存储格式
HFile是一种二进制格式文件,用于存储Hbase里的Key-Value数据。实际上StoreFile就是对HFile做了轻量级包装整合,即StoreFile底层就是HFile。
HFile主要分为六个部分:
1) Data Block:保存表中的数据。
2) Meta Block:保存用户自定义的Key-Value键值对。
3) File Info:保存HFile的元信息。
4) Data Block Index:Data Block的索引,每条索引的key是被索引的Block的第一条记录的key。
5) Meta Block Index:Meta Block的索引。
6) Trailer:保存了每一段的偏移量。
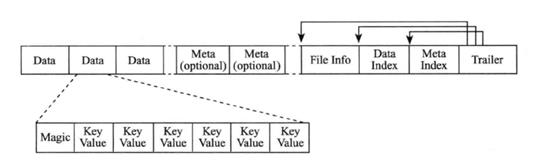
其中,Data Block和Meta Block通常采用压缩方式存储,这样能大大减少磁盘I/O,但是会增加CPU压缩和解压缩的开销。
HLogFile存储格式
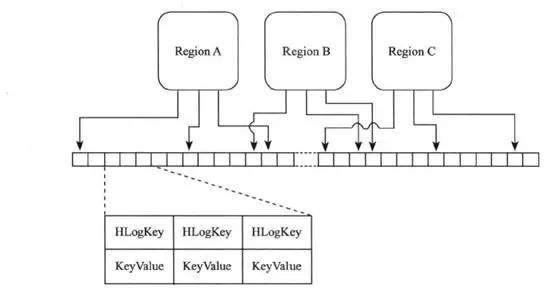
HLogFile的存储格式是WAL(Write Ahead Log),记录了数据的所有变更,一旦数据修改,就可以从Log中进行恢复。每个RegionServer维护一个HLog,这样不同Region的日志会混在一起,目的是不断的追加单个文件,同时写多个文件时可以减少磁盘寻址次数,提高I/O能力。但这样做也有缺陷,如果RegionServer下线,为了恢复其上的数据时,需要对RegionServer上的Log进行拆分,然后分发到其他Region上进行恢复。
HLogFile从物理意义上看是一个普通的Hadoop Sequence File。Sequence File 的Key是HLogKey对象,记录了写入数据的归属信息。HlogSequeceFile 的Value 是HBase的KeyValue对象,即对应HFile中的KeyValue。HLogFile的存储格式如下图所示:
文章转载自:华星智能制造规划处
Hadoop大数据应用
你也能懂大数据
以上是关于你也能看懂Hadoop——Hbase的主要内容,如果未能解决你的问题,请参考以下文章