小白也能看懂的dubbo3应用级服务发现详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白也能看懂的dubbo3应用级服务发现详解相关的知识,希望对你有一定的参考价值。
参考技术Adubbo 是一款开源的 RPC 框架,主要有3个角色: 提供者(provider) 、 消费者(consumer) 、 注册中心(registry)
提供者启动时向注册中心注册服务地址,消费者启动时订阅服务,并通过获取到的提供者地址发起调用,当提供者地址变更时,通过注册中心向消费者推送变更。这就是 dubbo 主要的工作流程。
在2.7.5之前,dubbo 只支持接口级服务发现模型,>=2.7.5的版本提供了接口级与应用级两种服务发现模型,3.0之后的版本应用级服务发现更是非常重要的一个功能。
本文将从为什么需要引入应用级服务发现,dubbo 实现应用级服务发现的难点以及dubbo3 是如何解决这些问题这三个部分进行讲解。
开始前,我们先了解下 dubbo 最初提供的接口级服务发现是怎样的。
dubbo 服务的注册发现是以 接口 为最小粒度的,在 dubbo 中将其抽象为一个 URL ,大概长这样:
看着很乱?捋一捋:
无论是存储还是变更推送压力都可能遇到瓶颈,数据多表现在这两个方面:
这个问题好解决: 拆!
dubbo 在 2.7 之后的版本支持了 元数据中心 与 配置中心 ,对于URL的参数进行分类存储。持久不变的(如application、method等)参数存储到元数据中心中,可能在运行时变化(timeout、tag)的存储到配置中心中
无论是增加一台机器还是增加一个接口,其增长都是线性的,这个问题比单条数据大更严重。
当抹去注册信息中的 interface 信息,这样数据量就大大减少
只用过 dubbo 的同学可能觉得这很主流。
但从服务发现的角度来看:
无论是用的最多的服务注册发现系统 DNS ,又或者是 SpringCloud 体系、 K8S 体系,都是以应用为维度进行服务注册发现的,只有和这些体系对齐,才能更好地与之进行打通。
在我了解的范围里,目前只有 dubbo 、 SOFARPC 、 HSF 三个阿里系的 RPC 框架支持了接口级的服务发现。
provider端暴露服务:
consumer端引用服务:
本地调用远程的方法时,只需要配置一个 reference ,然后直接使用 interface 来调用,我们不必去实现这个 interaface,dubbo 自动帮我们生成了一个代理进行 RPC 调用,屏蔽了通信的细节,让我们有种 像调用本地方法一样调用远程方法的感觉 ,这也是 dubbo 的优势。
从这里我们能看出为什么 dubbo 要设计成接口级服务发现,因为要为每一个 interface 生成一个代理,就必须定位到该 interface 对应服务暴露的服务地址,为了方便,dubbo 就这么设计了。
如果让我来设计应用级服务发现,注册不必多说,按应用名注册即可。
至于订阅,在目前 dubbo 机制下,必须得告诉消费者消费的每个接口是属于哪个应用,这样才能定位到接口部署在哪里。
实现 dubbo 应用级服务发现,难点在于
保留接口级服务发现,且默认采取双注册方式,可配置使用哪种服务发现模型,如下配置使用应用级服务发现
名词有点高大上,但道理很简单,让 dubbo 自己去匹配,提供者注册的时候把接口和应用名的映射关系存储起来,消费者消费时根据接口名获取到部署的应用名,再去做服务发现。
数据存储在哪里?显然元数据中心非常合适。该方案用户使用起来和之前接口级没有任何不同,但需要增加一个元数据中心,架构变得复杂。
且有一个问题是,如果接口在多个应用下部署了,dubbo 查找的策略是都去订阅,这可能在某些场景下不太合适。
本文从接口级服务发现讲到应用级服务发现,包含了为什么 dubbo 设计成接口级服务发现,接口级服务发现有什么痛点?基于 dubbo 现状如何设计应用级服务发现,应用级服务发现实现有什么难点等等问题进行解答,相信看完的小伙伴一定有所收获。
入门级解读:小白也能看懂的TensorFlow介绍
选自medium
机器之心编译
参与:Jane W、邵明、微胖
本文是日本东京 TensorFlow 聚会联合组织者 Hin Khor 所写的 TensorFlow 系列介绍文章的Part 3 和 Part4,自称给出了关于 TensorFlow 的 gentlest 的介绍。,作者谈到单一特征问题的线性回归问题以及训练(training)的含义,这两部分将讲解 TensorFlow(TF)进行多个特征的线性回归和逻辑回归。
矩阵和多特征线性回归
快速回顾
之前文章的前提是:给定特征——任何房屋面积(sqm),我们需要预测结果,也就是对应房价($)。为了做到这一点,我们:
我们找到一条「最拟合」所有数据点的直线(线性回归)。「最拟合」是当线性回归线确保实际数据点(灰色点)和预测值(内插在直线上的灰色点)之间的差异最小,即最小化多个蓝线之和。
使用这条直线,我们可以预测任何房屋的价格。
使用单一特征线性回归进行预测
多特征线性回归概述
实际上,任何预测都依赖于多个特征,于是我们从单特征的线性回归进阶到 带有两个特征的线性回归;之所以选择两个特征,是为了让可视化和理解简明些,但这个思想可以推广到带有任何数量特征的线性回归。
我们引进一个新的特征——房间数量。当收集数据点时,现在我们需要在现有特征「房屋面积」之上收集新特征「房间数」的值,以及相应的结果「房屋价格」。
我们的图表变成了 3 维的。
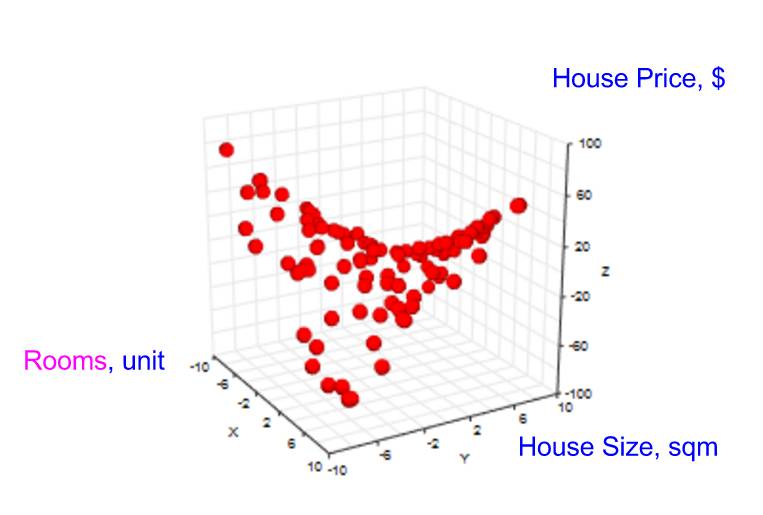
结果「房屋价格」以及 2 个特征(「房间数」,「房屋面积」)的数据点空间
然后,我们的目标变成:给定「房间数」和「房屋面积」,预测「房屋价格」(见下图)。
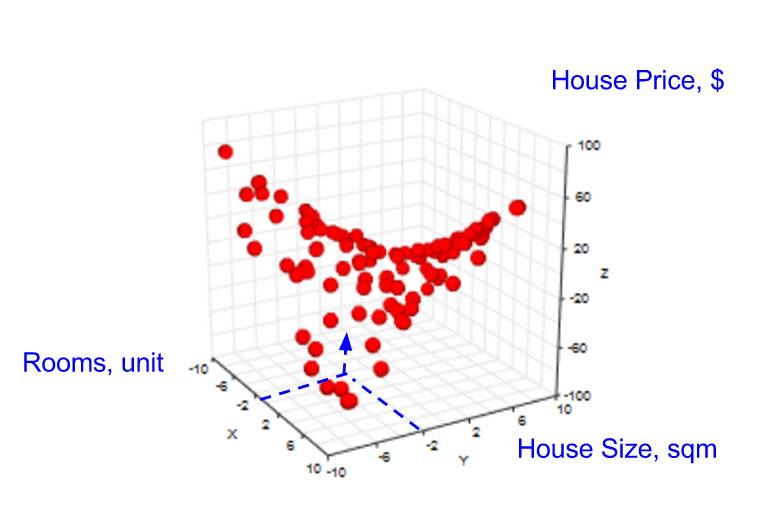
由于缺少数据点,有时无法对给定的 2 个特征进行预测
在单一特征的情形中,当没有数据点时,我们需要使用线性回归来创建一条直线,以帮助我们预测结果房屋价格。在 2 个特征的情形中,我们也可以使用线性回归,但是需要创建一个平面(而不是直线),以帮助我们预测(见下图)。
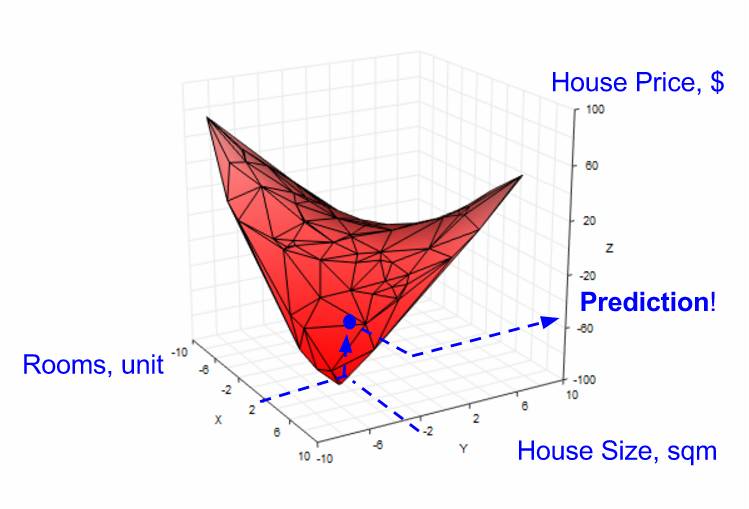
使用线性回归在 2 个特征空间中的创建一个平面来做预测
多特征线性回归模型
回忆单一特征的线性回归(见下图左边),线性回归模型结果为 y,权重为 W,房屋大面积为 x,偏差为 b。
对于 2 个特征的回归(参见下图右侧),我们引入另一个权重 W2,另一个自变量 x2 来代表房间数的特征值。
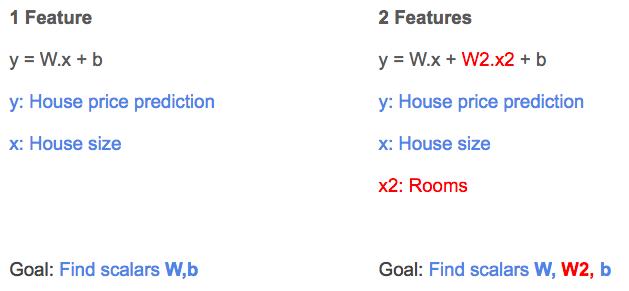
单特征 vs. 2 个特征的线性回归方程
如之前讨论的那样,当我们执行线性回归时,梯度下降算法能帮助学习系数 W、W2 和 b 的值。
Tensorflow 的多特征线性回归
1.快速回顾
单特征线性回归的 TF 代码由 3 部分组成(见下图):
构建模型(蓝色部分)
基于模型构建成本函数(红色部分)
使用梯度下降(绿色部分)最小化成本函数

用于单特征线性回归的 Tensorflow 代码
2.Tensorflow 的 2 个特征的线性回归
TF 代码中 2 个特征的线性回归方程(如上所述)的变化(相比单特征)用红色显示。

注意,增加新特征的这种方式效率低;随着特征数量的增长,所需的变量系数和自变量的数量会增加。实际的模型有更多的特征,这恶化了这个问题。那么,如何能有效地表示特征呢?
解决方法:矩阵
首先,让我们将表征两个特征的模型推广到表征 n 个特征的模型:

复杂的 n 特征公式可以用矩阵简化,矩阵被内置于 TF 中,这是因为:
数据可以用多维表示,这契合我们表征具有 n 个特征的数据点(左下方,也称为特征矩阵)以及具有 n 个权重模型(右下,也称为权重矩阵)的方式

单个数据点的 n 个特征与模型的矩阵形式的 n 个权重
在 TF 中,它们将被写为:
x = tf.placeholder(tf.float,[1,n])
W = tf.Variable(tf.zeros [n,1])
注意:对于 W,我们使用 tf.zeros,它将所有 W1,W2,...,Wn 初始化为零。
在数学上,矩阵乘法是向量乘法的加总;因此自然地,特征(中间的一个)和权重(右边的)矩阵之间的矩阵乘法给出(左边的)结果,即等于 n 个特征的线性回归公式的第一部分(如上所述),没有截距项。

特征和权重矩阵之间的矩阵乘法给出结果(未添加截距项)
在 TF 中,这种乘法将表示为:
y = tf.matmul(x, W)
多行特征矩阵(每行表示数据点的 n 个特征)之间的矩阵乘法返回多行结果,每行代表每个数据点的结果/预测(没有加入截距项);因此一个矩阵乘法就可以将线性回归公式应用于多个数据点,并对应地产生多个预测(每个数据点对应一个结果)(见下文)
注意:特征矩阵中的 x 表示变的更复杂,即我们使用 x1.1、x1.2,而不是 x1、x2 等,因为特征矩阵(中间矩阵)从表示 n 个特征(1 行 x,n 列)的单个数据点扩展到表示具有 n 个特征(m 行 x,n 列)的 m 个数据点。因此,我们扩展 x <n>(如 x1)到 x <m >.<n>(如 x1.1),其中,n 是特征数,m 是数据点的数量。

具有模型权重的多行矩阵乘法产生矩阵的多个行结果
在 TF 中,它们将被写为:
x = tf.placeholder(tf.float,[m,n])
W = tf.Variable(tf.zeros [n,1])
y = tf.matmul(x,W)
最后,向结果矩阵添加常数,也就是将常数添加到矩阵中的每一行
在 TF 中,用矩阵表示 x 和 W,无论模型的特征数量或要处理的数据点数量,矩阵都可以简化为:
b = tf.Variable(tf.zeros[1])
y = tf.matmul(x, W) + b
Tensorflow 的多特征备忘单
我们做一个从单一特征到多特征的线性回归的变化的并行比较:

Tensorflow 中的单特征与 n 个特征的线性回归模型
总结
在本文中,我们介绍了多特征线性回归的概念,并展示了我们如何将模型和 TF 代码从单特征的线性回归模型扩展到 2 个特征的线性回归模型,并可以推广到 n 特征线性回归模型。最后我们为多特征的 TF 线性回归模型提供了一张备忘单。
逻辑回归
逻辑回归综述
我们已经学会了如何使用 Tensorflow(TF)去实现线性回归以预测标量值得结果,例如给定一组特征,如住房大小,预测房价。
然而,有时我们需要对事物分类(classify)而不是去预测一个具体的数值,例如给定一张含有数字(0-9 十个数字中的一个)的图片,我们需要将其分类为 0,1,2,3,4,5,6,7,8,9 十类。或者,我们需要将一首歌曲进行归类,如归类为流行,摇滚,说唱等。集合 [0,1,2,...,9]、[流行,摇滚,说唱,等等] 中的每一个元素都可以表示一个类。在计算机中,我们通常用数字对抽象名词进行表示,比如,pop = 0, rock = 1, 等等。为了实现分类,我们使用 TF 来实现逻辑回归。
在本文中,我们将使用逻辑回归将数字图片归类为 0,1,2,3,4,5,6,7,8,9 这十类。
逻辑回归的细节
线性回归中的许多概念仍然用于逻辑回归之中。我们可以再次使用公式 y = W.x + b,但是有一些不同的地方。让我们看看线性回归和逻辑回归的公式:
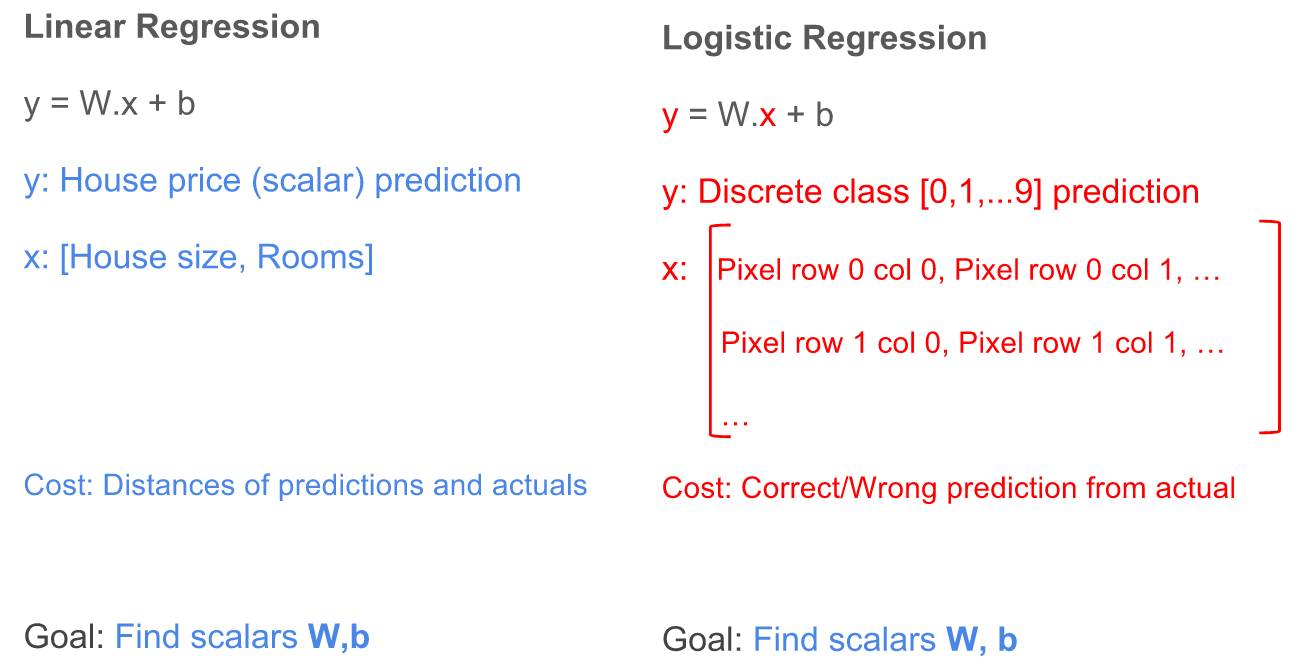
线性回归与逻辑回归的区别与相似
区别:
结果(y):对于线性回归,结果是一个标量值(可以是任意一个符合实际的数值),例如 50000,23.98 等;对于逻辑回归,结果是一个整数(表示不同类的整数,是离散的),例如 0,1,2,... 9。
特征(x):对于线性回归,特征都表示为一个列向量;对于涉及二维图像的逻辑回归,特征是一个二维矩阵,矩阵的每个元素表示图像的像素值,每个像素值是属于 0 到 255 之间的整数,其中 0 表示黑色,255 表示白色,其他值表示具有某些灰度阴影。
成本函数(成本):对于线性回归,成本函数是表示每个预测值与其预期结果之间的聚合差异的某些函数;对于逻辑回归,是计算每次预测的正确或错误的某些函数。
相似性:
训练:线性回归和逻辑回归的训练目标都是去学习权重(W)和偏置(b)值。
结果:线性回归与逻辑回归的目标都是利用学习到的权重和偏置值去预测/分类结果。
协调逻辑回归与线性回归
为了使逻辑回归利用 y = W.b + x,我们需要做出一些改变以协调上述差异。
1.特征变换,x
我们可以将二维的图片特征(假设二维特征有 X 行,Y 列)转换成一维的行向量:将第一行以外的其它行数值依顺序放在第一行后面。

转换图像特征以适用于逻辑回归公式
2.预测结果转换,y
对于逻辑回归,y 不能作为标量,因为预测可能最终为 2.3 或 11,这不在可能的类 [0,1,...,9] 中。
为了解决这个问题,y 应该被转换成列向量,该向量的每个元素代表逻辑回归模型认为属于某个特定类的得分。在下面的示例中,预测结果为类'1',因为它具有最高得分。
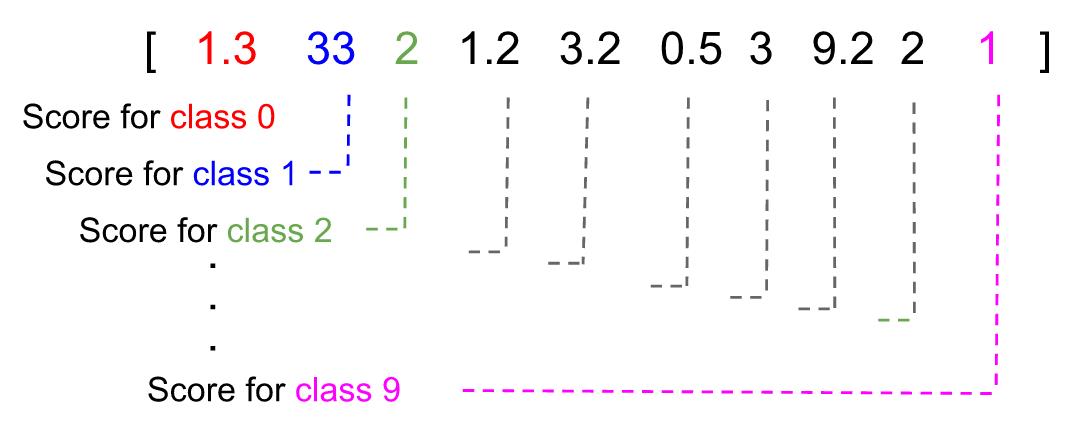
每个类的分数和具有最高分数的类成为被预测的类
对于给定的图片,为求这个分数向量,每个像素都会贡献一组分数(针对每一类),分数表示系统认为这张图片属于某类的可能性,每个像素分数之和成为预测向量。
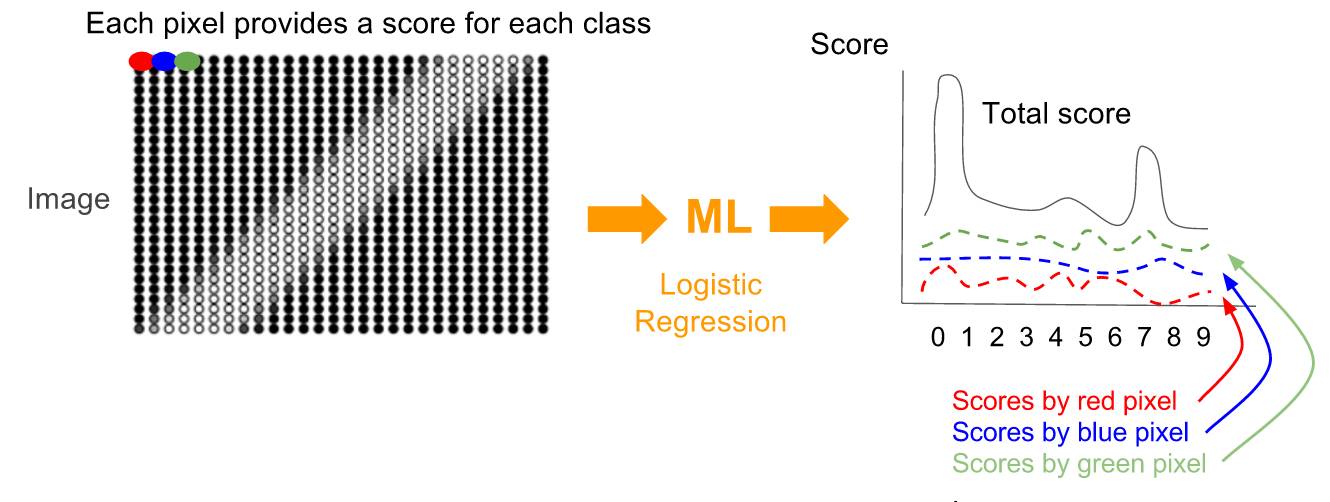 每个像素提供一个分数向量;每个类别有一个分数,最后变成预测向量。所有预测向量的总和变成最终预测。
每个像素提供一个分数向量;每个类别有一个分数,最后变成预测向量。所有预测向量的总和变成最终预测。
3.成本函数的变换
涉及到预测结果和实际结果之间数值距离的任何函数都不能作为成本函数。对于数字图片「1」,这样的成本函数将使预测值「7」(7-1=6)更严重地惩罚预测值「2」(2-1=1),尽管两个预测结果都是错误的。
我们即将使用的成本函数,交叉熵(H),用以下几个步骤实现:
1. 将实际图片的类向量(y')转化成 one-hot 向量,这是一个概率分布。
2. 将预测类 (y) 转化成概率分布。
3. 使用交叉熵函数去计算成本函数,这表示的是两个概率分布函数之间的差异。
第一步:One-hot 向量
由于我们已经将预测 (y) 转换成分数向量,因此,我们也应该将实际图片类(y』)转换成相同维数的向量;one-hot 向量是将对应于实际类的的元素为设为 1,其它元素为 0。下面,我们展示表示 0-9 十个类中一个类的 one-hot 向量。
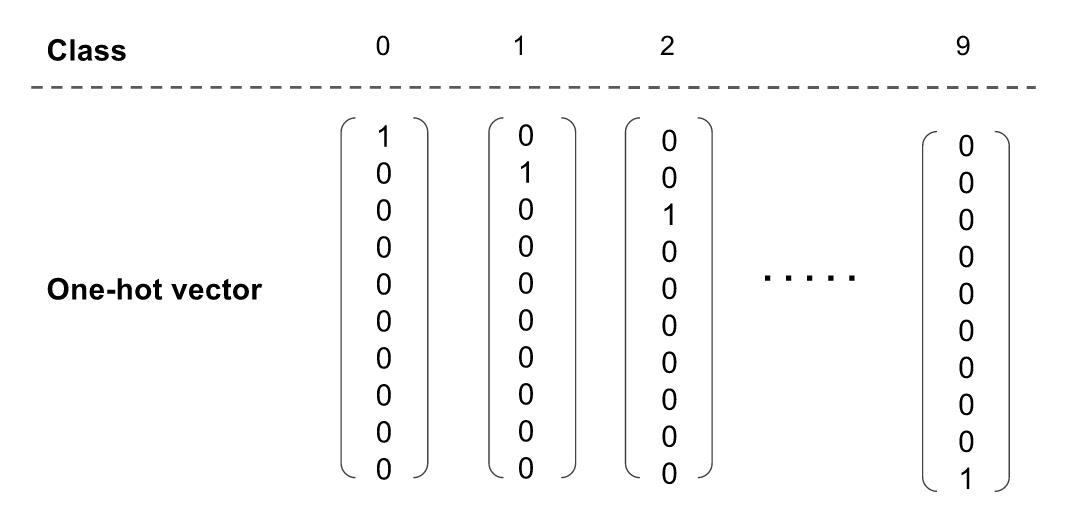
图片类和它们的 one-hot 向量表示
假设实际图像上是数字「1」(y'),它的 one-hot 向量是 [0,1,0,0,0,0,0,0,0,0],假设其预测向量 (y) [1.3, 33, 2, 1.2, 3.2, 0.5, 3, 9.2, 1],绘制比较如下:
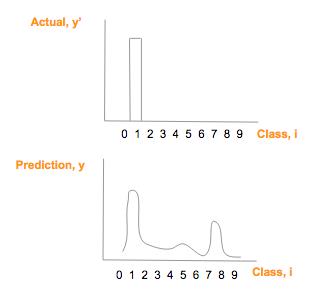
真实图片 one—hot 向量(顶)预测类别概率
第二步:用 softmax 实现概率分布
为了在数学上比较这两个「图」的相似性,交叉熵是一个好方法。(这里是一个很棒但比较长的解释,如果你对细节感兴趣的话。https://colah.github.io/posts/2015-09-Visual-Information/)
然而,为了利用交叉熵,我们需要将实际结果向量(y')和预测结果向量(y)转换为「概率分布」,「概率分布」意味着:
每个类的概率/分数值在 0-1 之间;
所以类的概率/分数和必须是 1;
实际结果向量(y')如果是 one-hot 向量,满足了上述限制。
为预测结果向量(y), 使用 softmax 将其转换为概率分布:
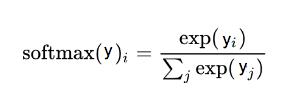
softmax 函数,这里 i 是表示 0, 1, 2, …, 9 十类
这个过程只需要简单的两步,预测向量(y)中的每个分量是 exp(y_i) 除以所有分量的 exp() 的和。
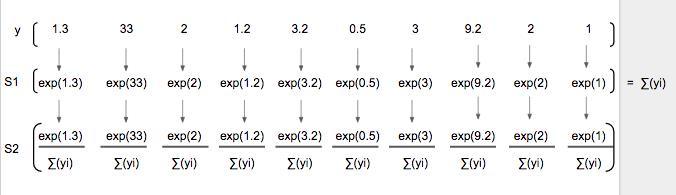
注意:softmax(y)图形在形状上与 prediction (y) 相似,但是仅仅有较大的最大值和较小的最小值
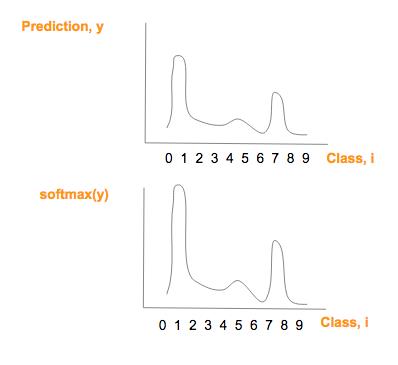
使用 softmax 前后预测(y)曲线
第三步:交叉熵
现在,我们将预测向量分数概率分布(y')和实际向量分数概率分布 (y) 运用交叉熵。
交叉熵公式:
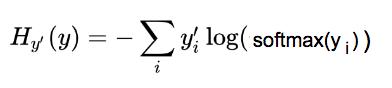
交叉熵作为我们想最小化的成本函数
为了快速理解这个复杂的公式,我们将其分为 3 部分(见下文)。注意,本文中的符号,我们使用 y_i 表示 y 的第 i 个分量。
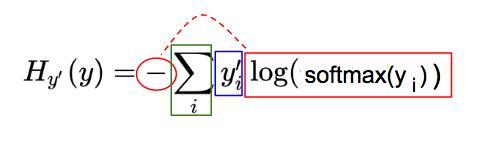
交叉熵(H)公式可视为三个部分:红,蓝,绿
蓝:实际图像类(y')对应的 one-hot 图,参看 one-hot 向量部分:
红:由预测向量元素(y)经过softmax(y),-og(softmax(y)一系列变化而来:
绿:每一图片类别 i,其中,i = 0, 1, 2, …, 9, 红蓝部分相乘的结果
以下图例会进一步简化理解。
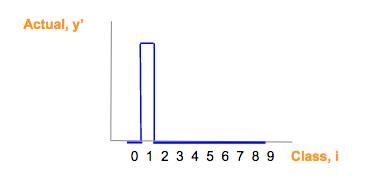
蓝色制图只是真实图片类别(y')one-hot 向量。
每个预测向量元素,y,转换成 -log(softmax(y),就得到红图:
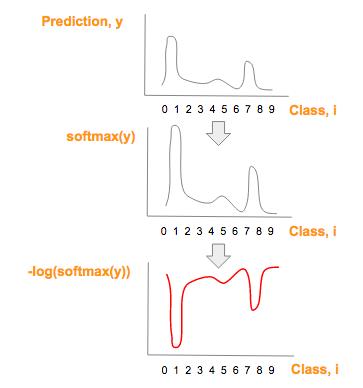
预测类别向量(y)一系列转换后,得到红图
如果你想完全地理解第二个变换 -log(softmax(y)) 与 softmax(y) 为什么成反比,请点击 video or slides(参见文末资源部分).
交叉熵(H),这个绿色的部分是每个类别的蓝色值和红色值的乘积和,然后将它们做如下相加:
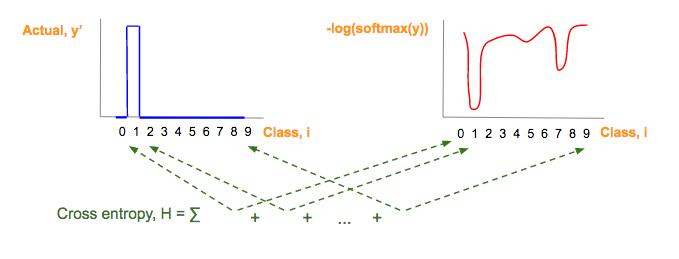
交叉熵是每个图像类的蓝色值和红色值的乘积之和。
由于这张蓝色图片对应一个 one-hot 向量,one-hot 向量仅仅有一个元素是 1,它对应一个正确的图片类,交叉熵的其它所有元素乘积为 0,交叉熵简化为:

将所有部分放到一起
有了三个转换后,现在,我们就可以将用于线性回归的技术用于逻辑回归。下面的代码片段展示的是本系列文章第三部分线性回归代码和代码适用逻辑回归所需要的变化之间的对比。
逻辑回归的目标是最小化交叉熵(H),这意味着我们只需要最小化 -log(softmax(y_i)项;因为该项与 softmax(y_i)成反比,所以我们实际上是最大化该项。
使用反向传播去最小化交叉熵 (H ) 将改变逻辑回归的权重 W 和偏置 b。因此,每张图片的像素值将会给出对应图片类最高分数/概率!(最高分数/概率对应于正确的图片类)
将线性回归方法用于逻辑回归之中,「total_class」是欲分类问题的总类数量,例如,在上文手写数字体识别例子中,total_class=10。
1. 将特征变换成一维特征;
2. 将预测结果向量、实际结果向量变化成 one-hot 向量;
3. 将成本函数从平方误差函数变化到交叉熵。
总结
线性回归对基于给定特征的预测(数值)是有帮助的,逻辑回归根据输入特征实现分类是有帮助的。
我们展示了如何调整线性回归 y = W.x + b 实现逻辑回归:(1)转换特征向量;2)转换预测/结果向量;(3)转换成本函数。
当你掌握了 one-hot 向量,softmax,交叉熵的知识,你就可以处理谷歌上针对「初学者」的图片分类问题。
资源:
针对初学者的图像识别的谷歌代码:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/tutorials/mnist/mnist_softmax.py
slideshare 上的幻灯片:http://www.slideshare.net/KhorSoonHin/gentlest-introduction-to-tensorflow-part-3
油管上的视频:https://www.youtube.com/watch?v=F8g_6TXKlxw
原文链接:https://medium.com/all-of-us-are-belong-to-machines/gentlest-intro-to-tensorflow-4-logistic-regression-2afd0cabc54#.glculhxzi
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
以上是关于小白也能看懂的dubbo3应用级服务发现详解的主要内容,如果未能解决你的问题,请参考以下文章