一文读懂大数据时代的结构化存储数据库——HBase
Posted 数据库开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂大数据时代的结构化存储数据库——HBase相关的知识,希望对你有一定的参考价值。
开源最前线(ID:OpenSourceTop) 猿妹 整编
综合自:GitHub、http://blog.csdn.net/u010270403/article/details/51648462等
Hbase非常适合于非结构化数据存储的数据库,2006年底由PowerSet 的Chad Walters和Jim Kellerman 发起,2008年成为Apache Hadoop的一个子项目。现已作为产品在多家企业被使用
分布式数据库 HBase
授权协议:Apache
开发语言:Java
操作系统:跨平台
HBase项目简介
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。
Hbase 特性
● 大表:数十亿行*数百万列*数千个版本 = TB级或PB级的存储
● 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
● 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
● 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
● 数据类型单一:Hbase中的数据都是字符串,没有类型
HBase系统架构
HBase中的组件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等,HBase中的每张表都通过行键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
相关名词介绍
RowKey:是Byte array,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要。表中的行根据行的键值进行排序,数据按照RowKey的字典序排序存储
Column Family:列族,拥有一个名称(string),包含一个或者多个相关列。列族须作为表模式(schema)定义的一部分预先定义。如create 'alarmInfo' ,'i'
Column:属于某一个columnfamily,familyName:columnName,每条记录可动态添加
Version Number:类型为Long,默认值是系统时间戳,可由用户自定义
Value(Cell):由{row key, column(=<family> + <label>), version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。
HBase逻辑模型
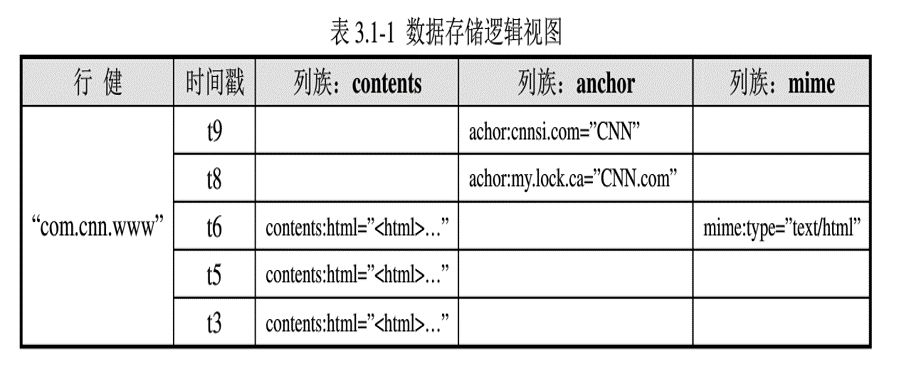
HBase以表的形式存储数据。表有行和列组成。列划分为若干个列族(row family)
Hbase 物理模型
Table中所有行都按照row key的字典序排列;Table在行的方向上分割为多个Region;Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。
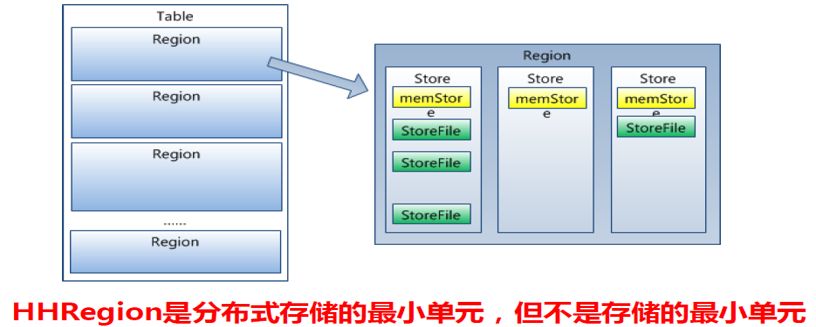
Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个store保存一个columns family;每个Strore又由一个memStore和0至多个StoreFile组成,StoreFile包含HFile;memStore存储在内存中,StoreFile存储在HDFS上。
Hbase 请求过程
HBase是一个分布式数据库,因此一张表的数据可能会分布在不同的节点中。需要注意的是 region是Hbase分布式存储的最小单位,但region不是HBase存储的最小单位。在HBase中,一张表会被根据行键值的范围划分为几个region,然后不同的region将会放在不同的region服务器上,被服务器上的HRegionServer 所管理和维持。
因此我们可以推断出,当我们发送一个查找(插入、删除)请求时,首先客户端能根据请求中的行键值去确定该行键值应该存储在哪一个region上,并且该region在哪一个region服务器上(该查询过程主要使用-ROOT-表、和.meta表,当定位到操作的region服务器的位置以后,客户端(Client)会将该操作发送到region服务器上,然后请求操作可能会被直接执行,也可能会进入任务队列等待
Hbase 与RDBMS对比
为什么采用HBase?
HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.所谓非结构化数据存储就是说HBase是基于列的而不是基于行的模式,这样方面读写你的大数据内容。
HBase是介于Map Entry(key & value)和DB Row之间的一种数据存储方式。就点有点类似于现在流行的Memcache,但不仅仅是简单的一个key对应一个 value,你很可能需要存储多个属性的数据结构,但没有传统数据库表中那么多的关联关系,这就是所谓的松散数据。
简单来说,你在HBase中的表创建的可以看做是一张很大的表,而这个表的属性可以根据需求去动态增加,在HBase中没有表与表之间关联查询。你只需要 告诉你的数据存储到Hbase的那个column families 就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。但是你需要注意HBase中不包含事务此类的功 能。
●本文编号282,以后想阅读这篇文章直接输入282即可
●输入m获取文章目录
大数据与人工智能
更多推荐《》
涵盖:程序人生、算法与数据结构、黑客技术与网络安全、大数据技术、前端开发、Java、Python、Web开发、安卓开发、ios开发、C/C++、.NET、Linux、数据库、运维等。
以上是关于一文读懂大数据时代的结构化存储数据库——HBase的主要内容,如果未能解决你的问题,请参考以下文章