如何使用scala+spark读写hbase?
Posted 我是攻城师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用scala+spark读写hbase?相关的知识,希望对你有一定的参考价值。
最近工作有点忙,所以文章更新频率低了点,希望大家可以谅解,好了,言归正传,下面进入今天的主题:
如何使用scala+spark读写Hbase
软件版本如下:
scala2.11.8
spark2.1.0
hbase1.2.0
公司有一些实时数据处理的项目,存储用的是hbase,提供实时的检索,当然hbase里面存储的数据模型都是简单的,复杂的多维检索的结果是在es里面存储的,公司也正在引入Kylin作为OLAP的数据分析引擎,这块后续有空在研究下。
接着上面说的,hbase存储着一些实时的数据,前两周新需求需要对hbase里面指定表的数据做一次全量的update以满足业务的发展,平时操作hbase都是单条的curd,或者插入一个批量的list,用的都是hbase的java api比较简单,但这次涉及全量update,所以如果再用原来那种单线程的操作api,势必速度回慢上许多。
关于批量操作Hbase,一般我们都会用MapReduce来操作,这样可以大大加快处理效率,原来也写过MR操作Hbase,过程比较繁琐,最近一直在用scala做spark的相关开发,所以就直接使用scala+spark来搞定这件事了,当然底层用的还是Hbase的TableOutputFormat和TableOutputFormat这个和MR是一样的,在spark里面把从hbase里面读取的数据集转成rdd了,然后做一些简单的过滤,转化,最终在把结果写入到hbase里面。
整个流程如下:
(1)全量读取hbase表的数据
(2)做一系列的ETL
(3)把全量数据再写回hbase
核心代码如下:
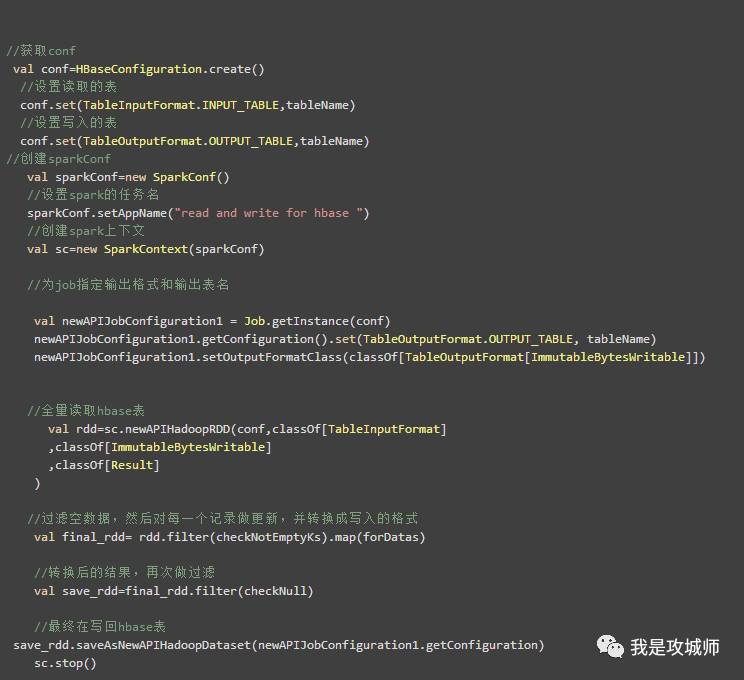
从上面的代码可以看出来,使用spark+scala操作hbase是非常简单的。下面我们看一下,中间用到的几个自定义函数:
第一个函数:checkNotEmptyKs
作用:过滤掉空列簇的数据

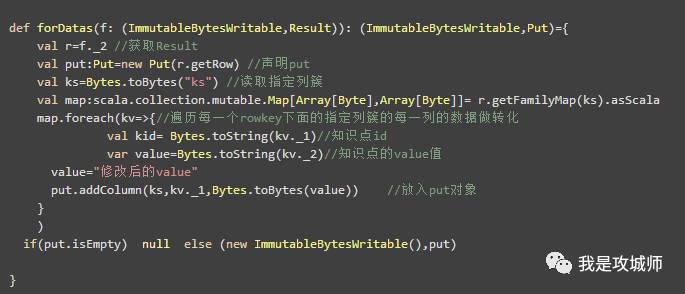
第二个函数:forDatas
作用:读取每一条数据,做update后,在转化成写入操作
第三个函数:checkNull
作用:过滤最终结果里面的null数据
上面就是整个处理的逻辑了,需要注意的是对hbase里面的无效数据作过滤,跳过无效数据即可,逻辑是比较简单的,代码量也比较少。
除了上面的方式,还有一些开源的框架,也封装了相关的处理逻辑,使得spark操作hbase变得更简洁,有兴趣的朋友可以了解下,github链接如下:
https://github.com/nerdammer/spark-hbase-connector
https://github.com/hortonworks-spark/shc
以上是关于如何使用scala+spark读写hbase?的主要内容,如果未能解决你的问题,请参考以下文章
如何使用MaxCompute Spark读写阿里云Hbase