Spark读写HBase实践
Posted 北邮郭大宝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark读写HBase实践相关的知识,希望对你有一定的参考价值。
Spark经常会读写一些外部数据源,常见的有HDFS、HBase、JDBC、Redis、Kafka等。这些都是Spark的常见操作,做一个简单的Demo总结,方便后续开发查阅。
1. Maven依赖
需要引入Hadoop和HBase的相关依赖,版本信息根据实际情况确定。

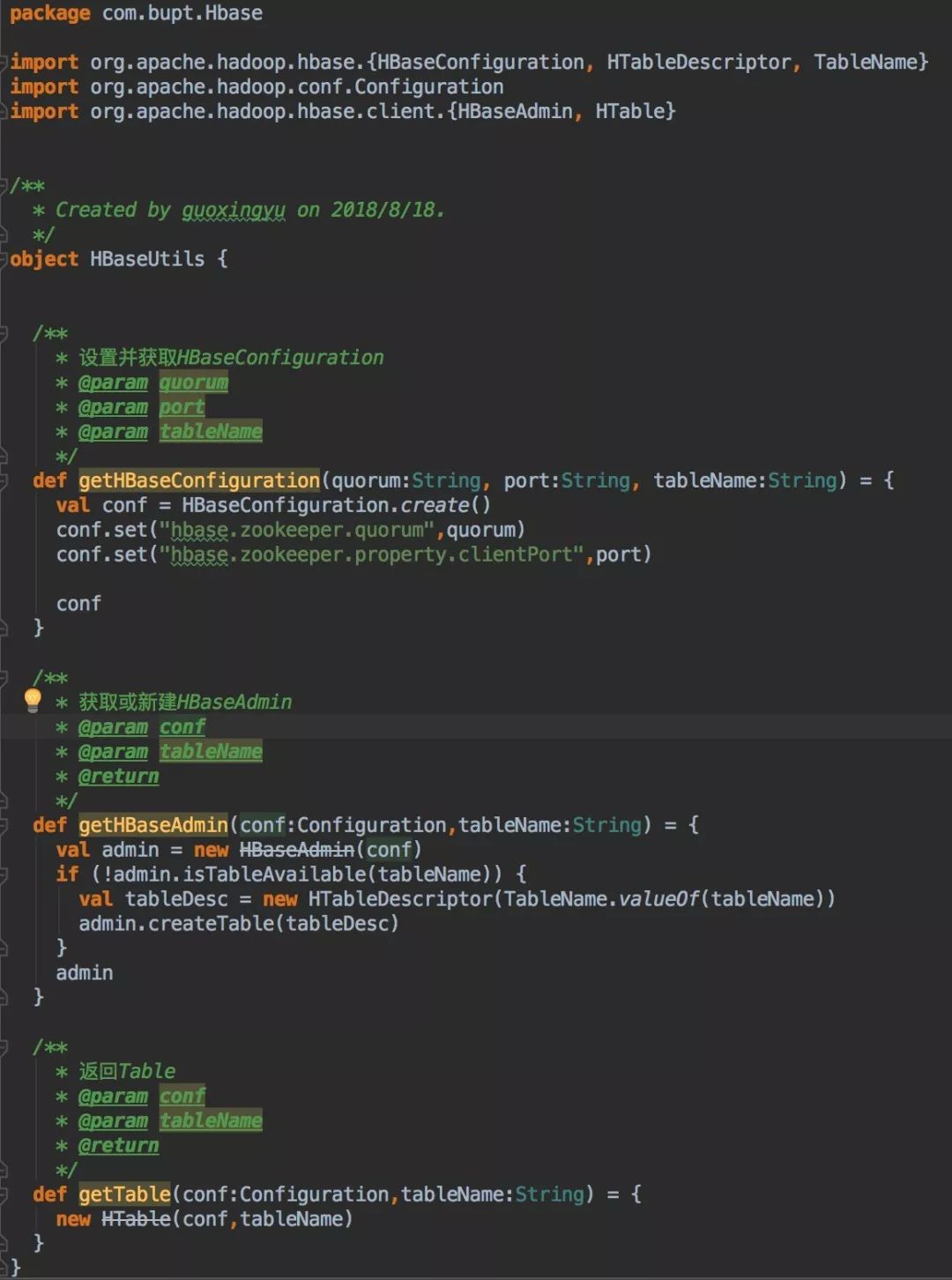
2. HBaseUtils
为了方便使用,需要写HBaseUtils类,完成一些基本信息的配置。比如完成Configuration、zookeeper的配置,返回HBaseAdmin和HTable等操作。
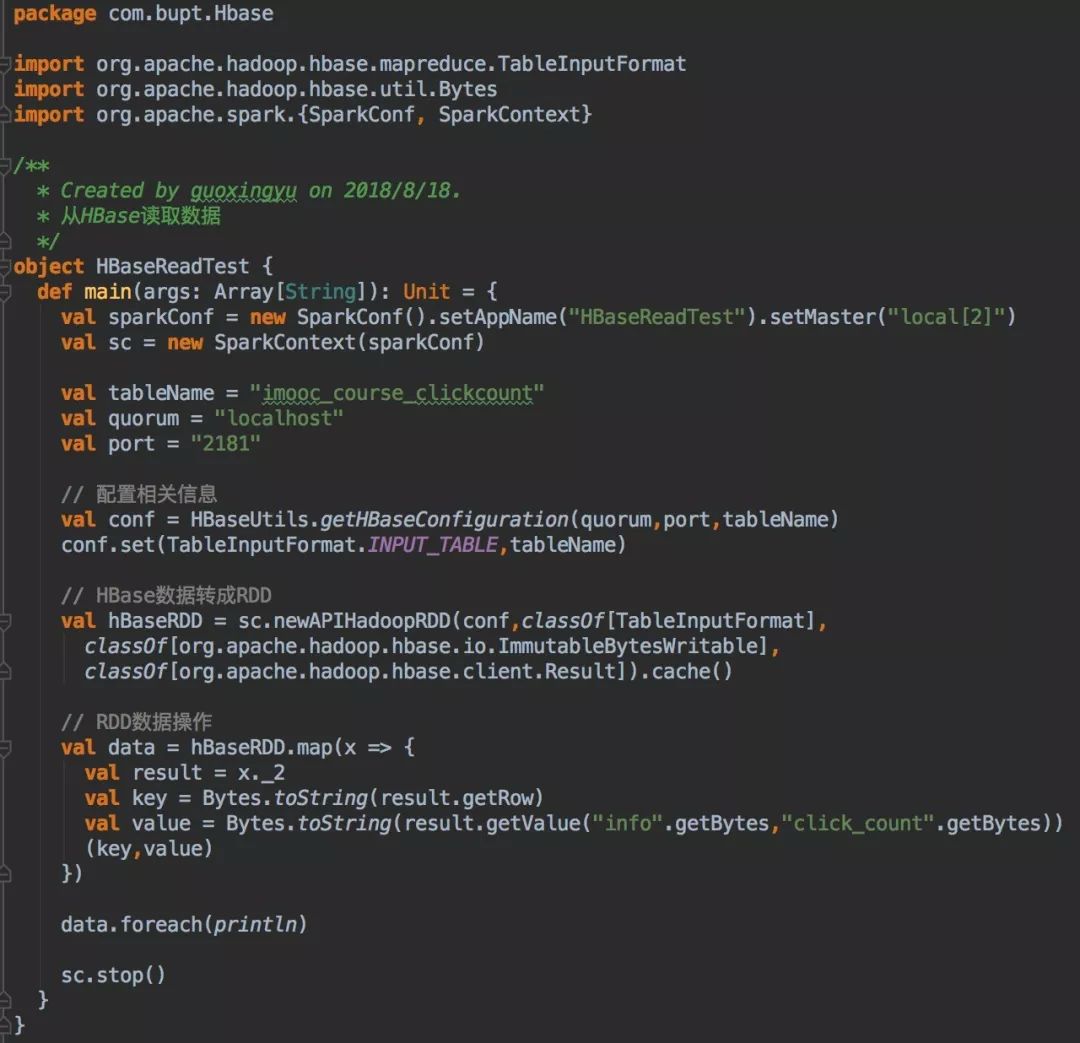
3. Spark读HBase
读取HBase数据可以通过TableInputFormat,newAPIHadoopRDD,把HBase表里的数据读出来,转变成RDD,再做后续处理。
4. Spark写HBase
Spark写HBase有三种方法,方法一是通过HTable中put方法一条一条插入数据到HBase;方法二是通过TableOutputFormat、saveAsHadoopDataset的API;方法三是通过bulkload将数据写入HFile再完成导入。根据网上的资料显示,方法三的效率会更高,所以推荐使用bulkload的方式。
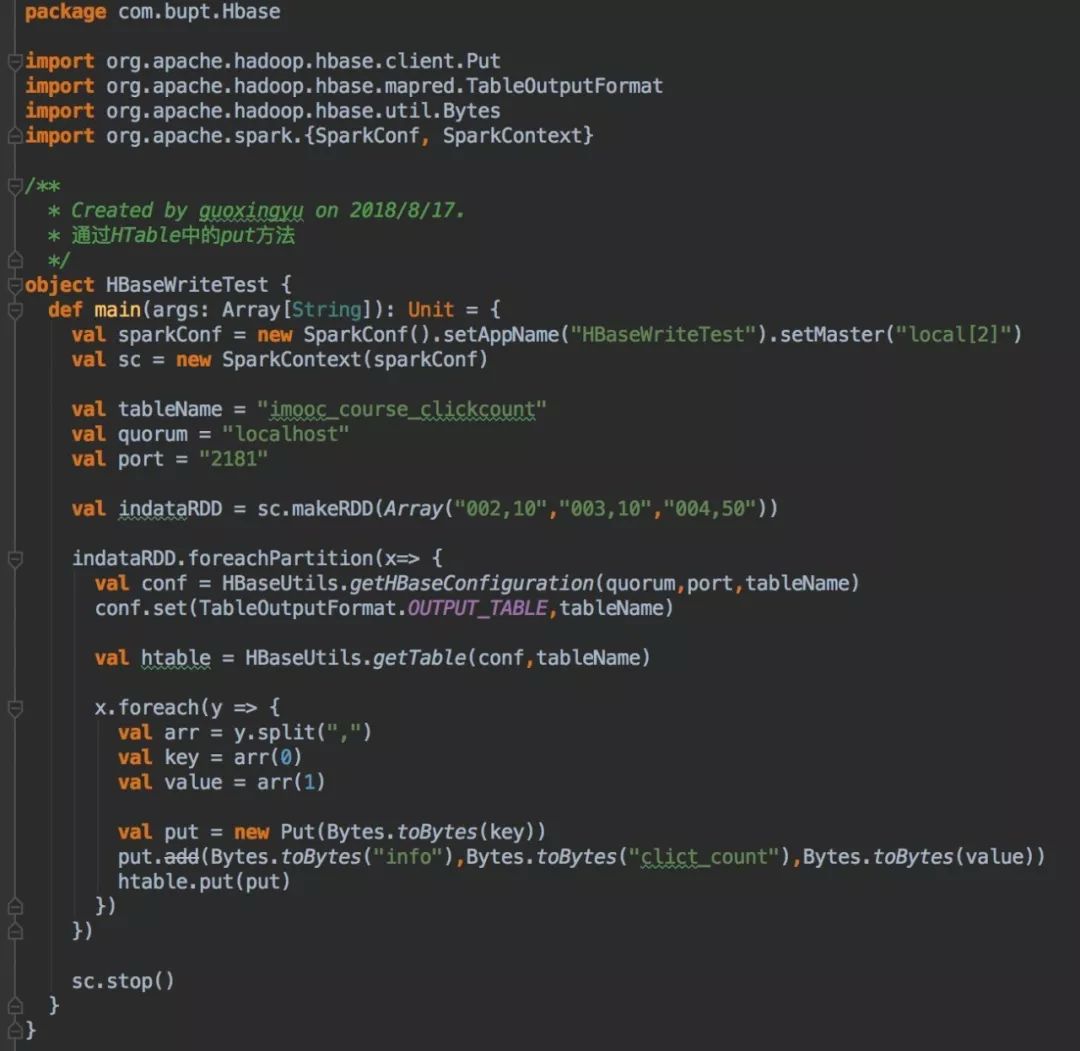
4.1 通过HTable中put方法
值得提醒的是,Spark在map,foreachPartition等算子内部使用了外部定义的变量和函数时,会引发Task未序列化问题。所以只能把配置信息放在foreachPartition中,效率很低。
4.2 通过TableOutputFormat
4.3 通过bulkload
这个方法的思路就是将数据RDD先生成HFiles,然后通过org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles将事先生成Hfiles批量导入到Hbase中。bulkload性能提高的原因可以参阅这篇文章https://www.iteblog.com/archives/1889.html
5. 参考
https://blog.csdn.net/qq_25954159/article/details/52848947?locationNum=12&fps=1
https://www.iteblog.com/archives/1891.html
https://www.iteblog.com/archives/1889.html
https://blog.csdn.net/gpwner/article/details/73530134
以上是关于Spark读写HBase实践的主要内容,如果未能解决你的问题,请参考以下文章