HBase原理 | 如何确保多步操作的事务性?HBase基础框架级特性Procedure解读
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase原理 | 如何确保多步操作的事务性?HBase基础框架级特性Procedure解读相关的知识,希望对你有一定的参考价值。
标题中提及"事务"可能会给大家带来误解,这篇文章不是在讨论HBase如何支持分布式事务能力的,而是介绍HBase用来处理内部事务操作的特性,这个特性被称之为Procedure V2,也是2.0版本的主打特性之一。
本文内容基于HBase 2.1版本,整体内容组织结构为:
1. Procedure特性的设计初衷。
2. Procedure的完整生命周期。
3. Procedure框架关键角色。
4. Procedure重点模块实现细节。
关于HBase基础原理系列文章:
介绍HBase的数据模型、适用场景、集群关键角色、建表流程以及所涉及的HBase基础概念。
介绍写数据的接口,RowKey定义,数据在客户端的组装,数据路由,打包分发,以及RegionServer侧将数据写入到Region中的全部流程。
阐述Flush与Compaction流程,讲述了Compaction所面临的本质问题,介绍了HBase现有的几种Compaction策略以及各自的适用场景。
首先介绍HBase的两种读取模式(Get与Scan),而后详细介绍Scan的详细实现流程。
详细介绍HBase底层数据文件格式HFile的实现细节。
关于Procedure V2介绍文章:
主要介绍Procedure V2的设计和结构,以及为什么用Procedure V2能比较容易实现出正确的AssignmentManager以及在2.1分支上对一些Procedure实现修正和改进。
以下是正文内容:
Procedure的设计初衷
我们先来看一下Procedure特性的设计初衷。以建表为例: 建表过程,包含如下几个关键的操作:
1.初始化所有的RegionInfos。
2.建表前的必要检查。
3.创建表的文件目录布局。
4.将Region写到Meta表中。
5. ......
从使用者看来,一个建表操作要么是成功的,要么是失败的,并不存在一种中间状态,因此,用"事务"来描述这种操作可以更容易理解。如果曾使用过1.0或更早的版本,相信一定曾被这个问题"折磨"过:“一个表明明没有创建成功,当使用者尝试再次重建的时候,却被告知该表已存在”,究其根因,在于建表遇到异常后,没有进行合理的Rollback操作,导致集群处于一种不一致的状态。
类似的需求,在HBase内部司空见惯:Disable/Enable表,修改表,RegionServer Failover处理,Snapshot, Assign Region, Flush Table...这些操作,都具备两个特点:多步操作,有限状态机(或简单或复杂)。因此,可以实现一个公共能力,这样可避免每个特性各自为营,导致大量难以维护的冗余代码。
最初版本的Procedure,由Online Snapshot特性引入(HBASE-7290),主要用来协调分布式请求。而最新版本的Procedure(称之为Procedure V2),受Accumulo的Fault-Tolerant Executor (FATE)的启发而重新设计,该特性已经在HBase内部得到广泛的应用,因此,可以将其称之为一个基础框架级特性,了解该特性的设计原理是学习2.x源码的基础。本文范畴内所探讨的Procedure,均指Procedure V2。
Procedure的生命周期
一个Procedure由一个或一系列操作构成。一个Procedure的执行结果,要么是成功,要么是失败,失败后不会让集群处于一种不一致的状态。
接下来,我们将以Create Table操作为例,来介绍一个Procedure的完整的生命周期。
创建
Master收到一个Create Table的请求后会创建一个CreateTableProcedure实例。
CreateTableProcedure涉及到一系列的操作,而每一个操作都关联了一个操作状态。在CreateTableState中,定义了与之相关的所有操作状态:
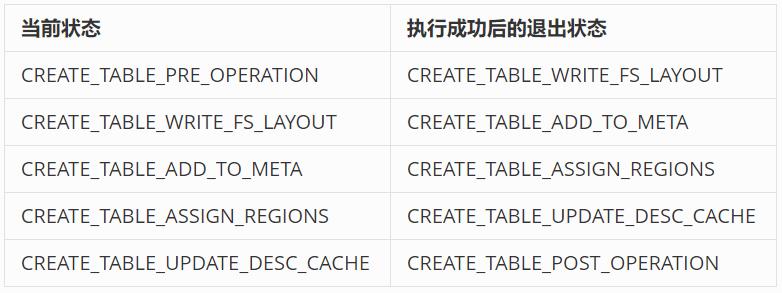
CreateTableProcedure内部定义了自身的初始状态为CREATE_TABLE_PRE_OPERATION,而且定义了每一种状态时对应的处理操作以及当前这个状态完成后应该要切换至哪个状态。如下表列出了当前状态与成功后的退出状态:
Procedure本身还有一个运行状态,这套运行状态的定义如下:

正是为了有所区分,本文将CreateTableProcedure内部定义的私有状态,称之为操作状态,而运行状态则是所有的Procedure都拥有的状态信息,从每一个状态的定义很容易看出它的作用。
提交
Master将创建出来的CreateTableProcedure实例,提交给ProcedureExecutor。
ProcedureExecutor关于一个新提交的Procedure,做如下几步处理:
1.必要检查(初始状态,确保无Parent Procedure,确保有Owner信息)。
2.设置Nonce Key(如果存在)以及Procedure ID。
3.将新的Procedure写入到ProcedureStore中,持久化。
4.将新的Procedure添加到ProcedureScheduler的调度队列的尾部。
运行
ProcedureExecutor初始化阶段,启动了若干个WorkerThread,具体数量可配置。
WorkerThread不断从ProcedureScheduler中poll出新的待执行的Procedure,而后:
1.获取IdLock: 获取Procedure关联的IdLock,避免同一个Procedure在多个线程中同时处理。
2.获取资源锁: 调用Procedure内部定义的Acquire Lock请求,获取Procedure自身所需的资源锁。
IdLock是为了确保一个Procedure只被一个线程调用,而这里的Lock是为了确保这一个Table只能被一个Procedure处理,这里需要获取Namespace的共享锁,以及当前这个Table的互斥锁,这里其实是一个分布式锁的需求,容易想到用ZooKeeper实现,事实上,这个Lock也可以用Procedure来实现,在后续章节中将会讲到这一点。
3.处理当前操作状态:执行Procedure初始状态所定义的处理逻辑,处理完后会返回当前这个Procedure对象。每一步运行完,都将最新的状态持久化到ProcedureStore中。
4.处理下一操作状态:如果返回对象依然是原来的Procedure,而且未失败,则意味着需要继续下一步处理。
5.循环处理:循环3,4步即可处理完所有CreateTableProcedure内部定义的所有处理。
释放锁资源。
完成
处理每一个操作状态时,都产生一个状态返回值(Flow),如果还有下一个待处理的状态,则返回Flow.HAS_MORE_STATE,如果全部执行完成,则返回Flow.NO_MORE_STATE,借此可以判断一个Procedure是否执行完成。一个执行成功后的Procedure,运行状态被设置为SUCCESS。
完成后的Procedure,需要在ProcedureStore中进行标记删除。
Procedure框架关键角色
通过上一章节的内容,我们已经知道了,在一个Procedure执行过程中,涉及到如下几个关键角色:
ProcedureExecutor
负责提交、执行Procedure。Procedure的执行操作,主要由其负责的多个WorkerThread来完成。
Procedure的持久化,由ProcedureExecutor提交给ProcedureStore。后续的每一次状态更新,也由ProcedureExecutor向ProcedureStore发起Update请求。
新的Procedure持久化后将被提交给ProcedureScheduler,由ProcedureScheduler完成调度。ProcedureExecutor中的WorkerThread从ProcedureScheduler中获取待执行的Procedure。
ProcedureStore
用来持久化新提交的Procedure以及后续的每一次状态更新值。
ProcedureStore的默认实现类为WALProcedureStore,基于日志文件来持久化Procedure信息,虽然称之为WAL,但与HBase自身的WAL日志文件的实现完全不同,类似点在于:
当超过一定大小后或者超过一定的时间周期后,需要roll一个新的WAL文件出来,避免一个WAL文件过大。
需要实现一套关于无用WAL日志文件的跟踪清理机制,避免WAL文件占用过大的存储空间。
实现了一套类似于RingBuffer的机制,通过打包sync并发的写入请求,来提升写入吞吐量。
ProcedureScheduler
负责调度一个集群内的各种类型的Procedure请求,支持按优先级调度,相同优先级的Procedure则支持公平调度。
我们先来看看Procedure的几大类型:
Meta Procedure:唯一的一种类型为RecoverMetaProcedure,该类型已被废弃。
Server Procedure:目前也只有一种类型:ServerCrashProcedure,用来负责RegionServer进程故障后的处理。
Peer Procedure:与Replication相关,如AddPeerProcedure, RemovePeerProcedure等等。
Table Procedure: Table Procedure的类型最为丰富,如CreateTableProcedure, DisableTableProcedure, EnableTableProcedure, AssignProcedure, SplitTableRegionProcedure,.....涵盖表级别、Region级别的各类操作。
在ProcedureScheduler中,需要同时调度这几种类型的Procedure,调度的优先级顺序(由高到低)为:
Meta -> Server -> Peer -> Table。
在每一种类型内部,又有内部的优先级定义。以Table Procedure为例,Meta Table的优先级最高,System Table(如acl表)其次,普通用户表的优先级最低。
重点模块实现细节
看到这里,你也许会认为,"Procedure特性原来如此简单!",但如果仔细阅读这部分代码,就会深刻体会到它在实现上的复杂度,导致这种复杂度的客观原因总结起来有如下几点:
1.要实现一个统一的状态机管理框架本身就比较复杂,可以说将Assign Region/Create Table/Split Region等流程的复杂度转嫁了过来。
2.需要支持优先级调度与公平调度。
3.WALProcedureStore无用WAL文件的跟踪与清理,重启后的回放,均需要严谨的处理。
4.涉及复杂的拓扑结构:一个Procedure中间运行过程可能会产生多个Sub-Procedures,这过程需要协调。
5.不依赖于ZooKeeper的分布式锁机制。
6.跨节点Rpc请求协调。
在实际实现中,还内部维护几个私有的数据结构,如Avl-Tree, FairQueue以及Bitmap,这也是导致实现复杂度过高的一大原因。接下来选择了三点内容来展开讲解,这三点内容也算是Procedure框架里的难点部分,分别为:WAL清理机制,Procedure调度策略以及分布式锁与事件通知机制。
WAL清理机制
WALProcedureStore也存在WAL日志文件的roll机制,这样就会产生多个WAL文件。对于一个旧的WAL文件,如何认定它可以被安全清理了?这就需要在WALProcedureStore中设计一个合理的关于Procedure状态的更新机制。
WALProcedureStore使用ProcedureStoreTracker对象来跟踪Procedure的写入/更新与删除操作,这个对象被称之为storeTracker。
在ProcedureStoreTracker中,只需要用ProcID(long类型)来表示一个Procedure。即使只记录大量的ProcIDs,也会占用大量的内存空间,因此,在ProcedureStoreTracker内部实现了一个简单的Bitmap,用一个BIT来表示一个ProcID,这个Bitmap采用了分区、弹性扩展的设计:每一个分区称之为一个BitsetNode,每一个BitsetNode有一个起始值(Start),使用一个long数组来表示这个分区对应的Bitmap,每一个long数值包含64位,因此可以用来表示64个ProcIDs。一个BitsetNode应该可以包含X个long数值,这样就可以表示从Start值开始的X * 64个ProcIDs,但可惜,现在的代码实现还是存在问题的(应该是BUG),导致一个BitsetNode只能包含1个long值。
如果了解过Java Bitset的原理,或者是RoaringBitmap,就会发现这个实现并无任何新颖之处。
在一个BitsetNode内部,其实包含两个Bitmap: 一个Bitmap(modified)用来记录Insert/Update的ProcIDs,另一个Bitmap(Deleted)用来记录已经被Delete的ProcIDs。例如,如果Proc Y在Bitmap(modified)所对应的BIT为1,在Bitmap(Deleted)中所对应的BIT为0,则意味着这个Procedure仍然存活(或许刚刚被写入,或许刚刚被更新)。如果在Bitmap(Modified)中对应的BIT为1,但在Bitmap(Deleted)中所对应的BIT为1,则意味着这个Procedure已被删除了。
如果一个旧的WAL文件所关联的所有的Procedures,都已经被更新过(每一次更新,意味着Procedure的状态已经发生变化,则旧日志记录则已失去意义),或者都已经被删除,则这个WAL文件就可以被删除了。在实现上,同样可以用另外一个ProcedureStoreTracker对象(称之为holdingCleanupTracker)来跟踪最老的WAL中的Procedure的状态,每当有新的Procedure发生更新或者被删除,都同步删除holdingCleanupTracker中对应的ProcID即可。当然,还得考虑另外一种情形,如果有个别Procedure迟迟未更新如何处理? 这时,只要强制触发这些Procedures的更新操作即可。
这样描述起来似乎很简单,但这里却容易出错,而且一旦出错,可能会导致WAL日志被误删,或者堆积大量的日志文件无法被清理,出现这样的问题都是致命的。
Procedure调度策略
关于调度策略的基础需求,可以简单被表述为:
1.不同类型的Procedure优先级不同,如Server Procedure要优先于Table Procedure被调度。
2.即使同为Table Procedure类型,也需要按照Table的类型进行优先级调度,对于相同的优先级类型,则采用公平调度策略。
MasterProcedureScheduler是默认的ProcedureScheduler实现,接下来,我们看一下它的内部实现。
MasterProcedureScheduler将同一类型的Procedure,放在一个被称之为FairQueue的队列中,这样,共有四种类型的FairQueue队列,这四个队列分别被称之为MetaRunQueue, ServerRunQueue, PeerRunQueue, TableRunQueue),在调度时,按照上述罗列的顺序进行调度,这样,就确保了不同类型间的整体调度顺序。
简单起见,我们假设这四个队列中,仅有TableRunQueue有数据,其它皆空,这样确保会调度到TableRunQueue中的Procedure。在TableRunQueue中,本身会涉及多个Table,而每一个Table也可能会涉及多个Procedures:
TableA -> {ProcA1, ProcA2, ProcA3}
TableB -> {ProcB1, ProcB2, ProcB3, ProcB4, ProcB5}
TableC -> {ProcC1, ProcC2, ProcC3, ProcC4}
每一个Table以及所涉及到的Procedure列表,被封装成了一个TableQueue对象,在TableQueue中,使用了一个双向队列(Deque)来存储Procedures列表,Deque的特点是既可以在队列两端进行插入。在这个Deque中的顺序,直接决定了同一个Table的Procedures之间的调度顺序。
当需要为TableB写入一个新的Procedure时,需要首先快速获取TableB所关联的TableQueue对象,常见的思路是将所有的TableQueue存储在一个ConcurrentHashMap中,以TableName为Key,然而,这里却没有采用ConcurrentHashMap,而是实现了一个Avl-Tree(自动平衡二叉树),这样设计的考虑点为:ConcurrentHashMap中的写入会创建额外的Tree Node对象,当对象的写入与删除非常频繁时对于GC的压力较大(请参考AvlUtil.java)。Avl-Tree利于快速获取检索,但写入性能却慢于红黑树,因为涉及到过多的翻转操作。这样,基于TableName,可以快速从这个Avl-Tree中获取对应的TableQueue对象,而后就可以将这个新的Procedure写入到这个TableQueue的Deque中,写入时还可以指定写入到头部还是尾端。
现在我们已经了解了TableQueue对象,而且知道了多个TableQueue被存储在了一个类似于Map的数据结构中,还有一个关键问题没有解决:如何实现不同Table间的调度?
所有的TableQueue,都存放在TableRunQueue(再强调一下,这是一个FairQueue对象)中,而且按Table的优先级顺序组织。每当有一个新的TableQueue对象产生时,都会按照该TableQueue所关联的Table的优先级,插入到TableRunQueue中的合适位置。
当从这个TableRunQueue中poll一个新的TableQueue时,高优先级的TableQueue先被poll出来。如果被poll出来的TableQueue为普通优先级(priority值为1),为了维持公平调度的原则,在TabelRunQueue中将这个TableQueue从头部移到尾部,这样下一次将会调度到其它的TableQueue。
再简单总结一下:TableQueue对象用来描述一个Table所关联的Procedures队列,TableQueue对象存在于两个数据结构中,一个为Avl-Tree,这样可以基于TableName快速获取对应的TableQueue,以便快速写入;另一个数据结构为FairQueue,这是为了实现多Table间的调度。
分布式锁与事件通知机制
同样围绕Create Table的例子,说明一下关于分布式锁的需求:
两个相同表的CreateTableProcedure不应该被同时执行
同一个Namespace下的多个不同表的CreateTableProcedure允许被同时执行
只要存在未完成的CreateTableProcedure,所关联的Namespace不允许被删除
实现上述需求,Procedure框架采用了共享锁/互斥锁方案:
当CreateTableProcedure执行时,需要获取对应Namespace的共享锁,以及所要创建的Table的互斥锁。
删除一个Namespace则需要获取这个Namespace的互斥锁,这意味着只要有一个Procedure持有该Namespace的共享锁,则无法被删除。
当一个Procedure X试图去获取一个Table的互斥锁时,碰巧该Table的互斥锁被其它Procedure持有,此时,Procedure X需要加到这个Table的锁的等待队列中,一旦该锁被释放,Procedure X需要被唤醒。
回顾一下Procedure的执行过程:
Acquire Lock
Execute
获取锁资源的操作,只需要在"Acquire Lock"步骤完成即可。
在MasterProcedureScheduler中,使用一个SchemaLocking的对象来维护所有的锁资源,如Server Lock, Namespace Lock,Table Lock等等。以Table Lock资源为例:一个Table的锁资源,使用一个LockAndQueue对象进行抽象,顾名思义,在这个对象中,既有Lock,又有关于这个锁资源的Procedure等待队列;多个Table的LockAndQueue对象被组织在一个Map中,以TableName为Key。
同时,还可以将获取锁资源的操作封装成一个Procedure,称之为LockProcedure,以供Procedure框架之外的特性使用,如TakeSnapshotHandler,可以利用该机制来获取Table的互斥锁。
Procedure框架就是这样没有依赖于ZooKeeper,实现自身的分布式锁与消息通知机制。
总结
本文先从Procedure的设计初衷着手,而后以Create Table为例介绍了一个Procedure的生命周期,通过这个过程,可以简单了解整个框架所涉及到的几个角色,因此,在接下来的章节中,进一步细化Procedure框架中的几个角色。最后一部分,选择整个框架中比较复杂的几个模块,展开实现细节。受限于篇幅,有几部分内容未涉及到:
WAL数据格式与WAL回放机制
Notification-Bus(当然这部分也只实现了一小部分)
复杂Procedure拓扑结构情形
Procedure超时处理
作为应用Procedure框架的最典型流程Region Assignment,在此文范畴内几乎未涉及。因为关于Region Assignment的故事太精彩,又太揪心,所以会放在一篇独立的文章中专门讲解。
参考信息
http://hbase.apache.org/book.html#pv2
http://hbase.apache.org/book.html#amv2
HBASE-13439: Procedure Framework(Pv2)
Accumulo FATE
HBASE-13203 Procedure v2 - master create/delete table
HBASE-14837: Procedure Queue Improvement
HBASE-20828: Finish-up AMv2 Design/List of Tenets/Specification of operation
HBASE-20338: WALProcedureStore#recoverLease() should have fixed sleeps for retrying rollWriter()
HBASE-21354: Procedure may be deleted improperly during master restarts resulting in "corrupt"
HBASE-20973: ArrayIndexOutOfBoundsException when rolling back procedure...
HBASE-19756: Master NPE during completed failed eviction
HBASE-19953: Avoid calling post* hook when procedure fails
HBASE-19996: Some nonce procs might not be cleaned up(follow up HBASE-19756)

NoSQL主要泛指一些分布式的非关系型数据存储技术,这其实是一个非常广泛的定义,可以说涉及到分布式系统技术的方方面面。随着人工智能、物联网、大数据、云计算以及区块链技术的不断普及,NoSQL技术将会发挥越来越大的价值。
以上是关于HBase原理 | 如何确保多步操作的事务性?HBase基础框架级特性Procedure解读的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据HBase(十四):HBase的原理及其相关的工作机制