深入Hbase原理(超详细)
Posted Hadoop大数据开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入Hbase原理(超详细)相关的知识,希望对你有一定的参考价值。
目录
前言
Hbase概述
Hbase中的核心概念
原理加强之Region拆分
HMaster的作用 主节点
Region的拆分
负载均衡
1.1 自动负载均衡流程
1.2 强制执行负载均衡
1.3 人为的移动
大小合并
大合并之Region合并
小合并之Hfile的合并
Hbase的数据导入
shell端脚本方式
使用步骤
Java程序方式
MR程序读取数据处理 并输出到Hbase中
前言
Hbase概述
我们都知道,Hbase是一个高可靠的、易扩展的、面向列式存储的分布式数据库系统,那既然是一款数据库管理系统,当然,它的数据借助于HDFS存储。具体路径为/hbase/data/default/table_name/region_name/cf_name/hfile
Hbase中的核心概念
region
1)表的行数据范围,将一张大的表划分成多个region,将region分配给不同的regionserver机器管理-------->构成分布式数据库
2)region中有
store:一个列族对应一个store
memorystore :读写数据的内存 写数据(内存)---->对整个file中的数据进行排序
WALG:记录用户的操作行为 在进行写入数据时,若机器意外宕机时恢复用户数据的一种方式
storefile:内存对象flush到hdfs中形成hfile文件;storefile就是hfile的抽象对象
blockCache:提升查询的效率
其他名词概念
namespace:名称空间,类似于mysql中的数据库名
表 namespace:table_name
列族 columanFamily简称cf:对列的分类管理 创建表时要注意 1)列族不要太多(太多意味着更多的memorystore内存对象,占用更多的内存) 2)命令不要太长(储存的时候数据过长 冗余)
行键 rowkey:1)行的唯一标识 2)索引 3)一维排序 4)布隆过滤器
属性 qualifier :具有稀疏性
值 value:存储的字节数据
原理加强之Region拆分
HMaster的作用 主节点
1)DDL有关的操作,比如建表需要master主节点 ;而读写数据却不需要master,从hbase读写数据的流程来看,确实没有接触到master
2)region具体分配到哪个regionserver上需要matser
Region的拆分
为什么要拆分region?
HBase是以表的形式存储数据的。一张表被划分为多个regions,regions分布在多个Region Server上,单个region只能分布在一个Region Server节点上,不能跨Region Server存放。
Region的两个重要属性:StartKey和EndKey,分别表示这个region所维护的rowkey范围。当做读/写请求时,寻址到该数据的rowkey落在某个start-end key范围内,那么就会定位到该范围内的region所在的Region Server上进行数据读/写。
随着数据的增多,region所要管理的数据也会越来越多,查询时,出现高并发热点问题的概率大大增加。单个机器需要来处理很多数据,并且当这个regionserver的负载过重。
这个时候就需要对region进行拆分,均衡到不同的节点上进行管理!
热点问题
在创建表的时候建议 使用预分region表 (指定了切割点 ,对数据有分组规划)
1. 观察数据特点 注意重点字段(业务)
2 了解具体的表对应的业务,重点字段
3 根据业务 判断数据的读多(查询) 写多(插入)
4 读数据 写数据 (特点) 维度
5 避免热点问题 [插入热点 , 查询热点]
138...大量的数据插入到同一个region 一个regionserver在服务 压力过大
并发的查询138...数据 一个regionserver在服务 接收所有的并发查询
怎么拆分?
1)自动拆分
1.1默认按照大小
计算公式为:
Min{1^3*2*128M 256M
2^3*2*128M 2G
3^3*2*128M 6.75G
10G 10G
当hbase表在regionserver上的region,如果region的大小到达一个阈值,这个region将会分为两个。
如果默认值情况下,一个表在一个regionserver上split的阈值是:
256MB(第一次split),2GB(第二次),6.75GB(第三次),10GB(第四次),10GB... 10GB1.2keyPrefixRegionSplitPolicy(自定义) key的前缀
这种拆分是在原来的拆分基础上 ,增加了拆分点(splitPoint,拆分点就是Region被拆分时候的rowkey)的定义,保证有相同前缀的rowkey不会被拆分到不同的Region上
参数是 keyPrefixRegionSplitPolicy.prefix_length rowkey:前缀长度
问题是 : 可能相同主题的数据会被分到不同的regionserver中 ,查询数据来源于不同的regionserver
1.3DelimitedKeyPrefixRegionSplitPolicy key的分隔符
和上一种查分策略一致 , 上一种是按照key的固定长度拆分的 , 这种按照的是分割符
DelimitedKeyPrefixRegionSplitPolicy.delimiter参数分割符
指定一个分隔符 能保证相同的主题数据在一个regionserver中
2)手动拆分(很少用,不需要)
Examples:split 'tableName'split 'namespace:tableName'split 'regionName' # format: 'tableName,startKey,id'split 'tableName', 'splitKey'split 'regionName', 'splitKey'
3)预分region
shell端:
hbase> create 'ns1:t1', 'f1', SPLITS => ['10', '20', '30', '40']hbase> create 't1', 'f1', SPLITS => ['10', '20', '30', '40']
java客户端:
byte[][] keys = new byte[][]{"e".getBytes(), "m".getBytes(), "t".getBytes()};// 建表 指定预分region的key(数组)admin.createTable(tableDescriptor, keys);
一般在实际业务中,首先会根据数据量和集群的规模还有业务特点,会进行预分区region,之后按照默认的拆分规则自动拆分即可。
可以设置拆分的策略 1)大小拆分 2)按照前缀拆分 3)按照分隔符拆分 4)手动拆分(几乎很少用)
region在底层是文件夹。
拆分之后
region拆分之后,面临的将是负载均衡或(region的移动)
region的移动会非常非常占用资源;因为region的移动会牵扯到文件、文件夹的创建、hfile的移动。
会消耗大量的IO、网络、CPU资源被占用,最好不要手动频繁的去拆分。
拆分带来的好处:将一个大的表拆分成多个region区域,交由不同的regionserver管理,形成分布式数据库,减少了某一个机器的的负载压力。
负载均衡
由Master的LoadBalancer线程周期性的在各个RegionServer间移动region维护负载均衡。
1 经常被并发查询的数据不要存储在同一个RegionServer中 , 避免热点读取问题 .
2 当一个机器上经过大量的插入或者删除数据以后 ,region合并或者分裂 ,那么机器上的region的数量会相差很大 .
3 当新增了节点以后 , 应该去分配一些其他机器上的region数据
4 当某个RegionServer宕机以后 , 这台机器上数据的分配
region的执行
Hbase中负载均衡的开关balanceSwitch默认是开启的 .
hbase.balancer.period是设定负载均衡的参数,默认为每5分钟(300000毫秒)运行一次,参数配置通过hbase-site.xml文件。具体的设置格式如下:
<property>
<name>hbase.balancer.period</name>
<value>300000</value>
</property>
1.1 自动负载均衡流程
1)两个有效参数:MIN = floor(average)(表示下限)和MAX=ceil(average)(表示上限)。
2)循环过载机器,将Region卸载到MAX数量,在小于等于MAX时停止排序Region(按时间新旧)。
3)遍历最轻负载机器,分配Region直到Server达到MIN值。在大于等于MIN时停止。这些Region都是之前卸载的。可能没有足够地卸载Region让轻负载的机器达到MIN值,如果这样,在Region数等于neededRegions(轻负载机器的数量)时停止。可能我们分配了卸载的Region到轻负载机器,但是仍然有Region没有分配出去,这种情况下,本步骤完成,在下面步骤中再做处理。
4)如果neededRegions是非零的值,遍历负载最重的机器,从每台机器上卸载一个Region,使得它们的值从MAX到MIN。
5)现在有很多Region等待分配,遍历最轻的负载机器(多台),分配Region到MIN。
6)如果仍然有Region没有分配,遍历最轻的负载机器(多台),这次分配Region到MAX。
7)所有Server的Region数量时MAX或者MIN,另外,所有大于等于MAX的Server保证在均衡完成后都是MAX个Region。从而保证Region移动的最小数量。
其中,轻负载指的是Region数量小于等于AVG,过载指大于等于AVG,所有的RegionServer都按照负载从大到小排序,存放在TreeMap中(保证先遍历过载Server)。
1.2 强制执行负载均衡
1)kill 掉不是Hmaster节点的 regionserver(slave2)
2) hbase 16010 查看regionserver在slave2节点
3) 在master节点启动 regionserver(slave2)
master $>hbase-daemons.sh start regionserver
4) hbase 16010 查看regionserver负载不均衡 (多刷新 0 6)
balance负载均衡指令,需使用开关模式,原因负载均衡比较耗费资源:
hbase(main):005:0> balance_switch true //开启负载均衡
hbase(main):005:0> balancer //执行负载均衡
hbase(main):005:0> balance_switch false //关闭负载均衡
hbase(main):005:0> balancer "force" //强制负载均衡
1.3 人为的移动
当发生经常性的查询热点问题时, 您的请求总是请求到一个服务节点上 ,我们可以把这个机器中的数据理解成热数据 ,可以人为的拆分以后手动的移动到不同的机器上 实现查询热点的负载均衡
使用命令
1 切分
Examples:
split 'tableName'
split 'namespace:tableName'
split 'regionName' # format: 'tableName,startKey,id'
split 'tableName', 'splitKey'
split 'regionName', 'splitKey'
页面查看region情况 ,或者使用list_regions "tb_name"
2 移动 将某个region移动到某个机器上
move "a84afc7eb10797188c0af1534e143eb9" , "linux03,16020,1591844369905"
大小合并
大合并之Region合并
为什么需要合并region呢?
当一个Region被不断的写数据,达到Region的Split的阀值时(由属性hbase.hregion.max.filesize来决定,默认是10GB),该Region就会被Split成2个新的Region。随着业务数据量的不断增加,Region不断的执行Split,那么Region的个数也会越来越多。
一个表的Region过大,势必整个集群的Region个数也会增加,负载均衡后,每个RegionServer承担的Region个数也会增加
当表中的数据被大量删除以后,表的行数急剧减少,region的个数没有变。region的个数没有变,每个region管理的数据行数少!合并region
当然合并region也是占用大量的IO、网络、cpu资源的。
小合并之Hfile的合并
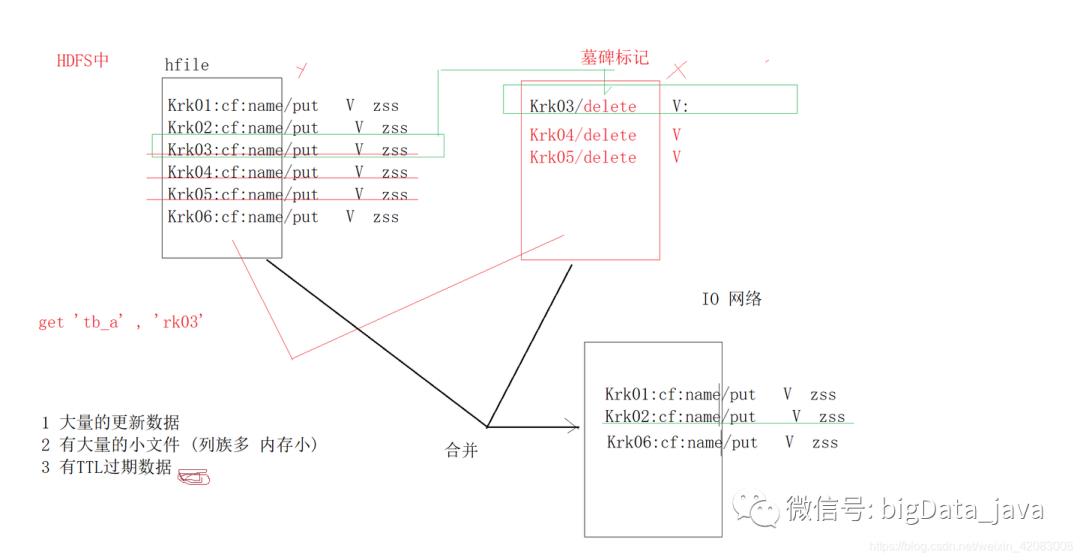
hbase是分布式列式存储数据库 , 其具有的基本功能就是对数据的增删改查 , 那么Hbase的数据是存储在HDFS上的,我们知道在HDFS中的数据是不允许随机修改和删除的!这与HDFS的功能相违背!
hbase数据底层存储下HDFS系统中--------Hfile的形式存储的!在HDFS中Hfile的具体位置 /hbase/data/default/table_name/region_name/cf_name/hfile_name 如下图所示
hfile合并
数据加载到memstore,数据越来越多直到memstore占满,再写入硬盘storefile中,每次写入形成一个单独Hfile,当Hfile达到一定的数量后,就会开始把小Hfile合并成大Hfile,因为Hadoop不擅长处理小文件,文件越大性能越好。
hfile合并的时机
1)有大量的更新数据 (修改、删除 操作)
hfile在进行修改数据或者删除数据时,并不是真的删掉了这条数据,而是重新生成一个hfile,将数据放入其中,并打上标记。比如删除rk001 的数据,会
新生成file文件,里面存有rk001 并带有墓碑标记的数据 客户端在拿数据时,服务器找到了两条rk001 一看有墓碑标记,就不再将此条数据读出返回给客户端
2)有大量的小文件
设计的不好,rowkey多,大量的冗余数据,列族多,store多,memorystore多,占用内存过多,容易溢出,会使机器的内存占用达到阈值,就会flush掉所有的memorystore中的数据,从而产生大量的
storefile进而产生很多很多的hfile(列族多,内存小)
3)有TTL过期数据
数据大量删除------>hfile新生-------->hifle合并-------->region管理数据行数变少-------->region合并
region的合并不要在业务高峰进行
面试题:
hbase表中的数据存储在哪?
hbase中的数据物理存储在hdfs上。
hdfs中的数据不是不允许随机修改和删除吗,你刚刚说hbase上的数据存储在hdfs上的,hbase既然是个数据库管理系统,那肯定有crud的功能吧,那这怎么解释呢?
hdfs上的数据的确是不允许进行随机修改和删除的,而habse中的数据修改和删除也不是直接就修改和删掉了的,是通过数据的标记和文件的合并来实现修改和删除的
比如,hbase数据的删除,对数据的删除,实际上生成了一个新的hfile,并给数据打上墓碑标记
查询数据时,看到墓碑标记,就不会读取这条数据并返回
等到一定条件,hfile合并之后,数据才会消失。
Hbase的数据导入
1)put 不好 直接将数据导入到Hbase中 , 底层使用RPC请求 , 每次put都会RPC请求,效率并不高
一行插入一次 进行一次RPC请求
* ------------------>hbase
* ------------------>hbase
* ------------------>hbase
* ------------------>hbase用rpc请求,一条一条地通过rpc提交给regionserver去插入,效率极其低下!
Table tb_dml = conn.getTable(TableName.valueOf("tb_dml"));Put rk0011 = new Put(Bytes.toBytes("rk0011"));rk0011.addColumn("cf1".getBytes(), "name".getBytes(), "guanyu".getBytes());rk0011.addColumn("cf1".getBytes(), "gender".getBytes(), "M".getBytes());Put rk0010 = new Put(Bytes.toBytes("rk0010"));rk0010.addColumn("cf1".getBytes(), "age".getBytes(), Bytes.toBytes(23));rk0010.addColumn("cf1".getBytes(), "name".getBytes(), "guanyu".getBytes());// 插入多行数据ArrayList<Put> puts = new ArrayList<>();puts.add(rk0011);puts.add(rk0010);// 插入数据tb_dml.put(puts);
2)BufferedMutator
使用缓存批次的形式发送RPC请求 , 减少RPC的请求次数 , 插入数据的效率会比put方式效率高, 但是对于大量的静态数据也并不适合!
private static void mutationInsert() throws IOException {Connection conn = HbaseUtils.getHbaseConnection();BufferedMutator mutator = conn.getBufferedMutator(TableName.valueOf("tb_user"));Put put = new Put(Bytes.toBytes("rk1005")); // 行键put.addColumn(Bytes.toBytes("cf1"),// 列族Bytes.toBytes("name"),//属性Bytes.toBytes("OOO") //值);put.addColumn("cf1".getBytes(), "gender".getBytes(), "M".getBytes());// 插入数据mutator.mutate(put);// 将缓存在本地的数据 请求Hbase插入mutator.flush();}
3) BulkLoad
数据插入到hbase中的本质:将数据以Hfile文件格式存储在HDFS的指定位置
*** 将大量的静态数据转换成hfile文件 直接存储到指定的hdfs路径下 批量导入***
使用工具:bulkloader 一个用于批最快速导入数据到 hbase 的工具/方法
应用场景:用于已经存在一批巨量的静态数据的情况!
简介:使用 Bulk Load方式由于利用了HBase 的数据信息是按照特定格式存储在HDFS里的这一特性,直接在 HDFS中生成持久化的 HFile数据格式文件,然后完成巨量数据快速入库的操作,配合MapReduce完成这样的操作,不占用 Region资源,不会产生巨量的写入IO,所以需要较少的CPU和网络资源。Bulk Load 的实现原理是通过一个MapReduce Job来实现的,通过Job直接生成一个HBase的 HFile格式文件,用来形成一个特殊的 HBase数据表,然后直接将数据文件加载到运行的集群中。与使用Hbase API相比,使用Bulkload导入数据占用更少的CPU和网络资源。
3.1shell端脚本方式
使用shell脚本,可以完成。该方法操作方便,但不够灵活。
使用步骤
静态数据如下:
uid001,zss,23,F
uid002,lss,13,M
uid003,ww,22,M
uid004,zl,34,F
uid005,tq,43,M
uid006,wb,55,F
uid007,sj,98,M1先在linux01上新建txt,并上传到hdfs上
2在hbase创建一张表 create ‘test_data’,'cf1'
3执行命令 根据数据生成hbase文件
#info:列族名 name:属性 imp:表名 /tsv/input:输入路径 /tsv/output:输出路径
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dmporttsv.separator=, -Dimporttsv.columns='HBASE_ROW_KEY,cf1:name,cf1:age,cf1:gender' -Dimporttsv.bulk.output=/tsv/output imp /tsv/input
命令解释: -Dimporttsv.separator=, 指定文件分割符号 为 ,
Dimporttsv.columns='HBASE_ROW_KEY,cf1:name,cf1:age,cf1:gender 分割的行键 列族:属性
/tsv/input:输入路径 /tsv/output:输出路径
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=, -Dimporttsv.columns='HBASE_ROW_KEY,cf1:name,cf1:age,cf1:gender' -Dimporttsv.bulk.output=/tsv/output test_data /data
4查看页面上文件夹显示
此时是还没有hfile的
5将生成的hfile文件导入到hbase表中
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /tsv/output test_data
执行后,查看页面文件
6解析验证是否导入的静态数据文件
hbase hfile -p -f 文件在hdfs中的路径 或者使用scan 'test_data'



3.2Java程序方式
使用Mr程序的自定义输入和输出文件类型
输入Hfile文件 输出普通的文件 表-->普通文件(数据导出)
输入Hfile文件 输出Hfile文件 表-->表
输入普通文件 输出Hflie 将普通数据导入到Hbase中
*** 将普通的数据 (大量) ----> hfile格式的数据 [MR]
[MR]:自定义输入和输出[hfile] --> 指定路径
编写java程序 mapper读数据 处理 reducer 写数据 灵活,但需要另写代码
MR程序读取数据处理 并输出到Hbase中MovieBean代码:package cn._51doit.movie;import org.apache.hadoop.io.Writable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;/***/public class MovieBean implements Writable {private String movie ;private double rate ;private String timeStamp ;private String uid ;public String getMovie() {return movie;}public void setMovie(String movie) {this.movie = movie;}public double getRate() {return rate;}public void setRate(double rate) {this.rate = rate;}public String getTimeStamp() {return timeStamp;}public void setTimeStamp(String timeStamp) {this.timeStamp = timeStamp;}public String getUid() {return uid;}public void setUid(String uid) {this.uid = uid;}public void write(DataOutput dataOutput) throws IOException {dataOutput.writeUTF(movie);dataOutput.writeDouble(rate);dataOutput.writeUTF(timeStamp);dataOutput.writeUTF(uid);}public void readFields(DataInput dataInput) throws IOException {this.movie = dataInput.readUTF();this.rate = dataInput.readDouble() ;this.timeStamp = dataInput.readUTF();this.uid = dataInput.readUTF();}}
MR程序:
package cn._51doit.mr;import cn._51doit.movie.MovieBean;import com.google.gson.Gson;import com.google.gson.JsonSyntaxException;import org.apache.commons.lang3.StringUtils;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.io.ImmutableBytesWritable;import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;import org.apache.hadoop.hbase.mapreduce.TableReducer;import org.apache.hadoop.hbase.util.Bytes;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import java.io.IOException;/***/public class LoadData2HbaseTable {/*** 处理每行数据 生成rowkey和movieBean*/static class LoadData2HbaseTableMapper extends Mapper<LongWritable, Text, Text, MovieBean> {Gson gs = new Gson();Text k = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {try {String line = value.toString();MovieBean mb = gs.fromJson(line, MovieBean.class);String s = StringUtils.leftPad(mb.getMovie(), 5, '0');// 设计rowkey主键String rk = s + "_" + mb.getTimeStamp();k.set(rk);context.write(k, mb);} catch (Exception e) {e.printStackTrace();}}}static class LoadData2HbaseTableReducer extends TableReducer<Text , MovieBean , ImmutableBytesWritable> {@Overrideprotected void reduce(Text key, Iterable<MovieBean> values, Context context) throws IOException, InterruptedException {String rk = key.toString();Put put = new Put(rk.getBytes()); // 行MovieBean mb = values.iterator().next();String movie = mb.getMovie();double rate = mb.getRate();String timeStamp = mb.getTimeStamp();String uid = mb.getUid();put.addColumn("cf".getBytes() , "movie".getBytes() , movie.getBytes()) ;put.addColumn("cf".getBytes() , "rate".getBytes() , Bytes.toBytes(rate)) ;put.addColumn("cf".getBytes() , "timeStamp".getBytes() , timeStamp.getBytes()) ;put.addColumn("cf".getBytes() , "uid".getBytes() , uid.getBytes()) ;context.write(null , put);}}public static void main(String[] args) throws Exception {Configuration conf = HBaseConfiguration.create();conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");Job job = Job.getInstance(conf, "tohbase");job.setMapperClass(LoadData2HbaseTableMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(MovieBean.class);FileInputFormat.setInputPaths(job , new Path("D:\data\movie\input"));TableMapReduceUtil.initTableReducerJob("movie2",LoadData2HbaseTableReducer.class,job);job.waitForCompletion(true) ;}}
要点整理:
rowkey的设计
rowkey决定了你的查询效率
1)观察数据结构 数据特点 了解核心字段
2)了解业务需求 :知道数据的作用,经常查询 经常插入数据
3)经常查询 ---------》确定查询纬度
1 movie
2 uid
3 movie+uid
4)注意点:
1 将查询纬度放在rk上;
2 保证rowkey的唯一性;
3 rowkey可以长度相同,方便排序
4 划分属性含义 用特殊符号 _
5 rowkey不要太长,容易造成大量冗余数据
5)要考虑并发热点问题
以上是关于深入Hbase原理(超详细)的主要内容,如果未能解决你的问题,请参考以下文章