2021年大数据HBase(十四):HBase的原理及其相关的工作机制
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据HBase(十四):HBase的原理及其相关的工作机制相关的知识,希望对你有一定的参考价值。
全网最详细的大数据HBase文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
系列历史文章
2021年大数据HBase(十四):HBase的原理及其相关的工作机制
2021年大数据HBase(十三):HBase读取和存储数据的流程
2021年大数据HBase(十二):Apache Phoenix 二级索引
2021年大数据HBase(十一):Apache Phoenix的视图操作
2021年大数据HBase(十):Apache Phoenix的基本入门操作
2021年大数据HBase(九):Apache Phoenix的安装
2021年大数据HBase(八):Apache Phoenix的基本介绍
2021年大数据HBase(七):Hbase的架构!【建议收藏】
2021年大数据HBase(六):HBase的高可用!【建议收藏】
2021年大数据HBase(五):HBase的相关操作-JavaAPI方式!【建议收藏】
2021年大数据HBase(四):HBase的相关操作-客户端命令式!【建议收藏】
HBase的原理及其相关的工作机制
一、HBase的flush刷新机制(溢写合并机制)
hbase2.0: flush溢写的流程说明
flush溢写流程: hbase 2.0版本后的流程
随着客户端不断写入数据到达memStore中, memStore内存就会被写满(128M), 当memStore内存达到一定的阈值后, 此时就会触发flush刷新线程, 将数据最终写入HDFS上, 形成一个StoreFile文件
1) 当memStore的内存写满后, 首先将这个内存空间关闭, 然后开启一个新的memStore, 将这个写满内存空间的数据存储到一个pipeline的管道(队列)中 (只能读, 不能改)
2) 在Hbase的2.0版本后, 这个管道中数据, 会尽可能晚刷新到磁盘中, 一直存储在内存中, 随着memStore不断的溢写, 管道中数据也会不断的变多
3) 当管道中数据, 达到一定的阈值后, hbase就会启动一个flush的刷新线程, 对pipeline管道中数据一次性全部刷新到磁盘上,而且在刷新的过程中, 对管道中数据进行排序合并压缩操作, 在HDFS上形成一个合并后的storeFile文件
1.0版本中:
区别在于 : 不存在 尽可能晚的刷新 , 也不存在合并溢写操作
注意: 虽然说在2.0时代加入这个内存合并方案, 但是默认情况下是不开启的
2.0中内存合并的策略:
basic(基础型):
说明: 仅做作为基本的合并, 不会对过期数据进行清除操作
优点: 效率高 ,适合于这种有大量写的模式
弊端: 如果数据中大多数都是已经过期的时候, 此时做了许多无用功, 对磁盘IO也会比较大
eager(饥渴型):
说明: 在合并的过程中, 尽可能的去除过期的无用的数据, 保证合并后数据在当下都是可用的
优点: 合并后的文件会较少, 对磁盘IO比较低, 适用于数据过期比较快的场景(比如 购物车数据)
弊端: 由于合并需要多干活,会资源使用也会更多, 导致合并效率降低, 虽然IO减少, 但是依然效率是比较低下的
adaptive(适应型):
说明: 在合并的过程中, 会根据数据的重复情况来决定是否需要采用哪种方案, 当重复数据过多, 就会采用eager型, 否则使用basic(基础型)
优点: 更智能化, 自动切换
弊端: 如果重复数据比较多 但是写入也比较频繁, 此时采用eager, 会导致资源被eager占用较大, 从而影响写入的效率
如何配置内存合并策略:
方案一: 全局配置, 所有表都生效

方案二: 针对某个表来设置

二、HBase的storeFile的合并机制

触发时机:
minor: 触发时机 storeFile文件达到3及以上的时候 | 刚刚启动Hbase集群的时候
major: 默认触发时间: 7天 | 刚刚启动Hbase集群的时候
hbase矛盾点: HBase支持随机读写功能, HBase基于HDFS, 而HDFS不支持随机读写, 如何解决呢?
1) 在Hbase中, 所有的数据随机操作,都是对内存中数据进行处理, 如果是添加, 在内存中加入数据, 如果修改, 同样也是添加操作(时间戳记录版本), 如果删除,本应该是直接到磁盘中将数据删除, 但是HDFS不支持, 在内存中记录好这个标记,不显示给用户看即可
2) 在进行storeFile的major合并操作的时候, 此时将HDFS的数据读取出来到内存中, 边读取边处理, 边将数据追加到HDFS中
三、Hbase的split机制(region分裂)
-
split在最终达到10GB时候, 就会执行split分裂, 分裂之后, 就会形成两个新的Region, 原有Region就会被下线, 新的region会分别各种切分后Hfile文件
-
注意: split的 最终10Gb 指的是当Hbase中Region数量达到9个及以上的时候, 采用按照10GB进行分裂,而什么分裂取决于以下这个公式:
Min (R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”) R为同一个table中在同一个region server中region的个数。
R: 表的Region的数量
flush.size: 默认值为 128M
max.Filesize: 默认值 10GB
思考: 如果现在我希望, Region在5个时候, 最好就可以按照10GB分裂, 如何解决呢?
调整flush.size的大小
四、regionServer的上线流程
- Master使用ZooKeeper来跟踪region server状态
- 当某个region server启动时
- 首先在zookeeper上的server目录下建立代表自己的znode
- 由于Master订阅了server目录上的变更消息,当server目录下的文件出现新增或删除操作时,master可以得到来自zookeeper的实时通知
- 一旦region server上线,master能马上得到消息。

五、regionServer的下线流程
- 当region server下线时,它和zookeeper的会话断开,ZooKeeper而自动释放代表这台server的文件上的独占锁
- Master就可以确定
- region server和zookeeper之间的网络断开了
- region server挂了
- 无论哪种情况,region server都无法继续为它的region提供服务了,此时master会删除server目录下代表这台region server的znode数据,并将这台region server的region分配给其它还活着的节点

六、master的上线和下线
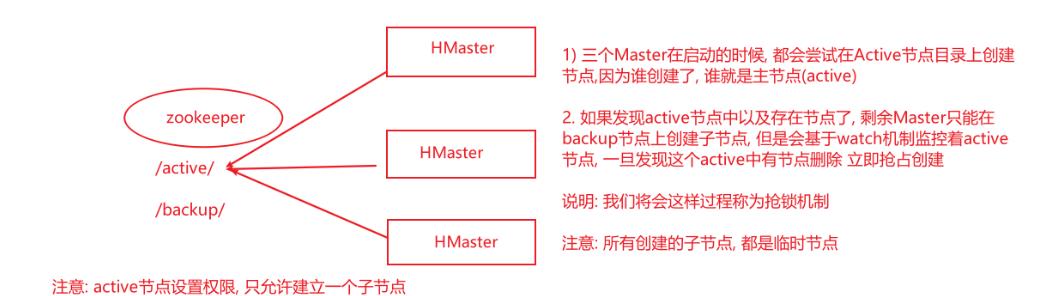
1、Master上线
Master启动进行以下步骤:
- 从zookeeper上获取唯一一个代表active master的锁,用来阻止其它master成为master
- 一般hbase集群中总是有一个master在提供服务,还有一个以上的‘master’在等待时机抢占它的位置。
- 扫描zookeeper上的server父节点,获得当前可用的region server列表
- 和每个region server通信,获得当前已分配的region和region server的对应关系
- 扫描.META.region的集合,计算得到当前还未分配的region,将他们放入待分配region列表
2、Master下线
- 由于master只维护表和region的元数据,而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结
- 无法创建删除表
- 无法修改表的schema
- 无法进行region的负载均衡
- 无法处理region 上下线
- 无法进行region的合并
- 唯一例外的是region的split可以正常进行,因为只有region server参与
- 表的数据读写还可以正常进行
- 因此master下线短时间内对整个hbase集群没有影响。
- 从上线过程可以看到,master保存的信息全是可以冗余信息(都可以从系统其它地方收集到或者计算出来)
注意:
master下线短期对hbase没有太大的影响, 因为master不会参与数据IO操作, 数据读写操作不会使用master
master下线主要是影响了对表的一些 以及对region的操作
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于2021年大数据HBase(十四):HBase的原理及其相关的工作机制的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据HBase:HBase数据模型!!!建议收藏
2021年大数据HBase(十三):HBase读取和存储数据的流程