HBase篇-架构详解
Posted 大叔据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase篇-架构详解相关的知识,希望对你有一定的参考价值。
【每日五分钟搞定大数据】系列,HBase第三篇
聊完场景和数据模型我们来说下HBase的架构,在网上找了张比较清晰的图,我觉得这张图能说明很多问题,那这一篇我们就重点来解析下这张图
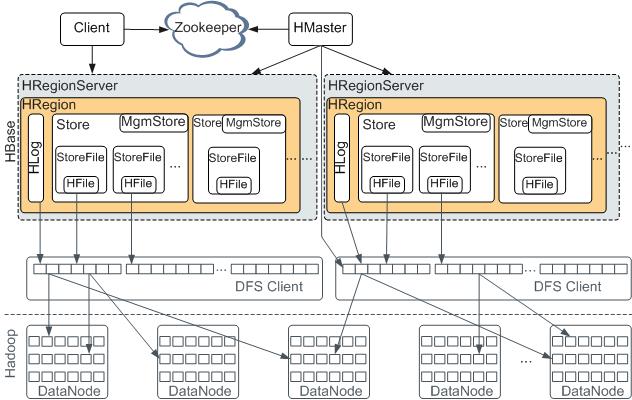
角色与职责
先介绍下上图中的几个角色和Ta们的职责:
1.HMaster
为Region server分配region;
负责Region server的负载均衡;
发现失效的Region server并重新分配其上的region;
处理schema更新请求
2.Client
Client包含访问HBase的接口,并维护cache(region的位置信息)来加快对HBase的访问
3.Zookeeper
在之前的Zookeeper篇讲过HBase和Zookeeper的联系,忘记地同学可以去翻一下。
HMaster的HA
regionserver状态信息
存root表(用于记录.META.表所在的regionServer,该表只会有一个regionServer)
存储HBase的schema和table元数据
发现失效的Region,借助HMaster分配region
4.HRegionSever
即一台服务器,拥有一个到多个HRegion
RegionServer
图里HRegionServer里面的内容很多,大家可能会看得有点懵,我们来详细说下这个HRegionServer里面的东西。
HRegionServer 包含 (1+)个 Region
一个 HRegionServer 包含一到多个Region,而Region就是一张HBase表按一定阈值横向切割的一部分。
Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;
Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上;
Region 包含 (1+)个 Store = columns family 列族个数
Region由一个或者多个Store组成,每个store保存一个columns family;
Store 是一个抽象的概念就是一个存储,它的个数和HDFS上的存储目录个数是一致的,而一个存储目录对应的就是一个columns family列族。
Store 包含(1)个 MemStore +(0+)个 StoreFile
Store 上面说了就是一个存储,他包含了一个内存的存储和0+个文件存储,一个Store的所有文件都存在一个目录下,这个目录下的所有文件对应的是一个列族。 注意:
StoreFile是实际存储数据的。是HFile的轻量级包装。
StoreFile达到阈值个数(4)会进行合并;
一个StoreFile达到阈值大小会进行分裂;
分裂后由hmaster分配到不同region起到负载均衡作用(若出现hot region可以手动拆分)
上面说得可能有点抽象,我们来看具体的数据: 我们来沿用下上一篇的那个表:
如表:
假设这张表有几万行,一行就代表一万行,那可能A和B可能是属于RegionA,C和D可能是属于RegionB,
RegionA和RegionB可能分布在不同的RegionServer上,
可见,RegionA有两个列族,CF1和CF2,
即它有两个Store,
即在HDFS上有两个目录分别用于存放CF1和CF2,
即CF1和CF2在内存里也分别各对应了一个MemStore
读写
这里先讲个大概,后面的文章我会每一步详细分析,比如region的分裂过程,StoreFile的合并过程,rowkey的定位详细流程等等,欢迎持续关注。
Region定位流程:
Zookeeper:记录了.META.表的位置。(1.X之后的版本废除了-ROOT-表)
写流程
向zookeeper发起请求,从ROOT表中获得META所在的region,再根据table,namespace,rowkey,去meta表中找到目标数据对应的region信息以及regionserver
把数据分别写到HLog和MemStore上一份 MemStore达到一个阈值后则把数据刷成一个StoreFile文件。若MemStore中的数据有丢失,则可以总HLog上恢复 当多个StoreFile文件达到一定的大小后,会触发Compact合并操作,合并为一个StoreFile,这里同时进行版本的合并和数据删除。 当Compact后,逐步形成越来越大的StoreFIle后,会触发Split操作,把当前的StoreFile分成两个,这里相当于把一个大的region分割成两个region
读流程
从zookeeper获得root表所在region位置
根据table,namespace,rowkey去root表中获得meta表所在region位置
根据table,namespace,rowkey去meta表中获得这条记录所在regionserver
首先检查请求的数据是否在Memstore,写缓存未命中的话再到读缓存(blockCache)中查找,读缓存还未命中才会到HFile文件中查找,最终返回merged的一个结果给用户
client端会对数据块缓存
数据flush过程
当memstore数据达到阈值(默认是64M),将数据刷到硬盘,将内存中的数据删除同时删除Hlog中的历史数据。
并将数据存储到hdfs中。
在hlog中做标记点。
数据合并过程
当数据块达到4块,hmaster将数据块加载到本地,进行合并
当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的hregionserver管理
当hregionser宕机后,将hregionserver上的hlog拆分,然后分配给不同的hregionserver加载,修改.META.
注意:hlog会同步到hdfs
觉得有价值请关注 ▼
以上是关于HBase篇-架构详解的主要内容,如果未能解决你的问题,请参考以下文章