文本挖掘篇|利用SVM进行短文本分类
Posted 数据帮Club
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘篇|利用SVM进行短文本分类相关的知识,希望对你有一定的参考价值。
对于支持向量机,前面已有小伙伴对它进行详细介绍,若想了解具体情况,可查看历史文章:
数据说明:本次用来训练及测试的分类数据有两类,分别是“体育”类及“文学出版”类,“体育”类数据由899个短文本组成,“文学出版”类数据由797个短文本组成。
先来看看利用SVM文本分类的流程吧!
数据预处理---->数据向量化---->利用Sklearn-learn进行SVM分类
一、数据预处理
对于文本挖掘,数据预处理的过程必不可少同时也至关重要。在数据预处理过程中,主要是进行中文分词及去除停用词。
(一)中文分词
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程,该过程主要为第二步数据向量化特征选择做准备。Jieba分词是目前国内使用人数最多的中文分词工具,且支持三种分词模式,下面对其三种分词模式的使用方法进行简单介绍。

(二)去除停用词
由于中国人的说话习惯,在中文语句中会有许多的语气用词“啊,呀,呢”及一些无特殊含义的词“的,这儿,一些”等,这些词没有实际意义确占比较大,一方面增大了计算量,另一方面减少了有意义词的权重。去除停用词采取的方法通常是,建立一个专门的停用词库,然后调用词库去掉无意义词汇,网上有许多停用词词库,这儿就不具体介绍了。
二、数据向量化
数据向量化是连接文本型数据与计算机的桥梁,可以将文本型数据转化为计算机可读的数值型数据。目前,较为常见的数据向量化方法是使用词向量模型。
词向量(Word embedding),又叫Word嵌入是自然语言处理(NLP)中的一组语言建模和特征学习技术的统称,它是通过“浅层双层的神经网络”对大量文本进行训练,从而将每一个词对应一个向量,建立起词与词之间的关系。这儿对于其训练过程不做过多赘述,直接看如何使用吧!

三、利用Scikit-learn进行SVM分类
Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。当我们面临机器学习问题时,便可根据下图来选择相应的方法。
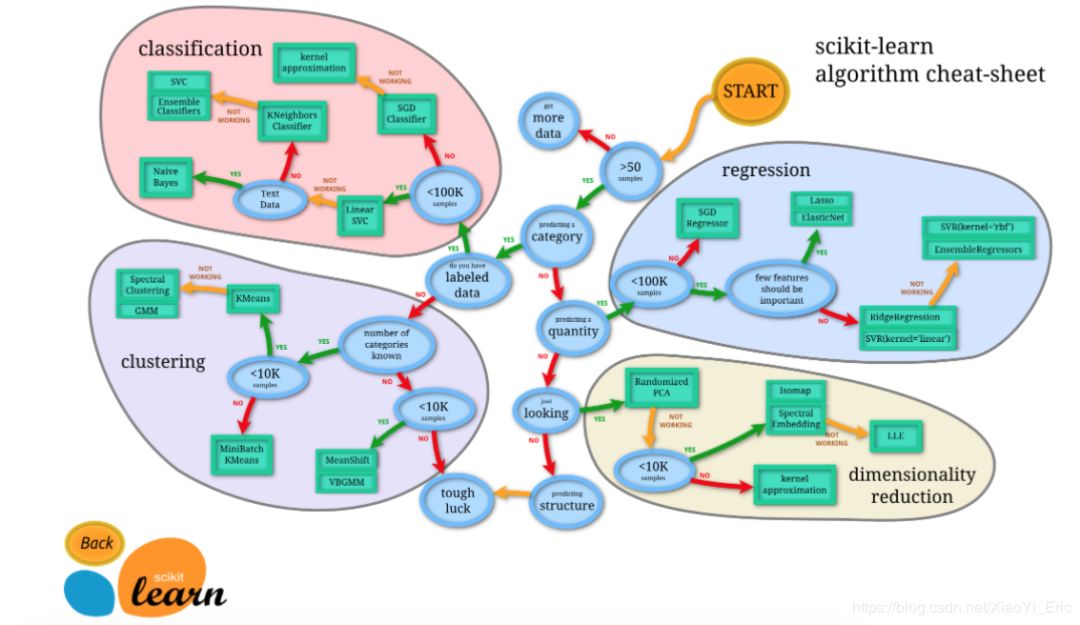
Scikit-learn中的SVM算法库分为两类,一类是分类的算法库,包括SVC, NuSVC和LinearSVC 3个类;另一类是回归算法库,包括SVR, NuSVR和LinearSVR 3个类。相关的类都包含在sklearn.svm模块之中。下面就开始使用Scikit-learn进行SVM短文本分类啦!
在该过程有如下几个步骤:
(一)分类数据贴标签
分别对两类数据进行数据预处理及数据向量化后,每一个短文本都由一个向量表示。接着按照分类将“体育”类文本贴上标签“1”,“文学出版”类文本贴上标签“0”。
(二)合并分类数据并拆分训练集,测试集
将两类数据及对应的数据标签对应合并,接下来使用“sklearn”模块中“train_test_split”包对数据进行切割,随机选择30%的数据作为测试集,剩余数据作为训练集。
(三)利用SVM模型进行训练并测试
SVM模型有许多核函数,使用不同核函数,其效果也不尽相同,在这里使用三个不同的核函数做对比,看看针对本案例那个核函数的预测效果更佳。在该过程使用了“sklearn”模块中“classification_report”和“accuracy_score”包获得预测的准确度,精确度,召回率,F1值。
Accuracy:(准确度),它是预测正确的正例和负例数据占全部数据的比例。
A=(TP+TN)/(TP+TN+FP+FN)
precision:(精确度),它是预测正确的正例数据占预测为正例数据的比例。
P=TP/(TP+FP)
Recall:(召回率),它是预测为正例的数据占实际为正例数据的比例。
R=TP/(TP+FN)
f1-score:(F1),它是精确度和召回率的调和平均值,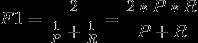
1.使用线性核函数的预测结果
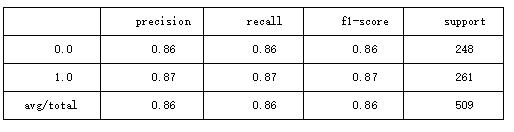 Accuracy: 0.8646365422396856
Accuracy: 0.8646365422396856
2.使用多项式核函数的预测结果
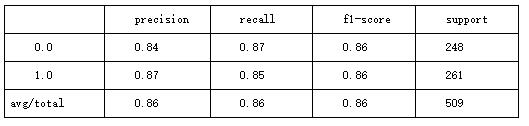
Accuracy: 0.8567779960707269
3.使用径向基核函数的预测结果
Accuracy: 0.8292730844793713
通过对比,可看出对于本案例,使用线性核函数的分类效果更好。通过这个例子,大家是否掌握了进行文本分类的技巧呢,实际上在文本挖掘中,它的前期处理过程大致相同,需要改变只有分类模型的使用哦!
以下,是代码和分类数据的百度网盘链接:
https://pan.baidu.com/s/1MO8cXoHvG4ylhhOv57zu5w
提取码:qf2w
文字来源|陈丹
图片来源|陈丹
编辑|宋欣蕊
审核|叶紫薇
以上是关于文本挖掘篇|利用SVM进行短文本分类的主要内容,如果未能解决你的问题,请参考以下文章