文本分类《融合知识感知与双重注意力的短文本分类模型》
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类《融合知识感知与双重注意力的短文本分类模型》相关的知识,希望对你有一定的参考价值。
·阅读摘要:
本文主要提出基于TextRCNN模型使用知识图谱、双重注意力感知来改进短文本分类,最终提高了精度。
·参考文献:
[1] 融合知识感知与双重注意力的短文本分类模型
参考论文信息 (很牛)
论文名称:《融合知识感知与双重注意力的短文本分类模型》
发布期刊:《软件学报》
期刊信息:CSCD

【注一】:软件学报很厉害的,是国内三大计算机期刊之一。
[0] 摘要
短文本包含有效信息较少且口语化严重, 对模型的特征学习能力要求较高。为此,论文提出KAeRCNN模型, 该模型在TextRCNN模型的基础上, 融合了知识感知与双重注意力机制。
知识感知包含了知识图谱实体链接和知识图谱嵌入, 可以引入外部知识以获取语义特征。
双重注意力机制可以提高模型对短文本中有效信息提取的效率。
[1] 相关工作
基于Word2Vec词向量训练
我们知道不用大模型的话,embedding层一般会使用预训练词向量,常用的词向量有Word2Vec、Glove和FastText,本文用的是Word2Vec。
【注二】:嵌入层是文本领域的必须掌握的知识,可以去【文本分类】深入理解embedding层的模型、结构与文本表示深入了解。
基于机器学习的文本分类
传统的机器学习方法处理短文本的过程主要分为3个阶段, 分别为文本预处理、文本的特征选择和文本训练.。
· 预处理:主要是分词,一般采用jieba、HanLP;
· 特征选择:对分词结果经行进一步提取,常用的方法有CHI、MI、PCA、TFIDF等等‘
· 文本训练:模型很多,主要是机器学习的模型,SVM、KNN、NB等等。
基于深度学习的文本分类
主要是基于CNN和RNN模型算法。
基于预训练模型的文本分类
介绍了Transformer、BERT和ERNIE。
论文说了预训练模型的缺点,很有参考价值:
然而, 基于预训练模型的文本分类方法往往模型参数巨大、收敛缓慢、训练时间长, 并对硬件的要求较为苛刻, 因此这类方法的使用受到了一定程度的限制, 需要根据实际应用背景来使用. 例如: 在处理训练样本稀少的文本分类任务时, 基于预训练模型的方法效果拔群; 然而在有充足训练样本的场景下, 训练时间长以及硬件要求高使其不适用于许多任务。
知识图谱嵌入
典型的知识图谱由数百万个实体-关系-实体三元组(h,r,t)组成, 其中, h、r和 t分别代表三元组的头部、关
系和尾部. 给定知识图谱中的所有三元组, 知识图谱嵌入的目标是学习每个实体和关系的低维表示向量, 保留原始知识图谱的结构信息.
注意力机制
【注三】:注意力就不用多说了。
[2] 模型
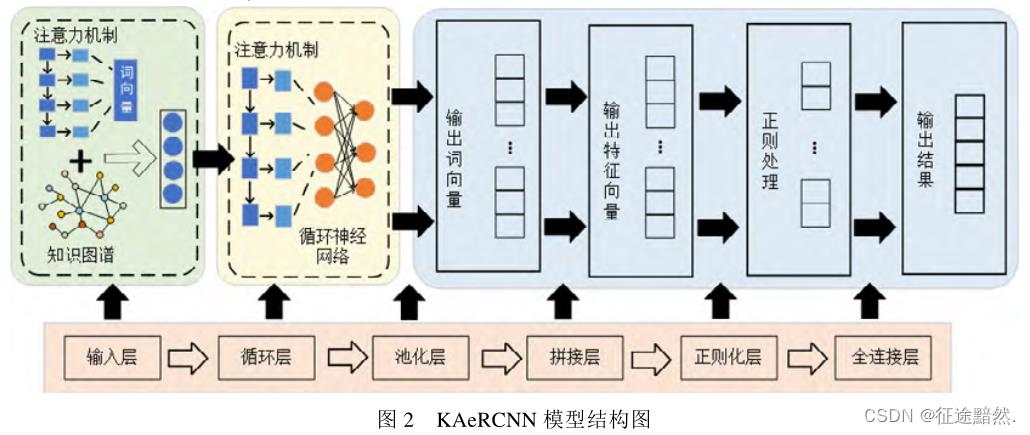
【注四】:个人感觉,论文的模型图画的有些简陋,没把用到的技巧体现出来。
本文模型的创新点如下:
· 双重注意力机制
· 词过滤算法
· 知识感知实体增强
· TextRCNN分类模型
双重注意力机制
论文采取双重注意力机制, 分别在输入层和RCNN中引入注意力机制。
【注五】:这里的“双重”,理解为两处地方用了注意力。论文没有多说在RCNN模型中使用注意力机制,主要介绍了在输入之前使用注意力。
在分类前, 计算词对各类别的贡献度, 为词过滤做准备; 希望将注意力分配给有实际意义、词性重要的名词或动词, 而相对较少或几乎不分配注意力给介词、语气词、口语词一类的词组, 以此赋予有准确语义的词在文本分类任务中有更高的权重。
【注六】:论文的意思是,一条文本中的n个词,把这条文本中的每个词喂到一个单层神经网络,然后得到这个词对所有标签的分类概率,然后会得到一个(词数,标签数)的向量,用于后续筛选词。 想法很新鲜,但是我觉得跟注意力机制不沾边啊。
词过滤算法
在上面一部得到的(词数,标签数)向量,然后我们根据一个贡献度计算公式计算这条n个词的文本中每个词的贡献度,然后把小于一定值的词直接剔除。
加入剔除了a个词,那么现在文本就剩下n-a个词了。
知识感知实体增强
利用实体链接将短文本中通过命名实体识别发现的实体, 与知识图谱中预定义的实体相关联,以消除它们的歧义。最后也会生成一个向量。
TextRCNN分类模型
TextRCNN模型结构代码如下:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed, config.num_classes)
def forward(self, x):
embed = self.embedding(x) # [batch_size, seq_len, embeding] = [128, 32, 300]
out, _ = self.lstm(embed) # [batch_size, seq_len, hidden_size * 2] = [128, 32, 512]
out = torch.cat((embed, out), 2) # [batch_size, seq_len, hidden_size * 2 + embeding] = [128, 32, 812]
out = F.relu(out) # [batch_size, seq_len, hidden_size * 2 + embeding] = [128, 32, 812]
out = out.permute(0, 2, 1) # [batch_size, hidden_size * 2 + embeding, seq_len] = [128, 812, 32]
out = self.maxpool(out).squeeze() # [batch_size, hidden_size * 2 + embeding] = [128, 812]
out = self.fc(out)
return out
很简单,TextRCNN = 嵌入层+biLSTM+池化层+全连接层。
[3] 实验结果及分析
数据集是THUCNews,效果如下:
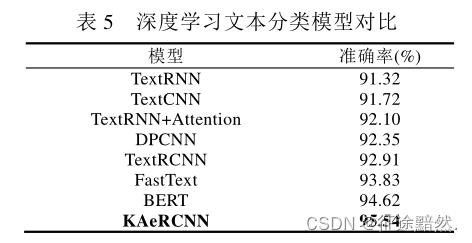
【注七】:实验效果这里,持保留态度。我去网上随便搜了一下,不一定准确,BERT的准确率在96.9%(参考基于THUCNews数据的BERT分类),cnn的准确率在96.04%(参考THUCNews新闻文本分类)。
以上是关于文本分类《融合知识感知与双重注意力的短文本分类模型》的主要内容,如果未能解决你的问题,请参考以下文章