短文本分类概述
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了短文本分类概述相关的知识,希望对你有一定的参考价值。
参考技术A 随着信息技术的发展,最稀缺的资源不再是信息本身,而是对信息的处理能力。且绝大多数信息表现为文本形式,如何在如此大量且复杂的文本信息中如何获取最有效的信息是信息处理的一大目标。文本分类可以帮助用户准确定位所需信息和分流信息。同时,互联网的快速发展催生了大量的书评影评、网络聊天、产品介绍等形式的短文本,其包含大量有价值的隐含信息,迫切需要自动化工具对短文本进行分类处理。 基于人工智能技术的文本分类系统依据文本的语义可实现将大量文本自动分类。多种统计理论和机器学习方法被用于文本自动分类。但其存在最大的问题是特征空间的高维性和文档表示向量的稀疏性。中文词条的总数高达二十多万,如此高维特征空间对所有的算法都是偏大的。亟需一种有效的特征抽取方法,降低特征空间的维数,提高分类的效率和精度。
文本分类方法主要分为两大类,分别是基于传统机器学习的方法和基于深度学习的方法。基于传统机器学习的文本分类方法主要是是对文本进行预处理、特征提取,然后将处理后的文本向量化,最后通过常见的机器学习分类算法来对训练数据集进行建模,传统的文本分类方法中,对文本的特征提取质量对文本分类的精度有很大的影响。基于深度学习的方法则是通过例如CNN等深度学习模型来对数据进行训练,无需人工的对数据进行特征抽取,对文本分类精度影响更多的是数据量以及训练的迭代次数。
短文本相对于长文本,词汇个数少且描述信息弱,具有稀疏性和不规范性, 传统机器学习方法的文本表示是高纬度高稀疏的,特征表达能力很弱,而且神经网络很不擅长对此类数据的处理;此外需要人工进行特征工程,成本很高,不能很好的满足短文本分类的需求。而深度学习最初在之所以图像和语音取得巨大成功,一个很重要的原因是图像和语音原始数据是连续和稠密的,有局部相关性。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,再利用CNN/RNN等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程。
短文本分类算法广泛应用于各个行业领域,如新闻分类、人机写作判断、垃圾邮件识别、用户情感分类、文案智能生成、商品智能推荐等。
场景一:商品智能推荐,根据用户购买的商品名称作为预测样本进行文本分类,得到用户交易类别,结合其他数据构建用户画像,针对不同特征的用户画像预测用户下一步的购买行为,智能推荐商品及服务。
场景二:文案智能生成,基于优质文案作为训练集,得到文本分类模型,当用户输入关键词时,智能推荐适配文案。
场景三:给新闻自动分类或打标签,多个标签。
场景四:判断文章是人写还是机器写的。
场景五:判断影评中的情感是正向、负向、中立,相类似应用场景很广泛。
使用深度学习的词向量技术,把文本数据从高纬度高稀疏的神经网络难处理的方式,变成了类似图像、语音的连续稠密数据,将词语转化为稠密向量,解决了文本表示问题。词向量作为机器学习、深度学习模型的特征进行输入,对最终模型的效果作用比较大。
同时,利用CNN/RNN等深度学习网络及其变体解决自动特征提取(即特征表达)的问题,对应的文本分类模型如下:
1) FastText
FastText是Facebook开源的词向量与文本分类工具,模型简单,训练速度快。FastText 的原理是将短文本中的所有词向量进行平均,然后直接接softmax层,同时加入一些n-gram 特征的 trick 来捕获局部序列信息。相对于其它文本分类模型,如SVM,Logistic Regression和Neural Network等模型,FastText在保持分类效果的同时,大大缩短了训练时间,同时支持多语言表达,但其模型是基于词袋针对英文的文本分类方法,组成英文句子的单词是有间隔的,而应用于中文文本,需分词去标点转化为模型需要的数据格式。
2)TextCNN
TextCNN相比于FastText,利用CNN (Convolutional Neural Network)来提取句子中类似 n-gram 的关键信息,且结构简单,效果好。
3)TextRNN
尽管TextCNN能够在很多任务里面能有不错的表现,但CNN最大的问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节很繁琐。CNN本质是做文本的特征表达工作,而自然语言处理中更常用的是递归神经网络(RNN, Recurrent Neural Network),能够更好的表达上下文信息。具体在文本分类任务中,Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的的 "n-gram" 信息。
4)TextRNN + Attention
CNN和RNN用在文本分类任务中尽管效果显著,但都有一个缺点,直观性和可解释性差。而注意力(Attention)机制是自然语言处理领域一个常用的建模长时间记忆机制,能够直观的给出每个词对结果的贡献,是Seq2Seq模型的标配。实际上文本分类从某种意义上也、可以理解为一种特殊的Seq2Seq,所以可以考虑将Attention机制引入。
Attention的核心点是在翻译每个目标词(或预测商品标题文本所属类别)所用的上下文是不同的,这样更合理。加入Attention之后能够直观的解释各个句子和词对分类类别的重要性。
5)TextRCNN(TextRNN + CNN)
用前向和后向RNN得到每个词的前向和后向上下文的表示,这样词的表示就变成词向量和前向后向上下文向量concat起来的形式,最后连接TextCNN相同卷积层,pooling层即可,唯一不同的是卷积层 filter_size = 1。
总结:实际应用中,CNN模型在中文文本分类中应用效果已经很不错了。研究表明,TextRCNN对准确率提升大约1%,不是十分显著。最佳实践是先用TextCNN模型把整体任务效果调试到最好,再尝试改进模型。
参考: 文本分类解决方法综述
文本分类《融合知识感知与双重注意力的短文本分类模型》
·阅读摘要:
本文主要提出基于TextRCNN模型使用知识图谱、双重注意力感知来改进短文本分类,最终提高了精度。
·参考文献:
[1] 融合知识感知与双重注意力的短文本分类模型
参考论文信息 (很牛)
论文名称:《融合知识感知与双重注意力的短文本分类模型》
发布期刊:《软件学报》
期刊信息:CSCD

【注一】:软件学报很厉害的,是国内三大计算机期刊之一。
[0] 摘要
短文本包含有效信息较少且口语化严重, 对模型的特征学习能力要求较高。为此,论文提出KAeRCNN模型, 该模型在TextRCNN模型的基础上, 融合了知识感知与双重注意力机制。
知识感知包含了知识图谱实体链接和知识图谱嵌入, 可以引入外部知识以获取语义特征。
双重注意力机制可以提高模型对短文本中有效信息提取的效率。
[1] 相关工作
基于Word2Vec词向量训练
我们知道不用大模型的话,embedding层一般会使用预训练词向量,常用的词向量有Word2Vec、Glove和FastText,本文用的是Word2Vec。
【注二】:嵌入层是文本领域的必须掌握的知识,可以去【文本分类】深入理解embedding层的模型、结构与文本表示深入了解。
基于机器学习的文本分类
传统的机器学习方法处理短文本的过程主要分为3个阶段, 分别为文本预处理、文本的特征选择和文本训练.。
· 预处理:主要是分词,一般采用jieba、HanLP;
· 特征选择:对分词结果经行进一步提取,常用的方法有CHI、MI、PCA、TFIDF等等‘
· 文本训练:模型很多,主要是机器学习的模型,SVM、KNN、NB等等。
基于深度学习的文本分类
主要是基于CNN和RNN模型算法。
基于预训练模型的文本分类
介绍了Transformer、BERT和ERNIE。
论文说了预训练模型的缺点,很有参考价值:
然而, 基于预训练模型的文本分类方法往往模型参数巨大、收敛缓慢、训练时间长, 并对硬件的要求较为苛刻, 因此这类方法的使用受到了一定程度的限制, 需要根据实际应用背景来使用. 例如: 在处理训练样本稀少的文本分类任务时, 基于预训练模型的方法效果拔群; 然而在有充足训练样本的场景下, 训练时间长以及硬件要求高使其不适用于许多任务。
知识图谱嵌入
典型的知识图谱由数百万个实体-关系-实体三元组(h,r,t)组成, 其中, h、r和 t分别代表三元组的头部、关
系和尾部. 给定知识图谱中的所有三元组, 知识图谱嵌入的目标是学习每个实体和关系的低维表示向量, 保留原始知识图谱的结构信息.
注意力机制
【注三】:注意力就不用多说了。
[2] 模型
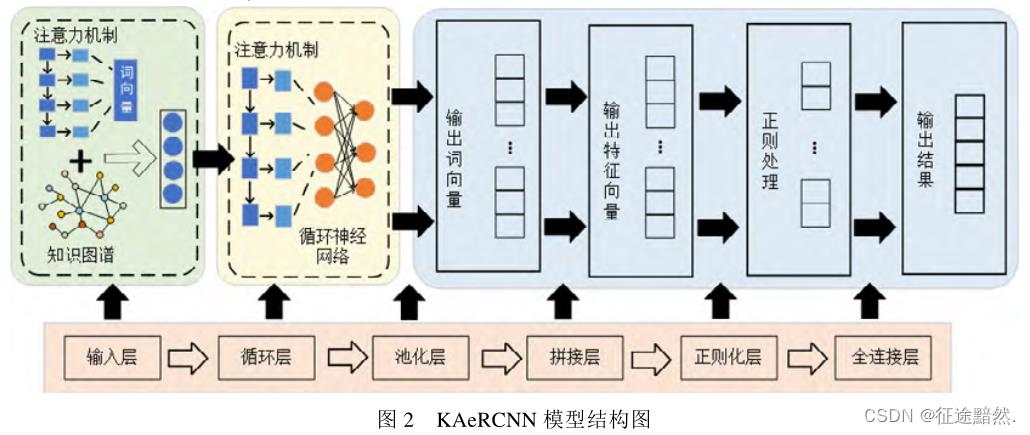
【注四】:个人感觉,论文的模型图画的有些简陋,没把用到的技巧体现出来。
本文模型的创新点如下:
· 双重注意力机制
· 词过滤算法
· 知识感知实体增强
· TextRCNN分类模型
双重注意力机制
论文采取双重注意力机制, 分别在输入层和RCNN中引入注意力机制。
【注五】:这里的“双重”,理解为两处地方用了注意力。论文没有多说在RCNN模型中使用注意力机制,主要介绍了在输入之前使用注意力。
在分类前, 计算词对各类别的贡献度, 为词过滤做准备; 希望将注意力分配给有实际意义、词性重要的名词或动词, 而相对较少或几乎不分配注意力给介词、语气词、口语词一类的词组, 以此赋予有准确语义的词在文本分类任务中有更高的权重。
【注六】:论文的意思是,一条文本中的n个词,把这条文本中的每个词喂到一个单层神经网络,然后得到这个词对所有标签的分类概率,然后会得到一个(词数,标签数)的向量,用于后续筛选词。 想法很新鲜,但是我觉得跟注意力机制不沾边啊。
词过滤算法
在上面一部得到的(词数,标签数)向量,然后我们根据一个贡献度计算公式计算这条n个词的文本中每个词的贡献度,然后把小于一定值的词直接剔除。
加入剔除了a个词,那么现在文本就剩下n-a个词了。
知识感知实体增强
利用实体链接将短文本中通过命名实体识别发现的实体, 与知识图谱中预定义的实体相关联,以消除它们的歧义。最后也会生成一个向量。
TextRCNN分类模型
TextRCNN模型结构代码如下:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed, config.num_classes)
def forward(self, x):
embed = self.embedding(x) # [batch_size, seq_len, embeding] = [128, 32, 300]
out, _ = self.lstm(embed) # [batch_size, seq_len, hidden_size * 2] = [128, 32, 512]
out = torch.cat((embed, out), 2) # [batch_size, seq_len, hidden_size * 2 + embeding] = [128, 32, 812]
out = F.relu(out) # [batch_size, seq_len, hidden_size * 2 + embeding] = [128, 32, 812]
out = out.permute(0, 2, 1) # [batch_size, hidden_size * 2 + embeding, seq_len] = [128, 812, 32]
out = self.maxpool(out).squeeze() # [batch_size, hidden_size * 2 + embeding] = [128, 812]
out = self.fc(out)
return out
很简单,TextRCNN = 嵌入层+biLSTM+池化层+全连接层。
[3] 实验结果及分析
数据集是THUCNews,效果如下:
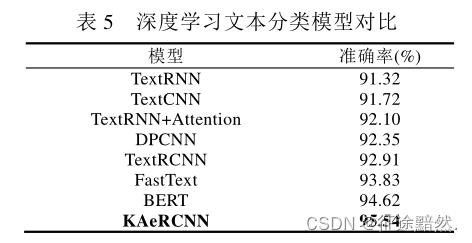
【注七】:实验效果这里,持保留态度。我去网上随便搜了一下,不一定准确,BERT的准确率在96.9%(参考基于THUCNews数据的BERT分类),cnn的准确率在96.04%(参考THUCNews新闻文本分类)。
以上是关于短文本分类概述的主要内容,如果未能解决你的问题,请参考以下文章