通过文本挖掘,我们发现了国家公务员考试的这些秘密
Posted 达观数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过文本挖掘,我们发现了国家公务员考试的这些秘密相关的知识,希望对你有一定的参考价值。
据中国新闻网报道,2020年度中央机关及其直属机构公务员招考笔试有超143万人报名,涉及中央和国家机关86个单位、23个直属机构,而计划招录2.4万人,通过资格审查人数与录用计划数之比约为60:1,在报名期间出现多个竞争超“千里挑一”的职位也就不足为奇了。
虽然笔者没参加过国家公务员考试(以下简称“国考”),但本着“内行看门道,外行看热闹”的心态,笔者想一个旁观者的视角,通过一些语义分析技术去发现近八年(2011~2018)国考行政职业能力测验(以下简称“行测”)考了哪些内容,看能否有一些规律性的发现。



-
小王步行的速度比跑步慢50%,跑步的速度比骑车慢50%。如果他...问小王跑步从A城到B城需要多少分钟 ;
-
甲、乙两人计划从A地步行去B地,乙早上7︰00出发,匀速步行前往,...,为了追上乙,甲决定跑步前进,跑步的速度是乙步行速度的2.5倍,但每跑半小时都需要休息半小时,那么甲什么时候才能追上乙 ;
-
如右图所示,甲乙两人从A、B两点同时出发,朝不同方向沿小路散步,已知甲的速度是乙的2倍。问以下哪个坐标图能准确描述两人之间的直线距离与时间的关系
Note
-
词频:一般词汇出现的次数越多,它的重要程度越高; -
位置:句首、句中还是句末,一般来说,句中的词汇权重会高一些; -
词性:名词、动词); -
词长:词汇的长度,一般来说,词汇的长度越长,好汉的语义信息越丰富,给的权重也更高一些。
-
字体大小表示词汇的权重值大小,原理同上,能反映词汇在评论中的重要性
-
不同的颜色代表不同的话题
-
词汇之间距离越近,说明它们在同一语境中出现的频率较高,越具有语义相关性, 比如“速度”、“执法船”、“行驶”、“小时”和“骑车”等词汇挨得很近,我们能迅速联想这些关键词跟试题中的“行程问题”有关,而不是跟政治、物理或者汽车有关。
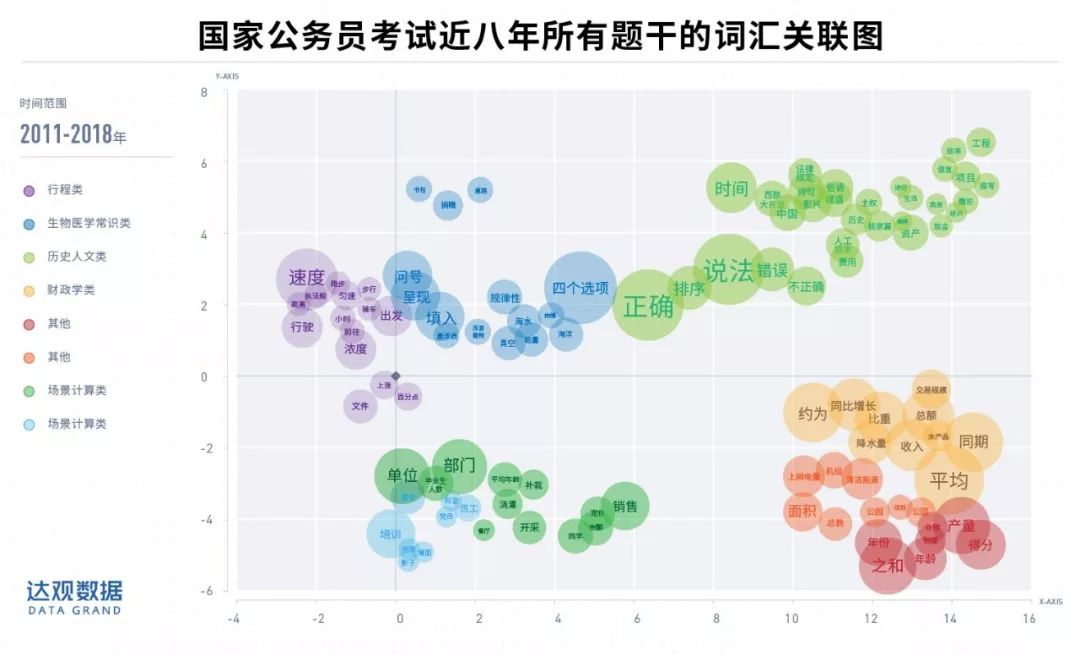
-
行程类: 这类题一般涉及到路程、速度、时间三者的变化关系,主要反映在紫色系的词汇簇群中,从“速度”、“行驶”、“距离”、“骑车”等词汇可以看出;
-
生物医学常识类: 这类题主要考察应试者对于生物和医学相关常识的知识覆盖面,主要反映在深蓝色的词汇簇群中,从“抽搐”、“浮游植物”、“悬浮质”、“海水”等词汇可以看出;
-
财政学类: 这类题主要考察应试者在宏观经济相关指标的简单计算能力,主要反映在土黄色的词汇簇群中,从“交易规模”、“总额”、“水产品”、“同比增长”等词汇可以看出;
-
场景计算类: 这类题从应试者的生活、工作场景出发,考察应试者的基本计算能力,主要反映在青绿色和宝石蓝两个词汇簇群中,从“培训”、“部门”、“单位”、“平均年龄”、“概率”、“定价”和“余额”等词汇可以看出。
Note:
此处的词汇关联图基于HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)实现。相较于传统的聚类算法(K-means、Spectral clustering、Agglomerative clustering、DBSCAN等),它有如下3大优良特性:
-
不需要设定聚类数,有算法自动算出来簇群数 -
可以较好的处理数据中的噪音 -
可以找到基于不同密度的簇(与DBSCAN不同),并且对参数的选择更加鲁棒(Robust,模型更加健壮)
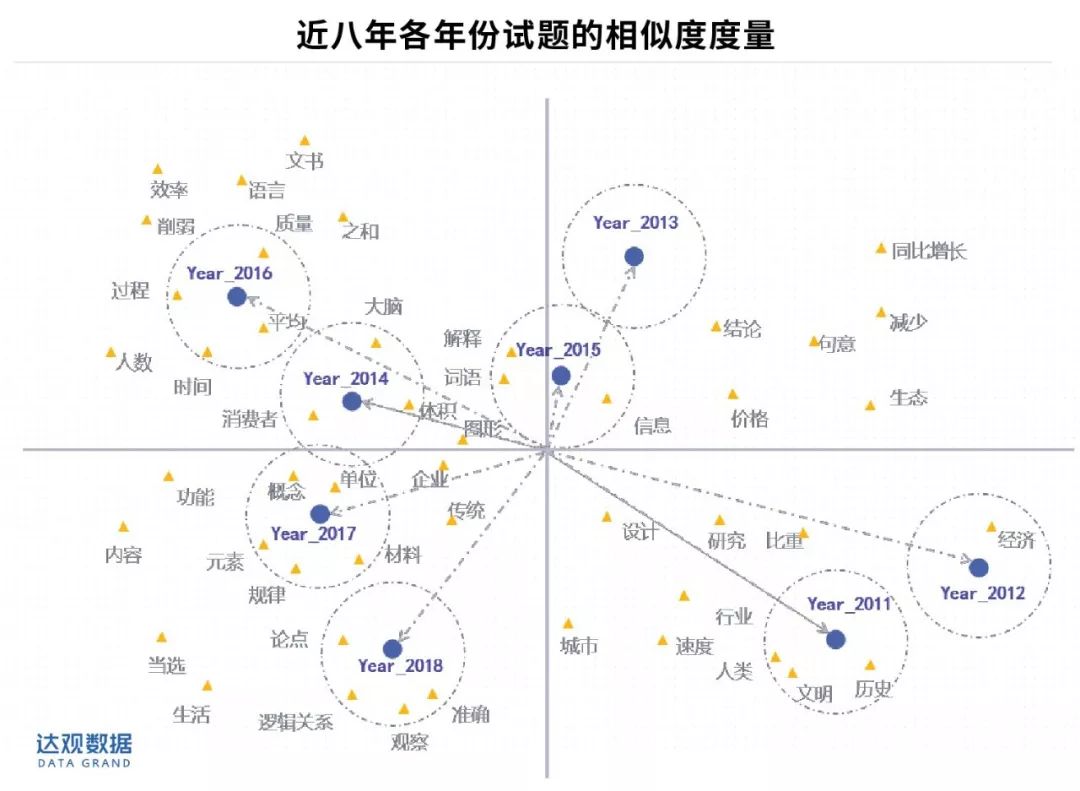
-
从历年的考题内容相似度来看,2011年和2012年、2017年和2018年的试题内容相关度较高,也就意味着出题结构的连续性较好,以此类推,2013年度、2014年度、2015年度和2016年度的试题连续性也较好。与之相反的是,2012年度、2013年度的出题内容相似度较低,出题内容有一定的跳跃性。 总体上来看,国考试题在出题内容上的连续性较好,只是偶尔出现变动。
-
从历年试题的特征来看,2011年的人文特征较为明显,2018年的经济方面的试题较多,2018年的逻辑测试较突出,2015年的语言学方面出题较多,2016年的偏计算,其他年份的特征不甚突出。
Note:
对应分析法可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。比如不同年份的试题是不同类别,关键词汇是变量。对应分析图谱可以将这8年的试题相关度情况通过视觉上可以接受的定位图展现出来。

以上是关于通过文本挖掘,我们发现了国家公务员考试的这些秘密的主要内容,如果未能解决你的问题,请参考以下文章