数据挖掘,我们有秘密武器(上)
Posted 基迪奥生物
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘,我们有秘密武器(上)相关的知识,希望对你有一定的参考价值。
在我们平时的工作中,经常会遇到小伙伴咨询,怎么样能对高通量测序的数据进行挖掘呢,有没有比较详细的文章能介绍一下呢。鲁迅先生曾说过,这世上本没有路,走的人多了,便也就成了路。同样的,问的人多了,自然方法也就来了。我们将历来的经验进行汇总,得出了一个常见数据挖掘方法:
图1.转录组数据挖掘常用方法
根据上面的图所示,转录组的数据挖掘可以从三个方面入手:表达量、功能和寻找“明星”入手,今天我们先来了解一下表达量挖掘法吧。
表达量挖掘法
做过转录组的朋友们都知道,我们拿到结果的时候会得到每个基因在每个样本中的表达量,但是面对数以万计的基因时,似乎有点无从入手,那么这个时候,我们就要请出转录组分析的高手——表达量数据挖掘四大利器:差异分析、韦恩图、趋势分析、WGCNA分析了。
1
数据挖掘冷兵器——差异分析
我们先从利器之首——差异分析说起。差异分析是数据挖掘的匕首,武器虽小但非常实用,许多其他的数据挖掘法如富集分析都会基于它来进行,可以说是灰常重要了。
差异分析的思路非常简单,通过比较两组或多组样本间的差异,就可以获得我们想要的差异基因了。虽然相对于数以万计的全部基因,差异基因的范围从几十到几千,已经缩小了很多,但是很多时候我们依然不知道哪些基因才是影响表型差异的“罪魁祸首”,也就无法针对性的进行后续的验证。
根据我们的经验来看,可以选择TOP N的方法来进行筛选,即选择差异最大的前10 or 20个基因来研究或展示。我们可以理解为,由于它们在差异的组间起到了重要的作用,因此才会高度的表达,从而引起表型的差异。
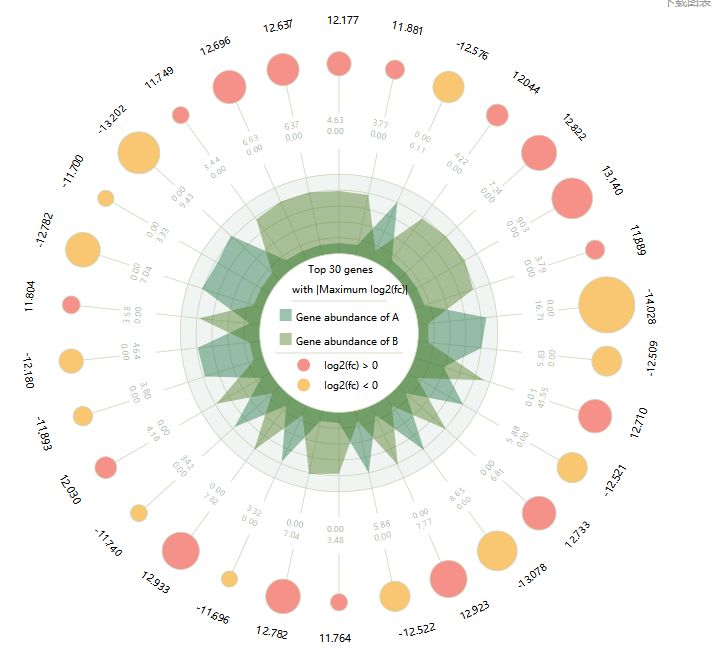
图2.差异显著TOP 30的雷达图
2
人间大炮——韦恩图
说完了差异分析,我们来说说大炮韦恩图。韦恩图的分析有两种思路,一种是做两组或多组的韦恩图,这个时候我们获得的就是它们共有或特有的基因;另一种思路,则是对差异比较组来绘制韦恩图,这个时候我们获得的就是在不同差异比较下,共有或特有的基因。
这两种思路是不太一样的,第一种针对的是组与组之间有没有表达的基因,而第二种针对的则是组与组之间有没有差异的基因,这背后蕴含的生物学意义可是大不相同的。
针对组间有没有表达的基因,我们可以推测导致两组或多组样本间的表型差异可能是由于这类特有基因的存在引起的(如图5上图中两个不同品种的韦恩图比较),那么针对这些基因,我们就可以深入进行挖掘,推测可能的机制。
而针对组间有无存在的差异基因,如图5下图中不同时间的处理组和对照组的比较,特有的部分就是响应不同时期应答的基因,而这些基因很有可能是响应不同阶段外界刺激的重要“功臣”。通过韦恩图,可以帮助我们合理的过滤不同类别的基因,方便我们进行数据挖掘。

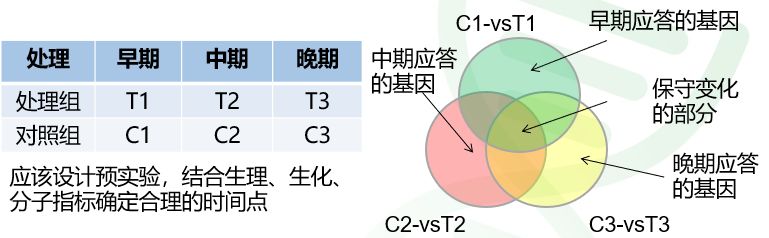
图3.组间韦恩图分析(上图)和差异比较组韦恩图分析(下图)
3
加特林机枪——趋势分析
而趋势分析则是机枪,针对性强,只有当我们的样本大于3组的时候,才能够把它请出来。它的基本思路就是,每个基因的表达量是个单一的点,而通过趋势分析,将不同时间点的基因链接起来,整体的去查看基因的变化情况,提高目标基因筛选的准确度。
每种趋势背后其实都会有它的生物学意义,所以我们可以选择符合我们预期变化的趋势来进一步分析。基因变化的情况往往受到实验设计的影响,比如3个时间点的干旱胁迫处理,我们可能会关心一直上调的这类基因,它们可能是植物为了响应外界胁迫而不停工作的抗逆基因,那么一直上调的趋势就是我们需要重点关注的对象。
但是有些小伙伴说了,我也不知道到底哪些趋势是符合我的预期的呀,那这个时候,我们就比较建议大家直接从显著的趋势入手,模块显著,说明在趋势变化中,大部分基因都符合这种变化,这些基因可能在抗逆的过程中起到的非常重要的作用。
图4.趋势分析
4
大规模杀伤武器——WGCNA
虽然趋势分析能对大于3组的样本进行分析,但是如果样本大于5组甚至更多的时候,它就会有些吃力了。样本越多,越复杂,需要更厉害的武器去解开谜团,而这个时候,我们就需要向WGCNA这个重量级的核弹寻求帮助了。
WGCNA的思路是将基于RNA表达量的调控关系,将表达模式相近的基因进行归类,划分基因模块,再与表型数据相结合,找出与表型相关的基因模块,随后挑选模块内核心基因,构建调控网络图。
WGCNA强调的是整体的基因模块,而不是单一的基因,它将数以万计的基因表达量信息精简成几十个模块,降低了我们需要分析的难度。当然,如果我们已经有目标基因,也可以直接找其所在的模块,然后进分析模块中基因间的调控关系。
如果我们有大样本量的数据时,通常会建议大家在前期的时候尽可能多收集表型数据,比如研究的是与小麦产量相关的机制,那么我们就尽量收集每亩穗数、每穗粒数、颖花数、结实率、结实率、粒重(千粒重)等等性状,通过WGCNA分析,将性状和基因模块关联起来。
我们寻找到了与表型相关的基因模块后,可以对模块内的基因再进行富集分析,从而找到核心基因。通过WGCNA的方法找到的核心基因,在功能实验中往往有更高验证率。
图5.WGCNA与形状结合
介绍了这么多,相信大家对表达量挖掘法有大致的了解了,那么下期我们将针对功能挖掘法和寻找“明星”这两种方法进行介绍。关于表达量挖掘法还有更多的疑问,可以联系基迪奥生物,我们会专门针对你的问题进行答疑解惑哦~那么,我们下期再见啦~
以上是关于数据挖掘,我们有秘密武器(上)的主要内容,如果未能解决你的问题,请参考以下文章