近5万首《全唐诗》里有趣的秘密,大数据用文本挖掘告诉你
Posted 全球大数据峰会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了近5万首《全唐诗》里有趣的秘密,大数据用文本挖掘告诉你相关的知识,希望对你有一定的参考价值。
近些年来,弘扬中华传统文化的现象级综艺节目不断涌现,如《中国汉字听写大会》、《中国成语大会》、《中国谜语大会》、《中国诗词大会》等,其背后的社会成因,在于人们对中国文化中最精致文字的膜拜心理,虽然浸淫于层出不穷的网络语汇,时时面临“语言荒漠”的窘境,仍心向往之。
在这里,笔者分析的语料是《全唐诗》,它编校于清康熙四十四年(1705年),得诗四万八千九百余首。
接下来,笔者将使用多种文本挖掘方法,来分析《全唐诗》。
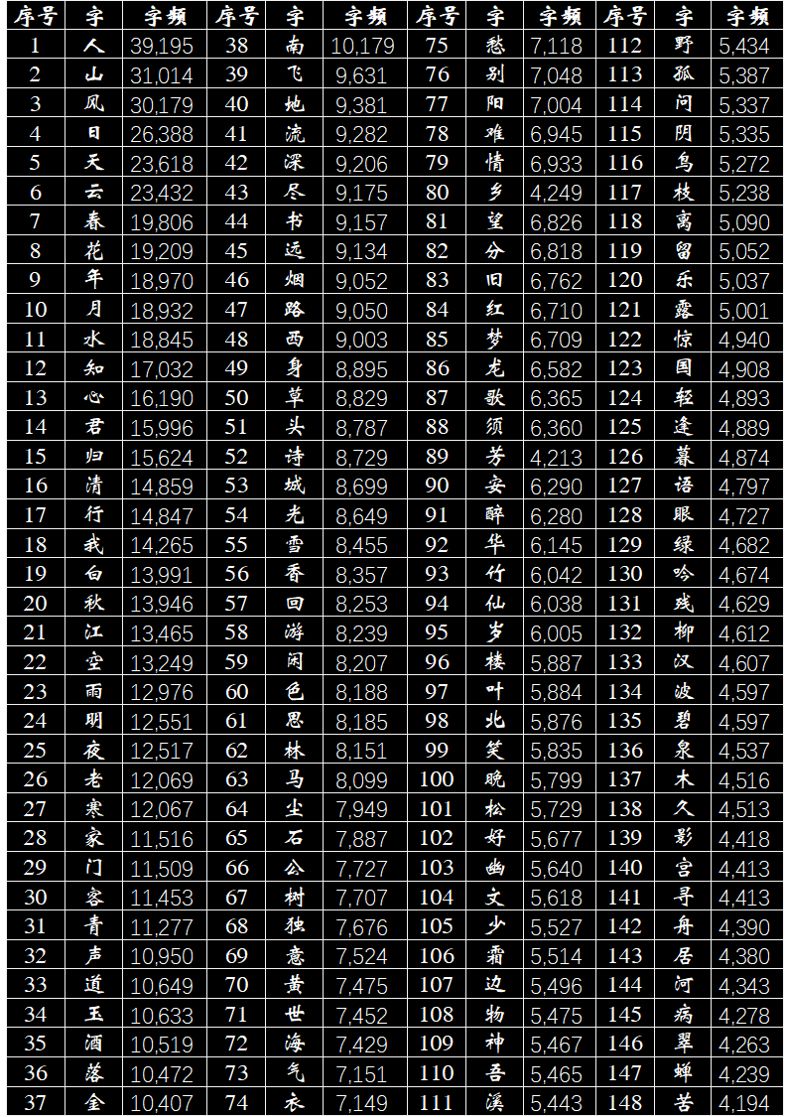
1. 全局高频字
首先,让我们来看看去掉这些虚词之后的全局高频字有哪些,笔者这里展示的是TOP148。“人”字排行第一,这体现了《说文解字》里所讲的“人,天地之性最贵者也”,说明唐诗很好的秉承了“以人为本”的中华文化。而后续的“山”、“风”、“月”、“日”、“天”、“云”、“春”等都是在写景的诗句里经常出现的意象。

 2. 典型意象分析
2. 典型意象分析
所谓“意象”,就是客观物象经过创作主体独特的情感活动而创造出来的一种艺术形象。简单地说,意象就是寓“意”之“象”,就是用来寄托主观情思的客观物象。在比较文学中,意象的名词解释是---所谓“意象”简单说来,可以说就是主观的“意”和客观的“象”的结合,也就是融入诗人思想感情的“物象”,是赋有某种特殊含义和文学意味的具体形象。简单地说就是借物抒情。
比如,“月”这个古诗词里常见的意象,就有如下内涵:
表达思乡、思亲念友之情,暗寓羁旅情怀,寂寞孤独之感;
历史的见证今昔沧桑感;
冷寂、凄清的感觉;
清新感 。
笔者在这里挑选的意象是关于季节和颜色的。
◆ ◆ ◆ ◆ ◆
物转星移几度秋——《全唐诗》中的季节
统计“春”、“夏/暑”、“秋”、“冬”这4个字在《全唐诗》中出现的频次,“春”字排行榜首,“秋”字列第2位,“夏”和“冬”出现的频次则要少1个量级,在唐诗里,伤春、惜春是常见的春诗题材,代表性的作品有朱淑真《赏春》、杜甫《丽春》、韩愈《春雪》、张若虚《春江花月夜》等。也难怪,在商代和西周前期,一年只分为春秋二时,后世也常以春秋作为一年的代称,约定俗成,由来已久,这两个字的使用频率很高也就不足为奇了。

◆ ◆ ◆ ◆ ◆
万紫千红一片绿——《全唐诗》中的色彩
笔者在这里找了51个古语中常用的颜色的单字(注意是古汉语语境中的颜色称谓),其中以红色系(红、丹、朱、赤、绛等)、黑色系(暗、玄、乌、冥、墨等)、绿色系(绿、碧、翠、苍等)及白色系(白、素、皎、皓等)为主,这些颜色及其对应的字频如下表所示:
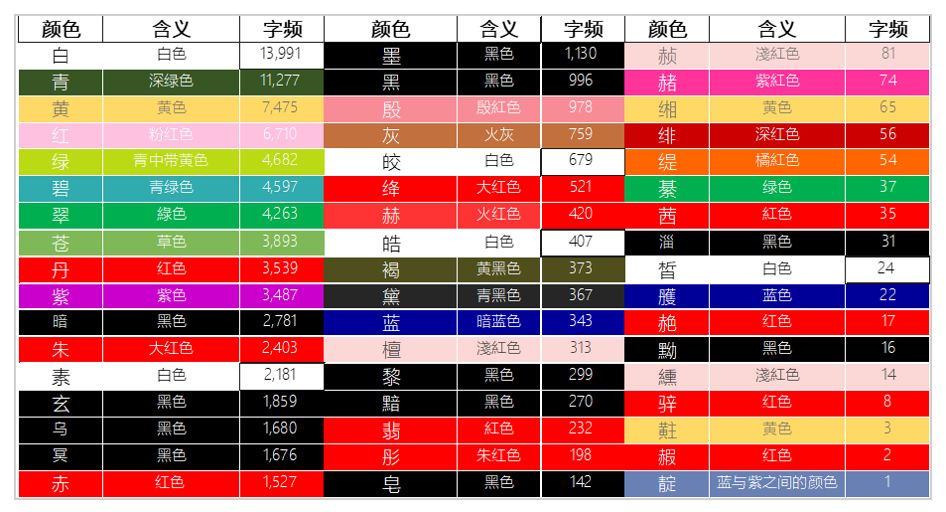
这里面“白”字的字频最高,本意是“日出与日落之间的天色”,笔者常见的有“白发”、“白云”、“白雪”,常渲染出一种韶华易逝、悲凉的气氛,名句如“白头搔更短,浑欲不胜簪”、“白雪却嫌春色晚,故穿庭树作飞花”、“君不见,高堂明镜悲白发,朝如青丝暮成雪”、 “白云一片去悠悠,青枫浦上不胜愁”。
将上述主要的色系综合统计一下,得到下面的环形占比图:
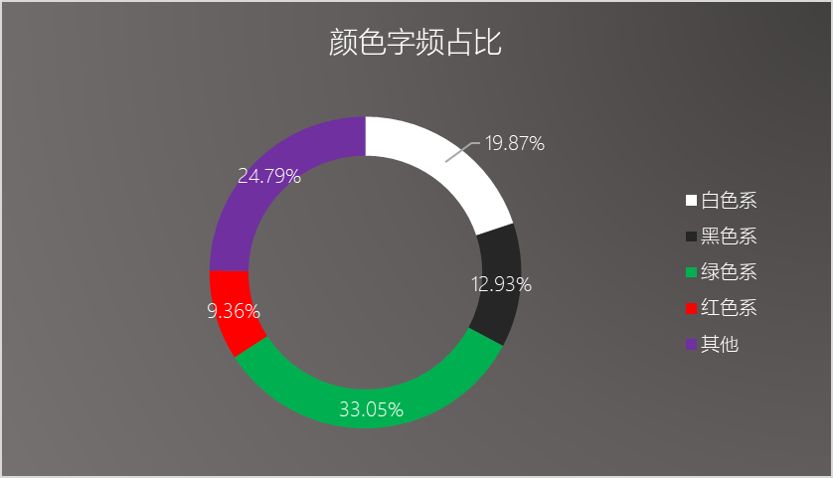
其中,绿色系的占比居多,“绿”“碧”“苍”“翠”等大都用于写景,“绿树”、“碧水”、“苍松”、“翠柳”等,这些高频字从侧面反映出全唐诗中描写景物、寄情山水的诗句占比很大,透露出平静、清新和闲适之感。
刚才笔者分析的是单字,而汉语的语素大都是由单音节(字)表示,即所谓的“一音一义”。当这些单音节语素,能够独立应用的话,就是词。古汉语中存在着许多单音节词,这也就是文言文翻译中要经常把一个字翻译成现代汉语中的双音节词的原因。
然而,有些单音节语素,不能够独立使用,就不是词,只能够是语素,如“第-“、”踌-“、”- 们“。
鉴于此,笔者想发现一些唐诗中的常用双字词,看看其中的成词规律是怎样的。笔者在这里选取共现次数超过10次的词汇,并列出TOP200的共现双字词。关键操作步骤如下所示:

以下是TOP200的共现双字词:
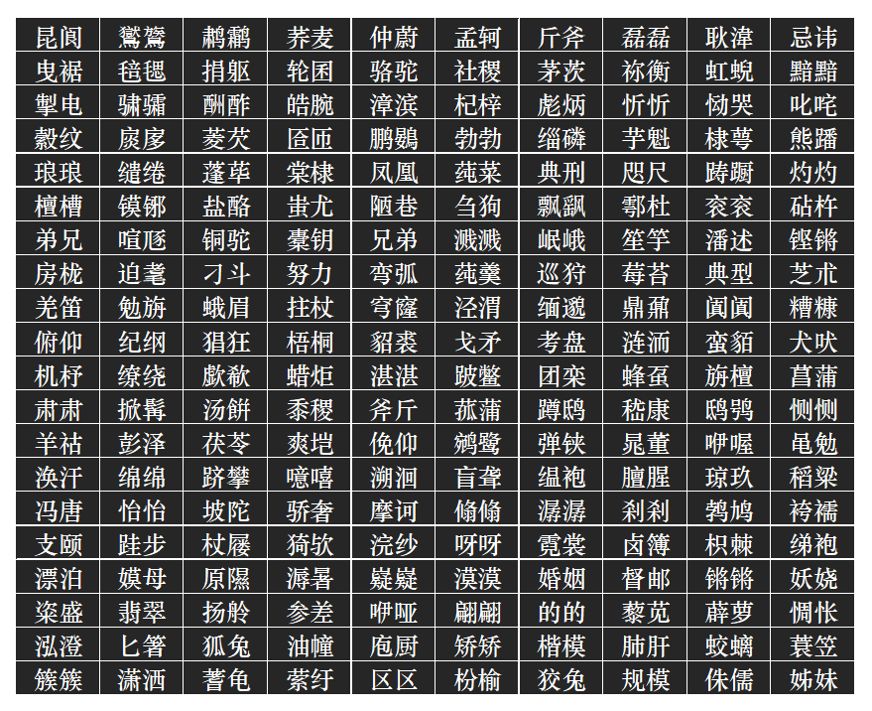
从上面的双词探测结果中,笔者可以发现如下6类成词规律:
复合式(A+B等于C):由两个字组成,这两个字分别代表意义,组成双音节的词,这类词出现的频次最多。比如,弟兄、砧杵、纪纲、捐躯、巡狩、犬吠。
重叠式(AA等于A):琅琅、肃肃、忻忻、灼灼。
叠音(AA不等于A):琅琅(单独拆开不能组其他词)、的的(拆开后的单字的词义不同)等。
双声(声母相同):踌躇(声母都是c,分开各自无法组词)、参差(声母都是c)、缅邈(声母都是m)。
叠韵(韵母相同):噫嘻(韵母是i)、缭绕(韵母是ao)、妖娆(韵母是ao)等。
双音节拟声词:歔欷、咿哑等。
在这一部分,笔者抽取的是上述高频字TOP148中的字的共现关系。
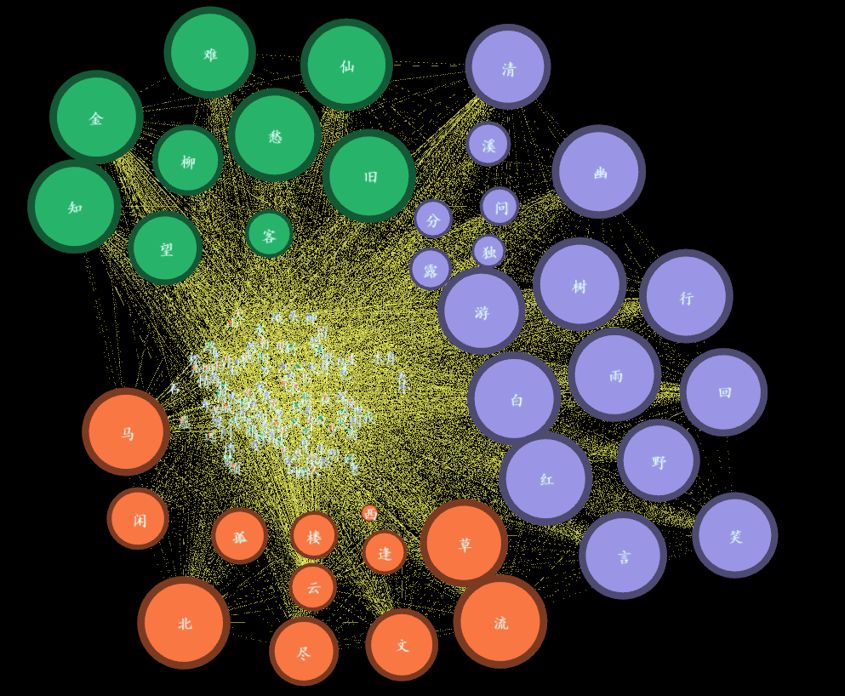
可以看到,上述的语义网络可以分为3个簇群,即橙系、紫系和绿系,TOP148高频字中,字体清晰可见字的近40个。圆圈的大小表示该字在语义网络中的影响力大小,也就是“Betweenness Centrality(中介核心性),”学术的说法是“两个非邻接的成员间的相互作用依赖于网络中的其他成员,特别是位于两成员之间路径上的那些成员,他们对这两个非邻接成员的相互作用具有某种控制和制约作用”。在诗句中,这些字常以“字眼”的形式呈现,也就是诗文中精要的字。3类中:
橙系:北、流、马、草、闲、孤、逢、云等;
紫系:游、树、雨、回、笑、言、幽、清、白、野、行等
绿系:知、金、柳、难、愁、旧、仙、望、客。
其中,根据字的构成来看,绿系簇群中的字大多跟送别(好友)有关。
王国维在《人间词话》里曾提到:“境非独谓景物也,喜怒哀乐,亦人心中之一境界。故能写真景物、真感情者,谓之有境界…”,讲的是"境"与"境界"通用---写景亦可成境界,言情亦可成境界,因为景物是外在的世界,情感是内在的世界。所以,在这里,笔者想分析一下全唐诗中诗词所表达出来的内在境界,也就是内在情感,为了丰富分析维度,不采用简单的二元分析,即“积极”和“消极”2种情绪,而是7种细颗粒的情绪分类,即悲、惧、乐、怒、思、喜、忧。
根据上面获取到的字向量,经过人工遴选后,得到可以用于训练的“情绪字典”,根据诗歌中常见的主题类别,情绪类别分为:
悲:愁、恸、痛、寡、哀、伤、嗟…
惧:谗、谤、患、罪、诈、惧、诬…
乐:悦、欣、乐、怡、洽、畅、愉…
怒:怒、雷、吼、霆、霹、猛、轰…
思:思、忆、怀、恨、吟、逢、期…
喜:喜、健、倩、贺、好、良、善…
忧:恤、忧、痾、虑、艰、遑、厄…
笔者在这里采用的是基于LSTM(LongShort-Term Memory,长短期记忆网络)的情绪分析模型。
在这里,我们会将文本传递给嵌入层(Embedding Layer),因为有数以万计的字词,所以我们需要比单编码向量(One-Hot Encoded Vectors)更有效的表示来输入数据。这里,笔者将使用上面训练得到的Word2vec字向量模型,用预先训练的词嵌入(Word Embedding)来引入的外部语义信息,做迁移学习(Transfer Learning)。
以下是简要原理展示图:
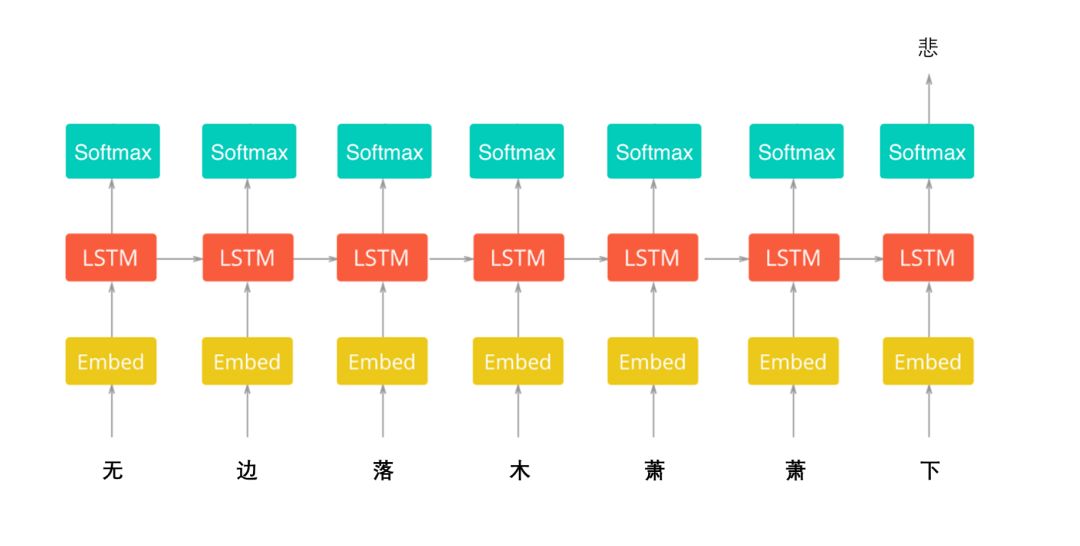
笔者随机测试了100句,判断准确的有86条,粗略的准确率估计是86%。当然,这只是一次不太严谨的小尝试,在真实的业务场景里,这得花很多时间来做优化,提高模型的准确率。
下面是对《全唐诗》近5万首诗的情绪分析结果,展示如下:
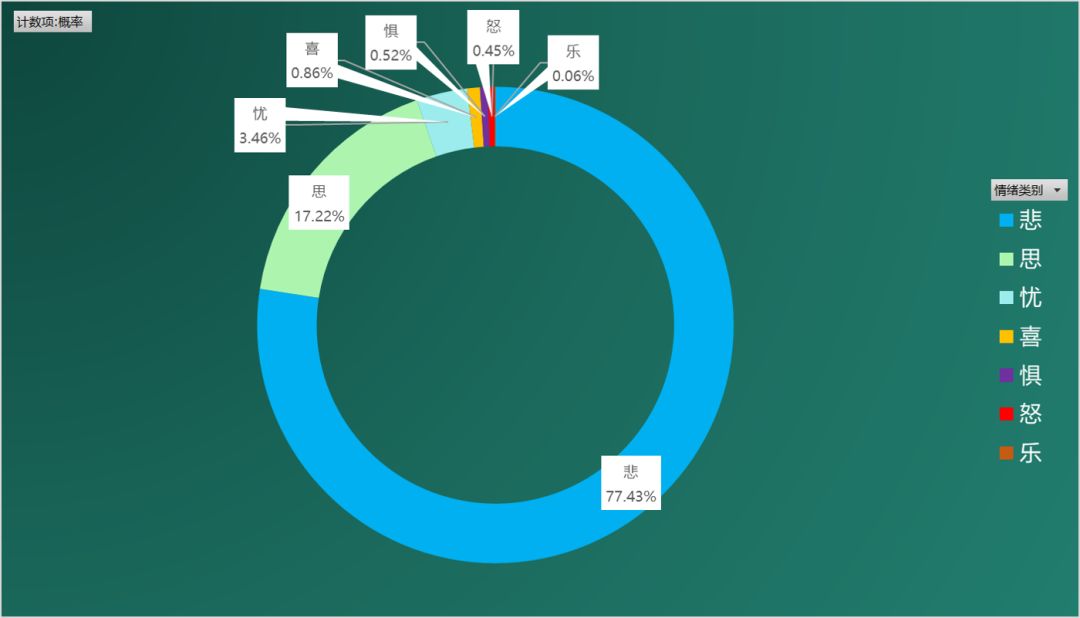
可能出乎很多人的意料,代表大唐气象的唐诗应该以积极昂扬的情绪为主,怎么会是“悲”、“思”、“忧”这样的情绪占据主流呢?而 “喜”、“乐”这样的情绪却占据末流呢?
接下来,笔者着重来分析下“悲”这个情绪占据主流的原因。
从常见的唐诗写作题材上说,带有“悲”字基调的唐诗较多,也多出名诗佳句,比如唐诗中常见的几种情结,如“悲秋情结”、“别离情结”、“薄暮情结”和“悲怨情结”,都体现出浓重的“悲情”色彩。
古人云:“悲愤出诗人”,它点破了人的成就与所处的环境、心境有某种关系。就像司马迁所说:“夫《诗》、《书》隐约者,欲遂其志之思也。昔西伯拘羑里,演《周易》;孔子厄陈、蔡,作《春秋》…大抵贤圣发愤之所为作也。此人皆意有所郁结,不得通其道也…”回顾古今中外的著名的诗人和作家,几乎无一不是曾有一段被排挤,诽谤,不得志和身处逆境之经历,有些甚至还很悲惨。正是在这种悲难,恶劣环境中,才使得其奋发图强。
重要的是,唐诗中的“悲”不仅仅是做“儿女态”的悲,更是具有超越时空、怜悯苍生以及同情至美爱情的大慈大悲。如下:
陈子昂的《登幽州台歌》,“前不见古人,后不见来者。念天地之悠悠,独怆然而涕下。”从时间与空间两个角度把悲凉拉长了。
李白的《将进酒》中“君不见明镜高堂悲白发,朝如青丝暮成雪”,以及《梦游天姥吟留别》中“世间行乐亦如此,古来万事东流水”让人唏嘘!还有《长相思》第一首中“天长路远魂飞苦,梦魂不到关山难。长相思,摧心肝。”
杜甫的《登高》中“无边落木萧萧下,不尽长江滚滚来。万里悲秋常作客,百年多病独登台。”老病残躯,孤苦无依独登台,心中悲凉陡然而生。《石壕吏》中“老妪力虽衰,请从吏夜归。急应河阳役,犹得备晨炊”等句语言朴实,但极具张力!
白居易的《长恨歌》末尾“七月七日长生殿,夜半无人私语时。在天愿作比翼鸟,在地愿为连理枝。天长地久有时尽,此恨绵绵无绝期。”相爱而不能相聚,生死遗恨,没有尽头!
与上面情绪分析模型采用的内部原理一致,这里采用的还是LSTM,2层网络。
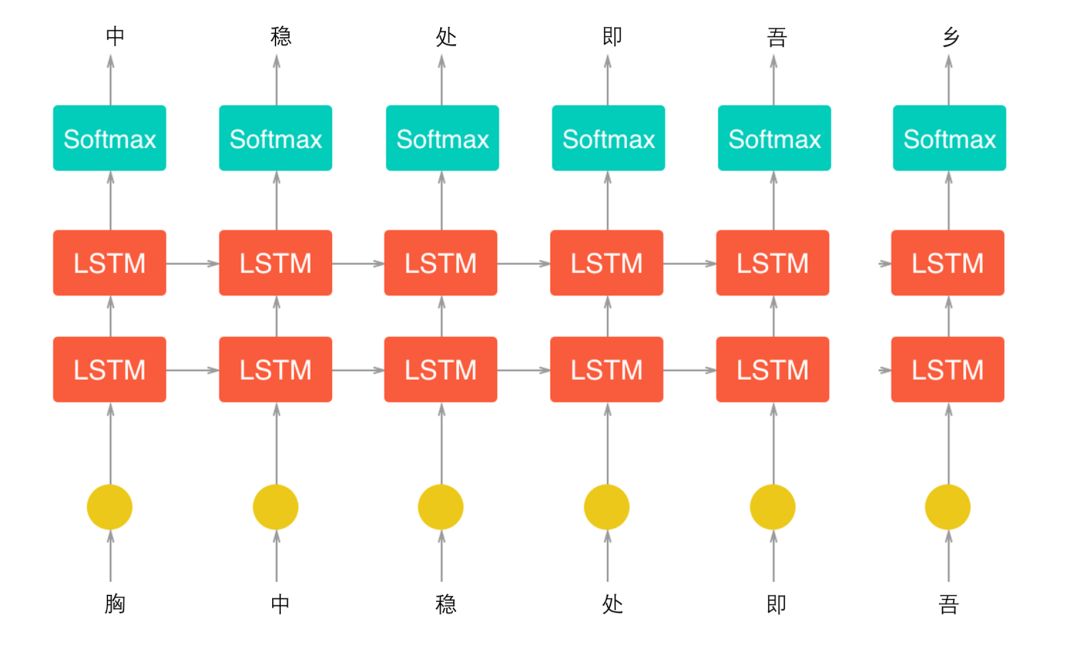
上图是文本生成的简要原理图,是基于字符(字母和标点符号等单个字符串,以下统称为字符)进行模型构建,也就是说我们的输入和输出都是字符。举个栗子,假如我们有一个一句诗“胸中稳处即吾乡”,我们想要基于这句诗来构建LSTM,那么希望的到的结果是,输入“胸”,预测下一个字符为“中”;输入“中”时,预测下一个字符为“稳”…输入“吾”,预测下一个字符为“乡”,等等。
由于其中的原理过于繁复,涉及大量的code和数学公式,故笔者仅展示生成的结果,训练的语料即经过预处理的《全唐诗》。
以“春雨”打头,生成500字的诗词,结果如下:
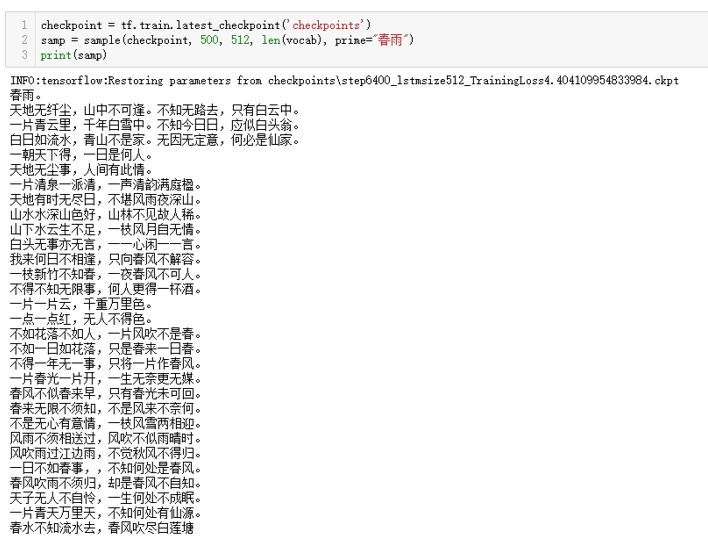
可以看见,其中的诗词大都围绕着“春”来展开,也就是打头的两个字引导了后续结果的生成,这多亏了LSTM超强的“记忆能力”——记住了诗歌文本序列中的时空依赖关系。
在生成的诗句中,某些诗句还是蛮有意思的,上下联间的意象有很强的相关性。
下面是多次生成中产生的较优秀的诗句(当然,这是笔者认为的),其中有些学习到了高阶的对仗技巧,如下:

白鹭惊孤岛,朱旗出晚流。
笔者最喜欢的是这两句,它们对仗工整:“白鹭”-“朱旗”,“孤岛”-“晚流”,“惊”-“出”。这里体现出《人间词话》中的“无我之境”: “无我之境,以物观物,故不知何者为我,何者为物”,也就是意境交融、物我一体的优美境界,其中的 “惊”、“出”堪称字眼,极具动感,炼字绝妙!
最后,我们来看看诗歌的信息检索问题,也就是笔者随意输入一句诗词,然后机器会按照语义相似度在《全唐诗》中检索出若干句符合要求的诗词。
谈到这里,笔者不由得想起一个词——“射覆”,射覆游戏早期的耍法主要是制谜猜谜和用盆盂碗等把某物件事先隐藏遮盖起来,让人猜度。这两种耍法都是比较直接的。后来,在此基础上又产生了一种间接曲折的语言文字形式的射覆游戏,其法是用相连字句隐寓事物,令人猜度,若射者猜不出或猜错以及覆者误判射者的猜度时,都要罚酒。唐浩明的长篇小说《张之洞》中有对射覆游戏的精彩描写:
宝竹坡突然对大家说,我有一覆,诸位谁可射中。不带大家做声,他立刻说,《左传》曰:伯姬归于宋。射唐人诗一句。大家都低头想。
……
张之洞不慌不忙地念着,白居易诗曰:老大嫁作商人妇。
如果对古文生疏,大家可能很难将这两句联想起来,但《张之洞》里接下来就有关于解谜的描述:
杨锐道:“伯、仲、叔、季,这是中国兄弟姊妹得排行序列。伯姬是鲁国的长公主,排行老大。周公平定武庚叛乱后,把商旧都周围地区封给商纣王的庶子启,定国名为宋,故宋国为商人后裔聚族之地。伯姬嫁到宋国,不正是'老大嫁作商人妇'吗?”
大家可能会想,如果是自己来思索的话,不仅需要自己具备渊博的学识,更要有疾如闪电的反应能力,这个非极顶聪明之人不可!
试想,机器来做,可以做好吗?能的话,又会是如何操作?
这里,笔者介绍基于WMD(Earth Mover’s Distance)的语义相似度算法,与上面的情绪分析类似,还有用到之前训练得到的字向量模型,借助外部语义信息来应对同义不同字的情形。
WMD是一种能使机器以有意义的方式(结合文本的语义特征)评估两个文本之间的“距离(也就是文本间的相似度)”的方法,即使二者没有包含共同的词汇。它使用基于word2vec的词向量,已被证明超越了k-近邻分类中的许多现有技术方法。以下是基于WMD的“射覆”的机器解:
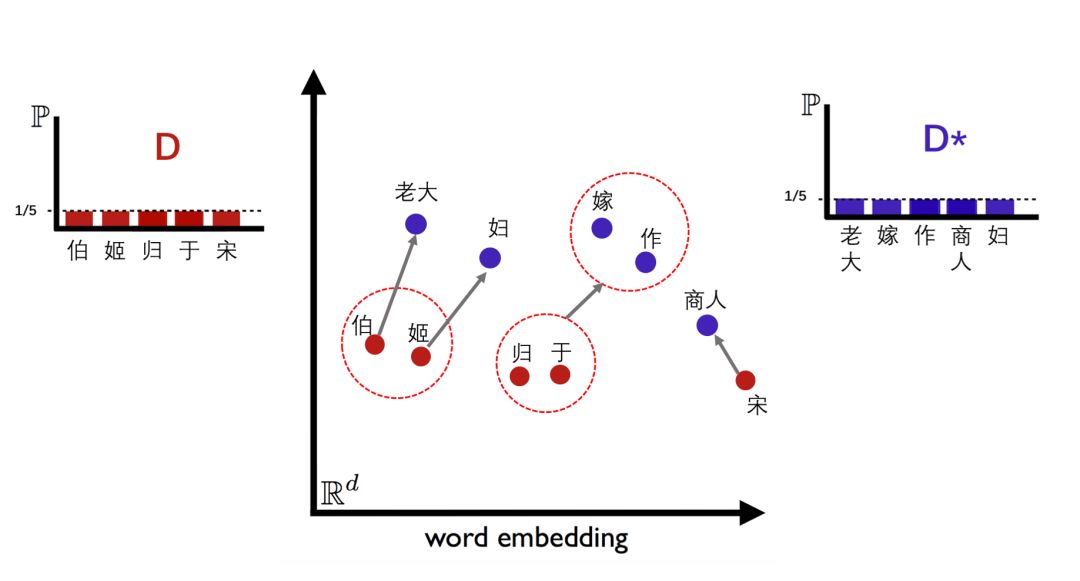
上面两个句子没有共同的词汇,但通过匹配相关单字,WMD能够准确地测量两个句子之间的(非)相似性。该方法还使用了基于词袋模型的文本表示方法(简单地说,就是词汇在文本中的频率),如下图所示。该方法的直觉是最小化2段文本间的“旅行距离(traveling distance)”,换句话说,该方法是将文档A的分布“移动”到文档B分布的最有效方式。
简要的解释了相关原理后,笔者紧接着展现最后的分析效果。由于对《妖猫传》中的那首线索式的《清平乐》印象深刻,笔者让机器在《全唐诗》+《全宋词》中查找与它相关性最大的TOP9诗词。结果如下:
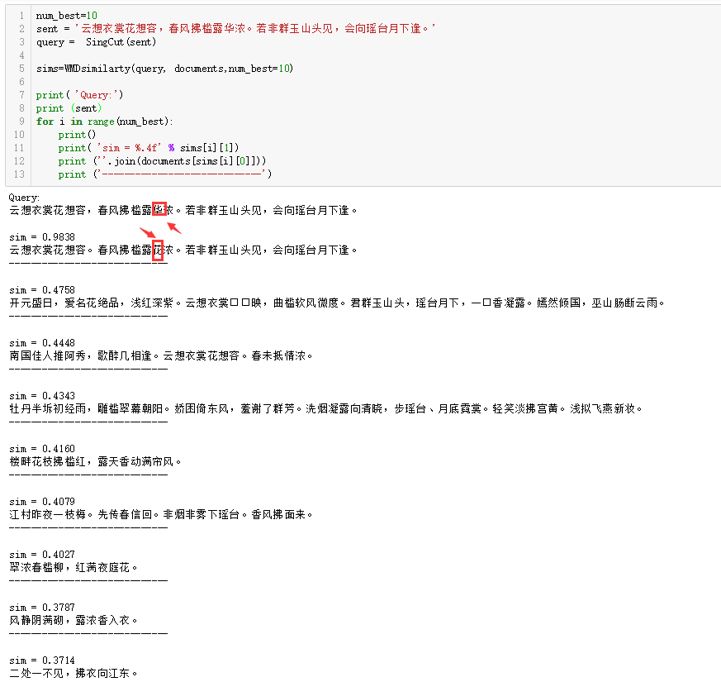
查找的结果排行第一的是原句,但有一个字不同(其实古语中“花”、“华”互通,华字的繁体是会意字,本意是“花”),略微差异导致相似度不为1.0。第二相似的是一首宋词,林正大的《括酹江月(七)》,其实这整首词可以作为李白《清平乐》的注解,因为全篇都是对它的化用:即将《清平乐》中的句、段化解开来,增加了新的联想,重新组合,灵活运用,对原诗的表达进行了情感上的升华。随后的两句诗词也是类似的情况,只是相似度上略有差异罢了。
紧接着,是刚才机器生成的诗句,看看与它内涵相近的诗句有哪些:

再看看笔者较为欣赏的2句名句,机器很好的捕捉到了它们之间的相似语义关系,即使词汇不尽相同,但仍能从语义上检索相似诗句。


写到这里,关于《全唐诗》单独的文本挖掘已经完成,但笔者又想到一个有趣的分析维度——从文本挖掘的角度来比较《全唐诗》、《全宋词》和《全元曲》之间用字的差异,借助字这种基本符号来分析各自的文学艺术特征。
因为分析的对象涉及3个,常规的二元对比分析方法难以得出有效的结论。因此,笔者在这里跨界采用来自符号学领域的研究成果——Semiotic Squares。
“Semiotic Squares(笔者译作‘符号方块’)”,是由知名符号学大师Greimas和Rastier发明,是一种提炼式的对比分析(Oppositional Analyses)方法,通过将给定的两个相反的概念/事例(如 “生命(Life)”和“死亡(Death)”)的分析类型(通过‘或’、‘与’、‘非’的逻辑)拓展到4类(如“生命(Life)”、“死亡(Death)”、“生死相间(也就是活死人,The Living Dead)”、“非生非死(天使,Angels)”,有时还可以拓展到8个或10个分析维度。以下是符号方块的结构示意图:

说明:“+”符号将2个词项组合成一个“元词项(Metaterm)”(复合词,Compound Term),例如,5是1和2的复合结果。
说完了分析的大致原理,笔者这里就来实战一番,与上述原始模型不同的是,笔者在这里除了基本的二元对立分析外,还新增了一个分析维度,总体是关于《全唐诗》、《全宋词》和《全元曲》的三元文本对比分析。
预处理前的文本是这样的:
预处理后是这样的形式:
用Semiotic Squares进行分析的结果如下图所示(点击即可放大显示):
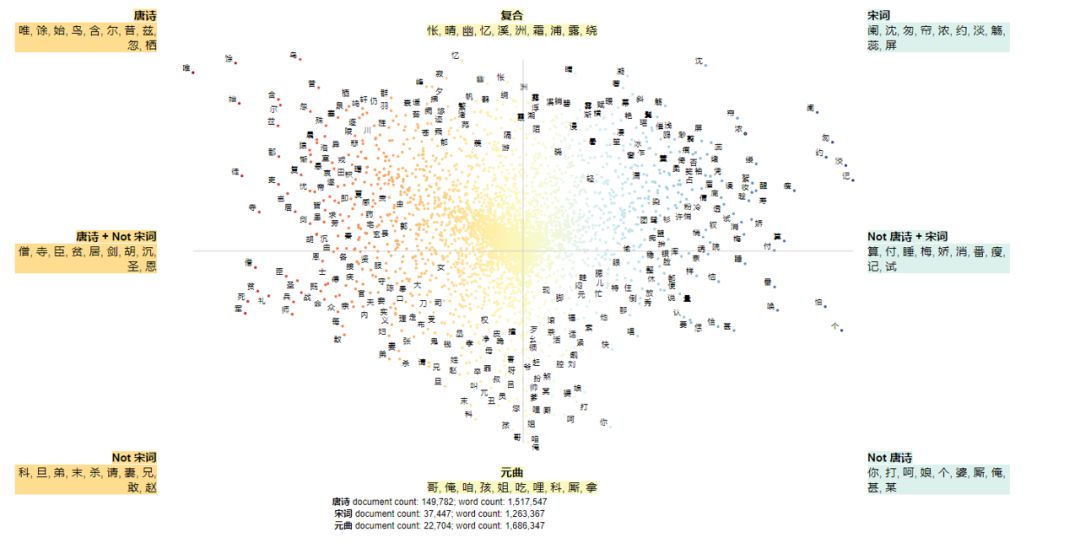
从上面呈现的TOP10高频字和象限区块(左上角“唐诗”、右上角“宋词”和正下方“元曲”)来看,唐诗、宋词、元曲中出现的独有高频字依次是:
唐诗:唯、馀、始、鸟、含、尔、昔、兹、忽、栖、川、旌、戎、秦…
宋词:阑、沈、匆、帘、浓、约、淡、觞、蕊、屏、凝、笙、瑶、柔…
元曲:哥、俺、咱、孩、姐、吃、哩、科、厮、拿、你、叫、呀、呵…
从上面的关键字来看,唐诗、宋词和元曲各自的特征很鲜明:
唐诗:用字清澹高华、含蓄,诗味较浓,寄情山水和金戈铁马的特征明显,可以联想到唐诗流派中典型的山水田园派和盛唐边塞诗,它们大都反映大唐诗人志趣高远、投效报国的情怀。
宋词:所用的字体现出婉约、宛转柔美,表现的多是儿女情长,生活点滴,这也难怪,由于长期以来词多趋于宛转柔美,人们便形成了以婉约为正宗的观念。
元曲:所用的字生活气息浓重,通俗易懂、接地气、诙谐、洒脱和率真,充分反映了其民间戏曲的特征,这与蒙元治下的汉族知识分子被打压,很多文人郁郁不得志、转入到民间戏曲的创作中来有关。
此外,正上方的“复合”中,表征的是三者皆常用的字,即共性特征,主要涉及写景(如 “晴”、“幽”、“溪”、“洲”、“霜”、“浦”、“露”、 “碧”、“帆”、“峰”等)和抒情(等“怅”、“忆”、“寂”、“悠”等)。
下方的两个象限,“Not 唐诗”和“Not 宋词”分别代表的“宋词+元曲”、“唐诗+元曲”,三者之二的共性高频字,中的两项也以此类推,笔者在这里就不赘述了,请读者朋友们亲自去挖掘里面的玄妙吧。

笔者非专业的诗歌研究者,上面的分析也未必准确,如果有分析不恰当的地方,还请扶正。但是,笔者是想通过分析唐诗,来说下自己对于文本(数据)挖掘的看法:
在数据分析中,得出的数据结果只是“引子”和“线索”,最重要的还是要靠人脑去分析结果,借助所掌握的背景/业务知识和分析模型,从文本的表层钻取到其深层,去发现那些不能为浅层阅读所把握的深层意义,挖掘其价值。
来源:运营喵是怎样炼成的(ID:yymzylc)
GBDC(全球大数据联盟)是大数据领域第三方中立性平台,以促进大数据产业发展、提升产业集群创新能力和核心竞争力为宗旨,致力于打造大数据技术产业链、创新链和服务链,探索建立长效稳定的产学研合作机制,突破产业发展的核心技术,形成产业技术标准,搭建有效的合作交流平台。
以上是关于近5万首《全唐诗》里有趣的秘密,大数据用文本挖掘告诉你的主要内容,如果未能解决你的问题,请参考以下文章