文本挖掘实操用文本挖掘剖析54万首诗歌
Posted Social Listening与文本挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘实操用文本挖掘剖析54万首诗歌相关的知识,希望对你有一定的参考价值。
当前浏览器不支持播放音乐或语音,请在微信或其他浏览器中播放
许多年之后,面对书桌上的两句残词,贬居黄州的东坡居士将会回想起,他在故乡眉山见到朱姓老尼的那个遥远的下午。彼时的东坡还不是东坡,还只是一个七岁孩童。有一天,他在家附近偶遇一位年约九十的朱姓老尼。老尼看到苏轼天资聪颖,就跟他聊起自己年轻时的经历,曾跟随师父进入后蜀主孟昶的宫中。一日,天酷热,孟昶和他的妃子花蕊夫人深夜纳凉于摩诃池上。面对此情此景,蜀主即兴赋词一首...老尼将她印象中仅存的打头两句告诉了苏轼。
四十年后,苏轼贬居于黄州,想起这段往事,遗憾于孟昶的词只余两句,突发奇想要将这两句词续写完整。他先猜测出这首词的词牌名---“洞仙歌令”,但要还原整首词作,必须深刻结合写词人当时之心情以及伴随而来的意境。苏轼因而循着仅存的两句词,根据老尼给他的描述,竭力在脑海中还原蜀主当时的创作场景和心境,最终将词续完,成就名作《洞仙歌》:
冰肌玉骨,自清凉无汗。水殿风来暗香满。绣帘开,一点明月窥人,人未寝,倚枕钗横鬓乱。
起来携素手,庭户无声,时见疏星渡河汉。试问夜如何,夜已三更,金波淡,玉绳低转。但屈指西风几时来,又不道流年暗中偷换。
以上就是文学史上有名的“东坡续词”,虽说是文学史上的一段佳话,但笔者从中隐约看到了数理思维的影子:
在一定的约束条件下,如诗词要遵守的平仄、押韵、对仗/对偶、五七变式、词谱、情境等,诗词创作者用文字将自己内心的真实感动用语言文字表达出来,在“戴着镣铐在跳舞”的情况下,竭力达到音韵美、精炼美、言辞美、朦胧美、情感美、绘画美和形式美的至臻境界...
既然诗歌的创作是有规律的,那么,通过一定的数据挖掘手段,我们是能够从中发现一些insight的。
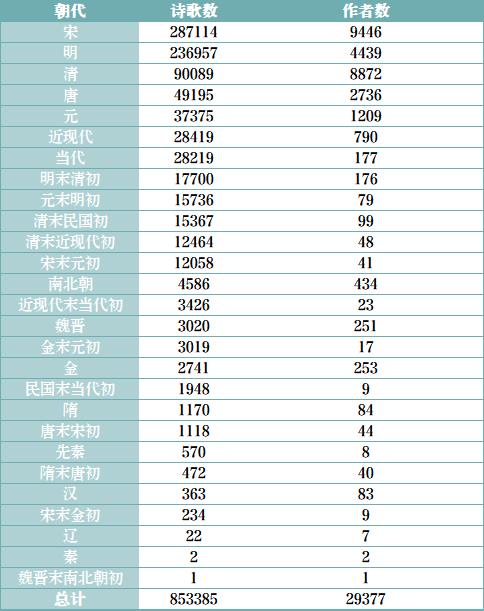
在本文中,笔者循着这个思路,将运用若干文本挖掘方法对手头的诗歌语料库(该诗歌原始语料库地址为https://github.com/Werneror/Poetry)进行深入挖掘和分析,该诗歌语料库的基本统计数据如下:
从上表可以看到,该诗歌语料库中共计近85万余首诗歌,诗歌作者数量达29377位之多;其中,字段包括“题目”、“朝代”、“作者”和“内容(诗歌)”。
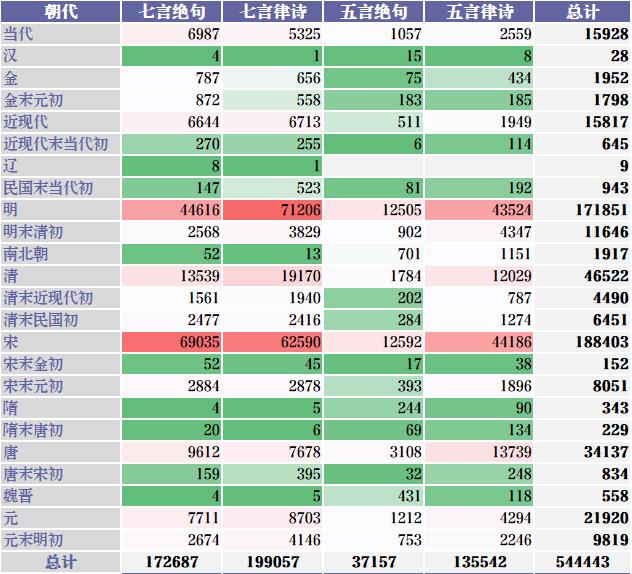
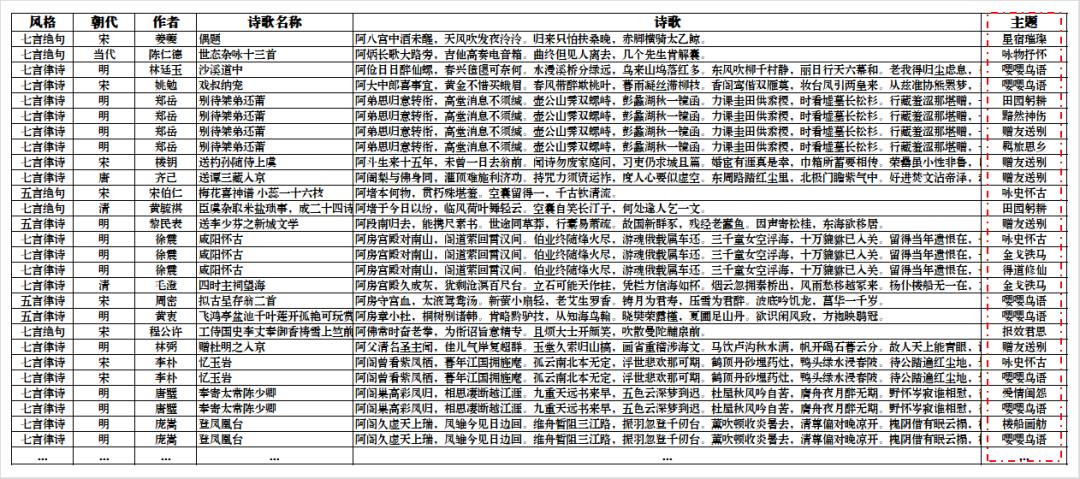
为了方便后续的分析,笔者仅取其中的律诗和绝句,且仅取其中的五言和七言,排律(如《春江花月夜》、《长恨歌》等)、杂言(如李白的将进酒)等就不在本文的分析范围之内。
经过数据清洗后,最终得诗504,443,占到原数据库的59.1%。以下分别是清洗后的诗歌数据统计结果和部分样例:
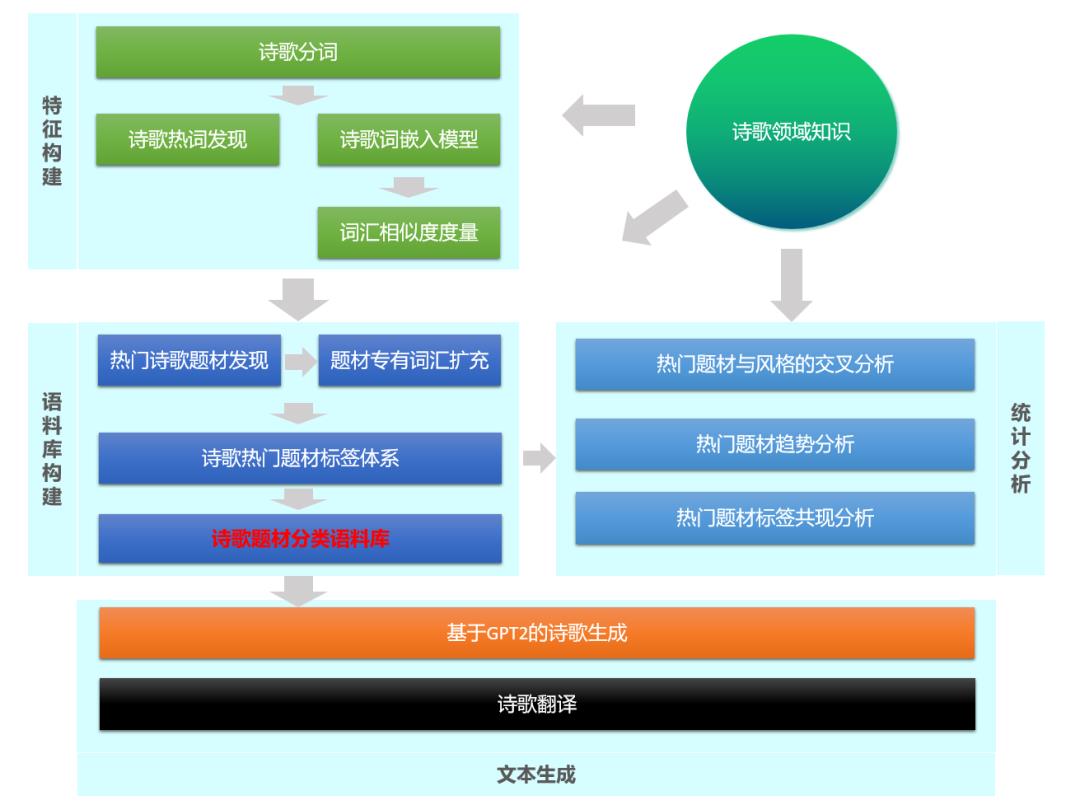
针对上述目标,本文的实现路线图,同时也是本文的行文脉络,如下所示
(点击图片可放大查看):
值得注意的是,上述实现路径中,涉及到自然语言处理的两大组成部分,即自然语言理解(分词、语义建模、语义相似度、聚类和分类等)和自然语言生成(诗歌生成和诗歌翻译), 看完也会对自然语言处理有一定的了解。信息量大,请耐心享用~
给定一首诗歌文本,在其中随机取一个片段,如何判断这个片段是否是一个有意义的词汇呢?
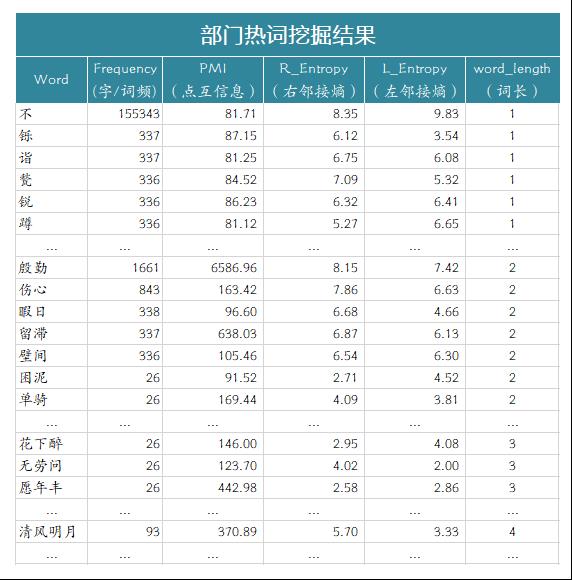
如果这个片段左右的搭配变化较多、很丰富,同时片段内部的成分搭配很固定,那么,我们可以认为这个片段是一个词汇,比如下图中所示的“摩诘”就是符合这个定义,那么它就是一个词汇。
在具体实施的算法中,
衡量片段外部左右搭配的丰富程度的指标叫“自由度”,可以用(左右)信息熵来度量;而片段内部搭配的固定程度叫“凝固度”,可以用子序列的互信息来度量。
在这里,笔者利用Jiayan(甲言)对这54余万首诗歌进行自动分词,在结果中按照词汇出现频率从高到低进行排序,最终从语料库中抽取若干有意义的高频词。其中,词汇的长度从1到4。
笔者观察其中部分结果,发现一字词、二字词才能算得上一般意义上的词汇,如“不”、“烁”、“岁寒”、“留滞”等 ;三字词和四字词一般是多类词性词汇的组合,严格上讲,应该算作短语或者固定表达,如“随流水”、”云深处”、“人间万事”、“江湖万里”等。但本文为了表述方便,笔者将它们统一称之为词。
下面,笔者分别展示词长从1到4的TOP100的高频词词云(点击图片可放大查看)。
一字高频词中,除去“不”、“无”、“有”这类“虚词”,单看“人山风日天云春花年月水”这11个高频字,暗合了中国天人合一哲学传统,作诗如作画,作诗者是把人放到自然环境、天地岁月这个时空大画卷中,七情六欲、天人感应,诗情画意就由感而生,诗意盎然了!
二字高频词中,较为显眼的是“万里”、“千里”,它们描绘出巨大的空间感,在诗歌中经常跟“宏景”“贬谪”、“思乡”、“闺怨”等主题捆绑在一起。
此外,“明月”、“故人”、“白云”、“功名”、“人间”、“平生”和“相逢”等词汇也是横亘古今的热门用语。
三字高频词中,数字的使用很是常见,如“二三子”、“二十四”、“一樽酒”、“二千石”等。其中,最值得一提的是诗人们用数词对时空的描绘:表达时间跨度的,如“二十年”、“四十年”、“五百年”、“十年前”、“千载后”等;表达空间距离的,如“千里外”、“三百里”、“百尺楼”...古人总是喜欢把自己置身于浩瀚渺茫的时空之中,去思考自己匆匆的人生。正如东坡在《赤壁赋》的感慨:“
寄蜉蝣于天地,渺沧海之一粟。哀吾生之须臾,羡长江之无穷!
”
在四字高频词中,空间方位的词汇较多,如“南北东西”、“江南江北”、“东西南北”等词。因四字词词长较长,像“人间万事”、“千岩万壑”、“明月清风”、“白云深处”、“相逢一笑”等词就拥有较高的信息量,能够还原大部分的诗歌意境了。
2 训练含纳诗歌词汇语义关联性的词嵌入模型
词嵌入模型可以从海量的诗歌文本中自动学习到字词之间的关联关系,据此可实现字词关联度分析、字词相似度分析、聚类分析等任务。
然而,计算机程序不能直接处理字符串形式的文本数据,所以笔者首当其冲的一个步骤就是将诗歌文本数据分词,之后再“翻译”为计算机可以处理的数据形式,这由一个名为“文本向量化”的操作来实现。
先谈分词,它跟前面的高频词挖掘有联系,是后续所有分析任务的起始点。
结合前面积累的词库,再基于有向无环词图、句子最大概率路径和动态规划算法对这54万首诗歌进行分词操作。现试举一例:
“万物生芸芸,与我本同气。氤氲随所感,形体偶然异。丘岳孰为高,尘粒孰为细。忘物亦忘我,优游何所觊。”
['万物', '生', '芸芸', ',', '与', '我', '本', '同', '气', '。','氤氲', '随', '所', '感', ',',
'形体', '偶然', '异', '。', '丘岳', '孰', '为', '高', ',', '尘', '粒', '孰', '为', '细', '。',
'忘', '物', '亦', '忘我', ',', '优游', '何', '所', '觊', '。']
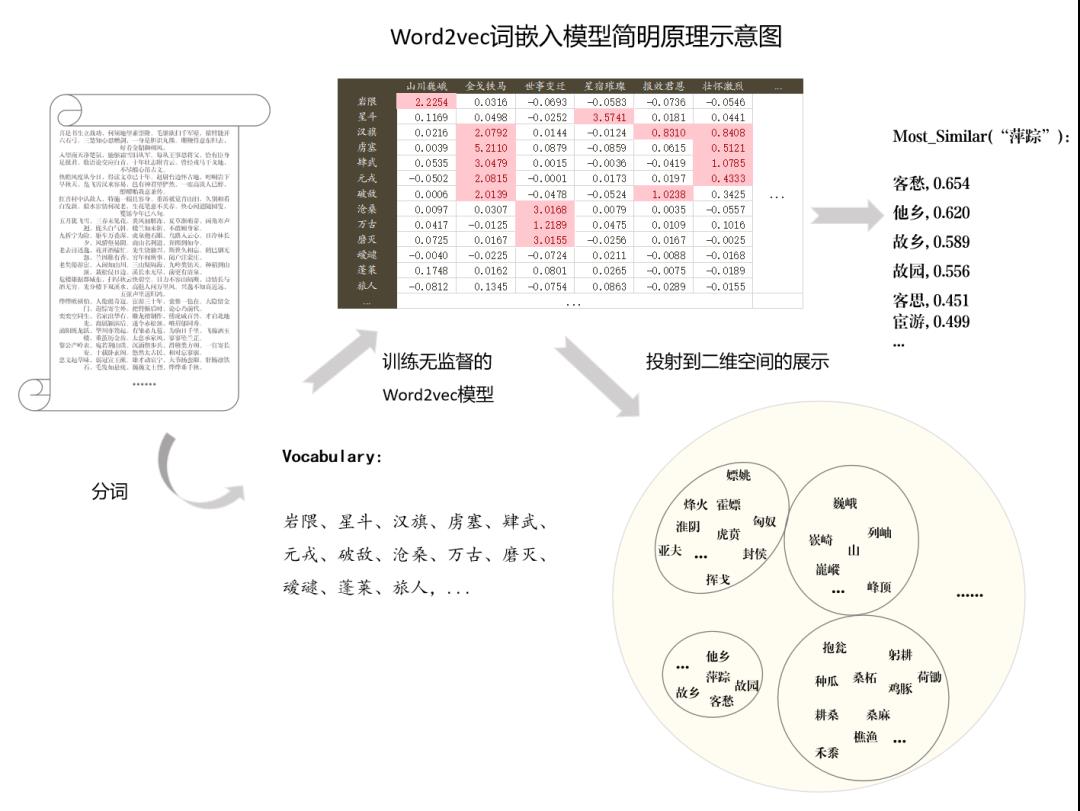
分词之后再做适当处理就可以“喂给”词嵌入模型(这里是Word2vec)进行训练了。
基于Word2vec词嵌入模型能从大量未标注的文本数据中“学习”到字/词向量,而且这些字/词向量包含了字词之间的语义关联关系(可以是语义相关或句法相关),正如现实世界中的“物以类聚,类以群分”一样,字词可以由它们身边的字(上下文语境)来定义,而Word2vec词嵌入模型恰恰能学习到这种词汇和语境之间的关联性。
训练完该模型后,将其训练结果投射到三维空间,则是如下景象
(点击图片可放大查看)
:
在训练Word2vec的过程中,模型会从大量的诗歌文本数据中学习到词汇之间的2类关联关系,即
聚合关系
和
组合关系
。
聚合关系
:如果词汇A和词汇B可以互相替换,则它们具有聚合关系。换言之,如果词汇A和词汇B含有聚合关系,在相同的语义或者句法类别中可以利用其中一个来替换另一个,但不影响对整个句子的理解。例如,“萧萧”、“潇潇”都是象声词,多用于描述雨声,具有聚合关系,那么“山下兰芽短浸溪,松间沙路净无泥,萧萧暮雨子规啼”中的“萧萧”可以换做“潇潇”。
组合关系
:如果词汇A和词汇B可以在句法关系上相互结合,那么它们具有组合关系。例如,“雨打梨花深闭门,忘了青春,误了青春。赏心乐事共谁论?”中的“忘了”和“误了”都和“青春”存在组合关系,都是“动词+名词”的动宾结构。
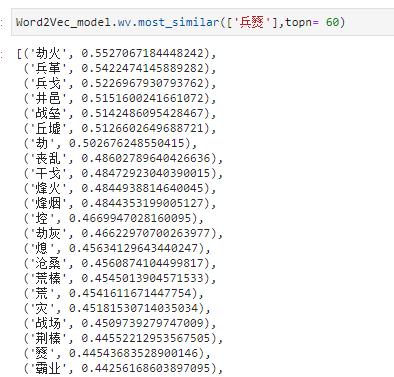
结果大都是跟“战争”&“创伤”相关的词汇,语义关联关系捕获能力较强,后续的热门诗歌体裁挖掘任务也会用到词嵌入模型的这个特性。
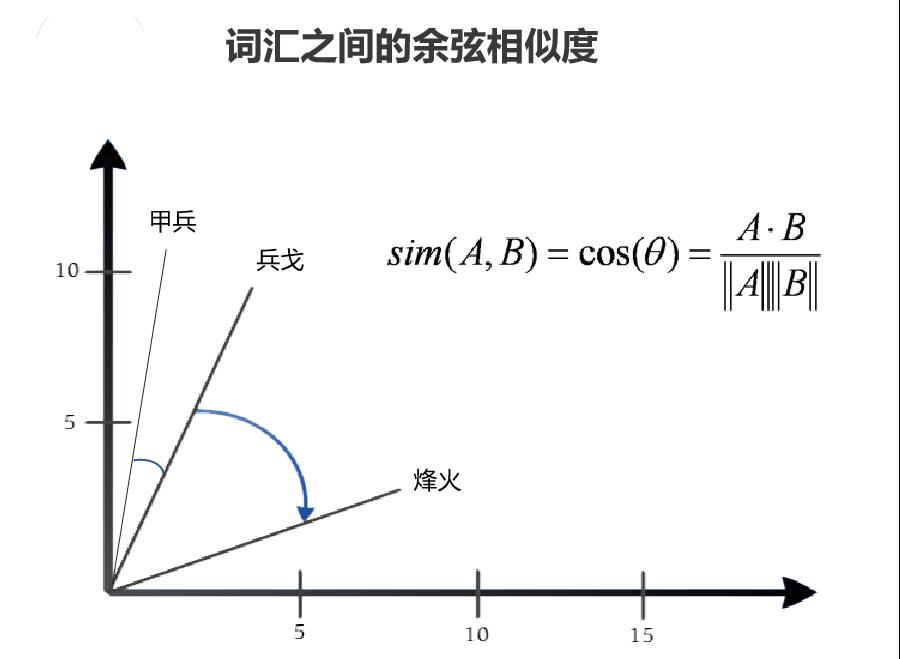
度量词汇之间的相似度或者关联度,我们一般会使用两个词汇的词向量之间的余弦值,词向量之间的夹角越小,则余弦值越大,越接近1,则语义相关度越高;反之,相关度越低。
如下图所示,展示了“甲兵”、“兵戈”和“烽火”之间的余弦相似度的可视化示意图
(点击图片可放大查看)
:
通过上述词嵌入模型,similarity(“甲兵”,“兵戈”) = 0.75,similarity(“甲兵”,“烽火”) = 0.37,similarity(“兵戈”,“烽火”) = 0.48。则在这三个词汇中,“甲兵”和“兵戈”之间的语义相关度最高,其次是“兵戈”和“烽火”,最次的“甲兵”和“烽火”。
这种给一个数值来识别词汇相关不相关的方法优点在于表达简洁、计算高效,比如接下来将要进行的热门诗歌题材发现/聚类。但是,这种词汇相关度的计算没有把词汇之间的相关度的“因果路径”直观的反映出来。
那么,有没有一种直观的方法来展示词汇之间的语义相关性,并且能看到为什么它们是存在这样的关联关系(也就是找到词汇关联路径或者语义演变路径)?
我们需要把这个找寻词汇语义演变路径的任务转换成一个TSP问题(旅行商问题)。
TSP问题(Traveling Salesman Problem)又译为旅行推销员问题,是数学领域中著名问题之一。假设有一个旅行商人要拜访n个城市,他必须选择所要走的路径,路径的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。路径的选择目标是要求得的路径路程为所有路径之中的最小值。
回到词汇相关度度量的问题上来,如果我们能在上述训练得到的词嵌入空间中找到两个词汇之间的最短“语义演变”线路,我们就能直观的呈现出这2个词汇之间产生语义关联的“前因后果”。
要实现这个目的,有一个很棒的算法可以实现 --- A*算法(A* search algorithm)。
A*算法,也叫A*(A-Star)算法,是一种静态路网中求解最短路径最有效的直接搜索方法,也是解决许多搜索问题的有效算法。算法中的距离估算值与实际值越接近,最终搜索速度越快。
下图中
(点击图片可放大查看)
,网状结果即是之前构建的word2vec词嵌入空间,节点是其中分布的词汇,边由字词之间的余弦相关度构成。
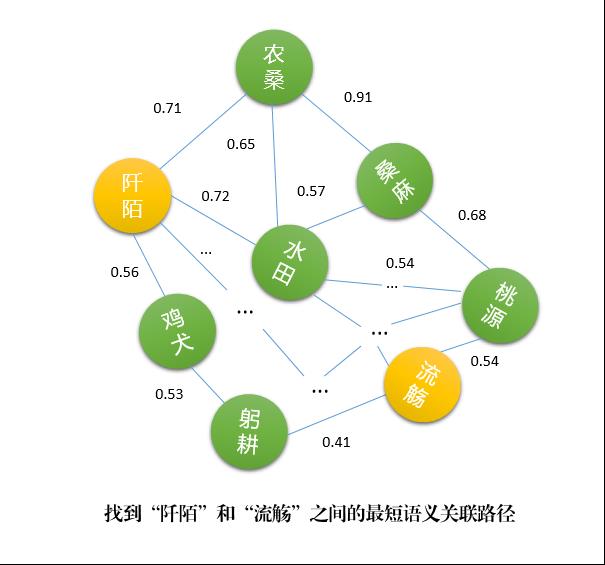
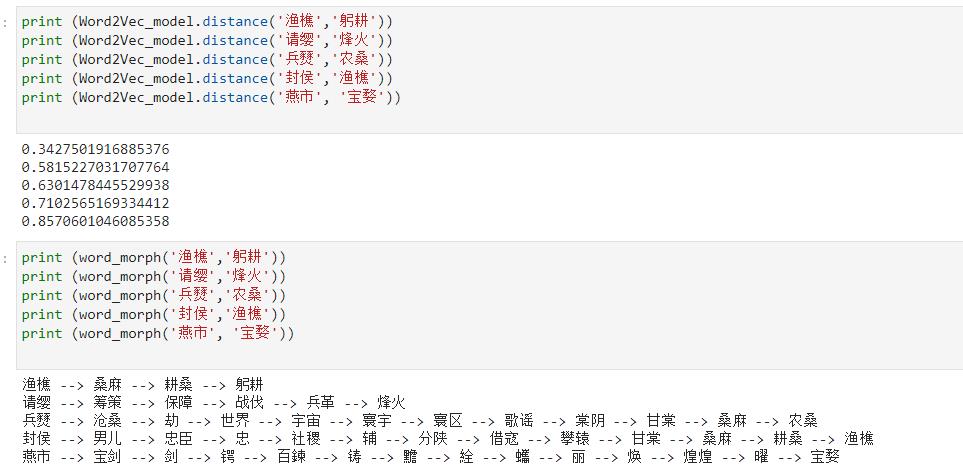
笔者基于上面的词嵌入模型,结合A*算法来计算两个词汇之间的最短语义路径,部分结果如下所示(点击图片可放大查看):
在上图的5个词汇对中,“渔樵”和“躬耕”之间的语义距离最短,也就是语义相关度最高,它们之间的语义演变路径也就越短,中间只隔了2个词汇;“燕市”和“宝婺”的语义距离最大,语义相关度最小,二者的语义演变路径隔了12个词汇。
可以看到,
语义关联性越弱(distance值越大)的两个词汇之间的最短语义演变路径就越长,反之越短,所以语义距离与语义演变路径长度呈正相关关系,语义关联度与语义演变路径呈负相关关系。
有了前面的词嵌入模型和语义相关度做“铺垫”,后续的热门诗歌题材发现就水到渠成了~
先开宗明义,在本文中,关于“诗歌题材”中的“题材”二字的定义,笔者认为是:
作为诗歌创作材料的社会生活的某些方面,亦特指诗人用以表现作品主题思想的素材,通常是指那些经过集中、取舍、提炼而进入作品的生活事件或生活现象。一言以蔽之,写景、摹物、抒情、记事、明理皆是“题材”。
因为事先不知道这54万余首诗歌中到底会存在多少个题材,所以笔者选取的聚类算法没有预设聚类数这个参数,且兼顾运行效率和节省计算资源,能利用前面训练好的word2vec词嵌入模型和语义关联度计算。
此时,有个很好的选择 --- 社区发现算法中的Infomap。
字词是承载诗歌题材的最小语义单元,如“五云山上五云飞,远接群峰近拂堤。若问杭州何处好,此中听得野莺啼”,看到其中的“五云山”和“群峰”,则可以给该诗打上一个“山川巍峨”的题材标签。由此,笔者接下来会基于社区发现算法,结合“词汇簇群--->词汇簇群语义特征--->题材标签”的思路来发现热门诗歌题材。
我们知道,在社交网络中,每个用户相当于每一个点,用户之间通过互相的关注关系构成了整个线上人际网络。
在这样的网络中,有的用户之间的连接较为紧密,有的用户之间的连接关系较为稀疏。其中连接较为紧密的部分可以被看成一个社区,其内部的节点之间有较为紧密的连接,而在两个社区间则相对连接较为稀疏。
基于社区发现算法的话题聚类/发现,在于挖掘词汇语义网络中居于头部的大型“圈子”。
将词汇拟人化,词汇之间存在的相似度/关联度可以视为词汇之间的亲密程度,那么,诗歌题材发现任务可以看做是找到不同成员组成的“圈子”,圈子的特性可以根据其中的成员特征来确定,换言之,题材的名称可以根据其中聚合的词汇的内涵来拟定,比如某个词汇簇群中包含“卫霍”、“甲兵”、“征战”等词汇,那么这个题材可以命名为“战争”。
示意图如下所示
(点击图片可放大查看)
:
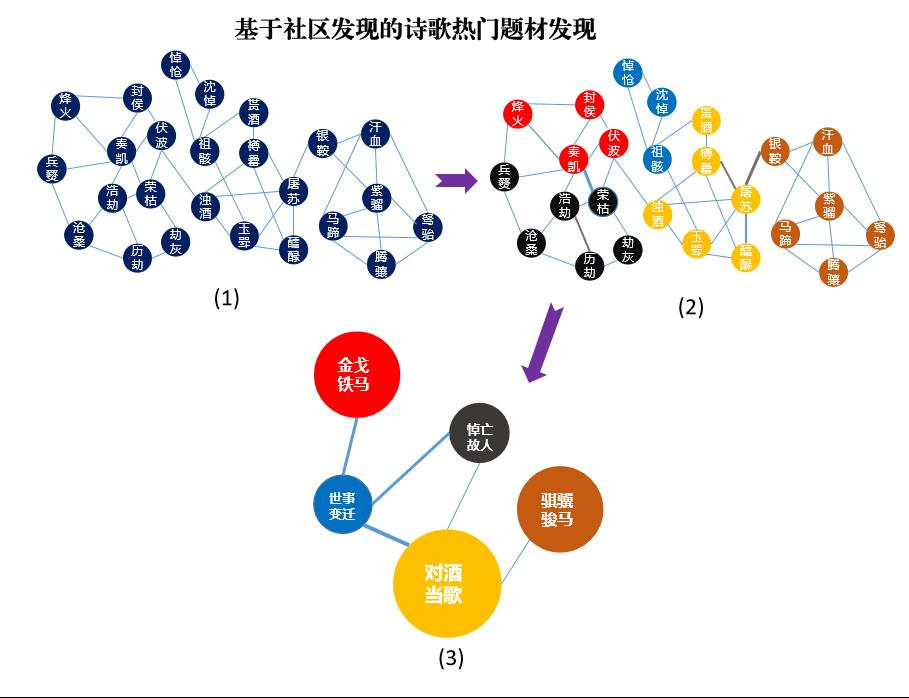
运行社区发现算法后,居于头部的热门题材词汇簇群的可视化呈现如下
(点击图片可放大查看)
:
其中,不同颜色表征不同的题材,字体大小代表其出现频次,词汇之间的距离远近表征其相关程度大小。
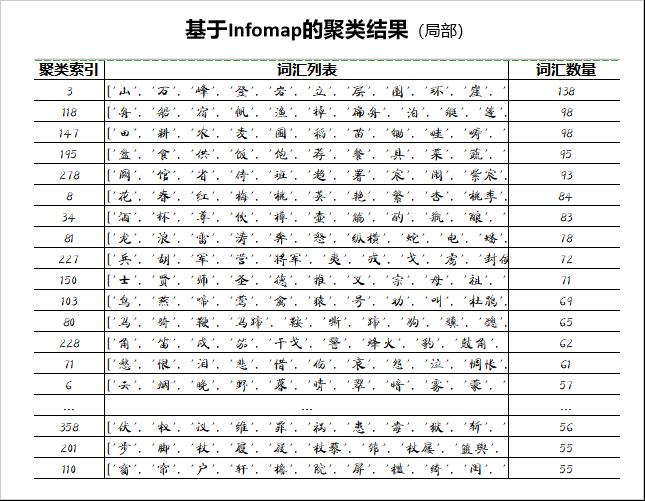
经聚类得到634个题材,根据热度(题材下辖词汇数量)的降序排列呈现最终结果,如下所示
(点击图片可放大查看)
:
在这一环节中,笔者的在于根据一些诗歌领域知识,找到上述运行结果中热门题材及其下辖的题材专属性词汇。其中,“题材专属性词汇”的内涵主要有以下两点:
根据笔者在前文中的定义,写景、摹物、抒情、记事、明理皆是“题材”,这里的热门题材甄别采取“抓大放小”的原则。
此外,虽然聚类出的结果较为理想,但还是存在些许噪音,比如,出现少许跟题材相关性不强的词汇、题材区分度较低的词汇、词汇簇群中的词汇过少(如低于10个)等,这些都是需要被刨除掉的情况。
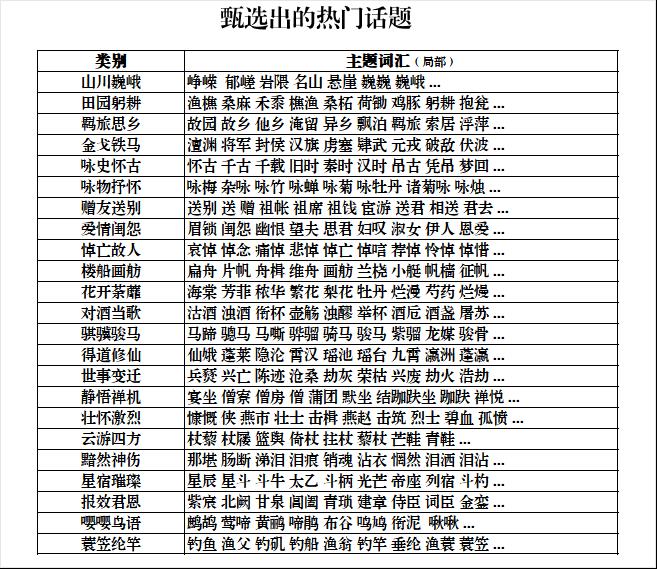
经过笔者的仔细甄别,共甄别出23个热门诗歌题材,分别是
山川巍峨、田园躬耕、羁旅思乡、金戈铁马、咏史怀古、咏物抒怀、赠友送别、爱情闺怨、悼亡故人、楼船画舫、花开荼蘼、对酒当歌、骐骥骏马、得道修仙、世事变迁、静悟禅机、壮怀激烈、云游四方、黯然神伤、星宿璀璨、报效君恩、嘤嘤鸟语、蓑笠纶竿
等,当然这些并不是全部的题材,限于笔者学识,仍然有大量题材没有发掘出来。枚举部分结果如下
(点击图片可放大查看)
:
在这一环节,笔者根据对诗歌背景知识的了解,筛选出部分热门诗歌题材,并形成题材对应的关键词规则体系,后续可用于对这54万余首诗歌进行基于关键词的诗歌题材分类。
值得注意的是,由于这一环节挑选关键词过于苛刻,导致数量较少,规则体系不甚健全。所以,在对诗歌语料库进行正式的诗歌题材分类前,笔者需要使用一些“小手段”,对上述热门题材的关键词规则进行扩充。
在这里,笔者先利用已得到的热门题材分类体系及其关键词规则给这54万余首诗歌打上题材标签,允许出现同一首诗歌命中多个标签的情形。除去其中未命中题材标签的数据,共计443,589行,其中多数诗歌打上了2个及以上的题材标签。
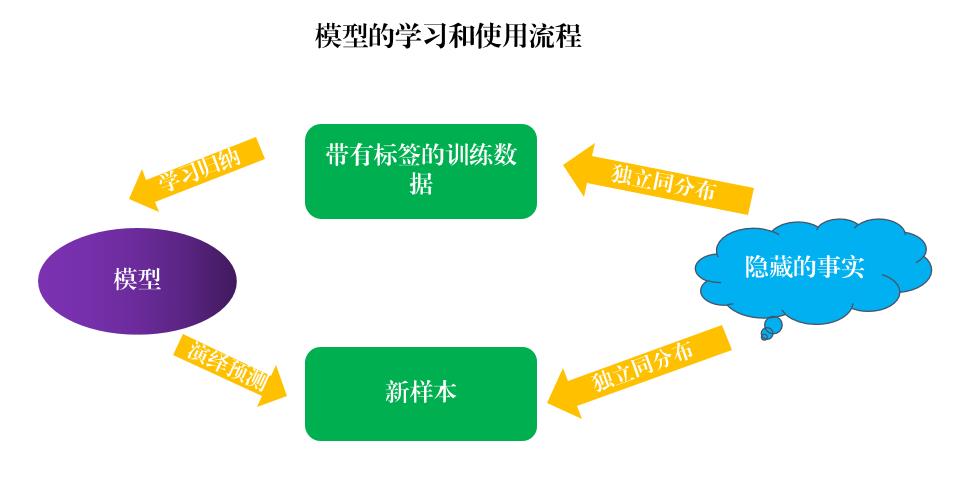
有了带标签的数据以后,笔者将多标签问题转换为单标签问题,再将上述诗歌文本及其对应的标签“喂进”线性分类器,根据线性分类器的权重来找到每个类别下最具代表性的词汇,也就是题材专有性词汇。这里选择线性分类器而不是时下流行的深度学习分类器的原因就在于它的可解释性,能让我们清楚的知道是哪些显著的特征(此处是词汇)让诗歌分到这个题材类别下的。其大致原理如下图所示(
点击图片可放大查看
):
在笔者测试的众多线性分类器中,即RandomForestClassifier、Perceptron、PassiveAggressiveClassifier、MultinomialNB、RidgeClassifier、SGDClassifier,RidgeClassifier的区分效果最好,其F1_score为0.519,鉴于是词袋模型,语义表示较为简单,且原本是多标签分类任务,这个结果尚可接受。基于RidgeClassifier的特征词汇权重的降序排列结果,可得到上述23个热门诗歌题材分类中的若干题材专有性词汇,部分结果展示如下(
点击图片可放大查看
):
这样,各个类别各取TOP500词汇,经过笔者的甄别和梳理后,各个题材关键词规则得到了不同程度的扩充,使得该分类标签体系可以较好的辅助完成诗歌题材多标签分类任务,且后续可以结合分类结果做不断的扩充。
基于这个更加完善的诗歌题材分类体系,笔者运行完之后得到58W+行数据,在之前的基础上增加了14W+行数据,数据规模提升明显!
至此,笔者第一个目标,即热门诗歌题材标签语料库构建完毕,后续的文本挖掘任务可以在此基础上进行。
由分类标签及其分类模型反向推导其中最具代表性的特征词汇,这是一个“数据--->规律”的归纳过程,很好的体现了数据驱动思维;而模型将学习归纳得到的“经验”推广到新样本的标签预测任务中,则体现了“规则--->数据”的演绎过程。
针对上述58W+行数据构成的诗歌题材语料库,将其中的题材分类标签和各类meta data(如风格、朝代、作者等)做交叉分析,得到很多有意思的分析结果。
将诗歌数据集的风格标签和题材标签进行交叉列表的成分占比分析,得到的结果如下(点击图片可放大查看):
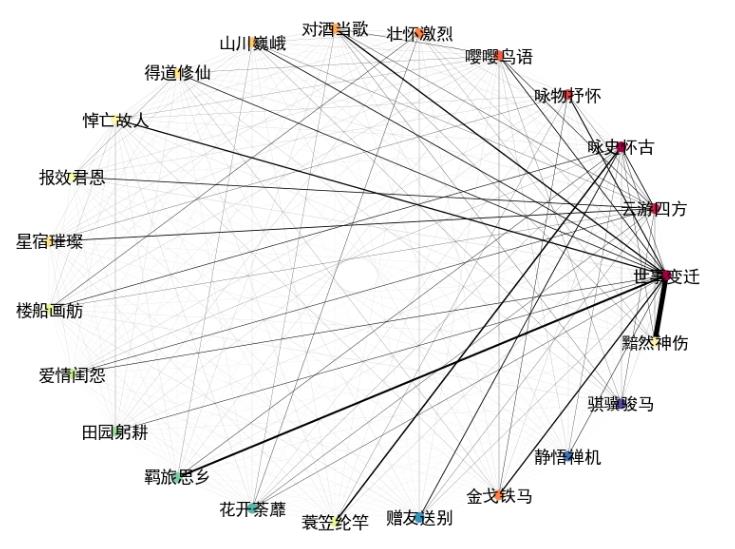
前面的诗歌题材分类是多标签分类,也就是可能会出现同一首诗歌对应多个题材标签的情况。在这种情况下,我们可以进行题材标签的共现分析,也就是多次同时出现的题材标签,它们之间会存在一定的关联性。
现对标签共现的情况进行建模,得到的结果可视化呈现如下所示
(点击图片可放大查看)
:
上图中,线条的粗细表示共现的频次多寡,越粗表示共现频次越高,反之越低。其中,有几对标签对的共现频率较高:
其中,“黯然神伤”和“世事变迁”的相关性最高,这个很好理解,毕竟“
物是人事事休,欲语泪先流
”,类似因感叹逝事而伤感的诗句还有“
人世几回伤往事,山形依旧枕寒流
”、“
一生事业总成空,半世功名在梦中
”;“羁旅思乡”和“世事变迁”之间的相关性第二高,此类的诗句有“
少小离家老大回,乡音无改鬓毛衰
”、“
去日儿童皆长大,昔年亲友半凋零
”等。
此外,我们也可以发现,在出现2个及两个以上题材标签的诗歌中,“世事变迁”和其他题材同时出现的概率很大:世事变迁可能导致诗人黯然神伤;也可能是战争导致兵连祸结,产生出“
兴,百姓苦,亡,百姓苦
”的感慨;抑或是“
桃李春风一杯酒,江湖夜雨十年灯
”的对酒当歌。
6.3 诗歌题材趋势分析
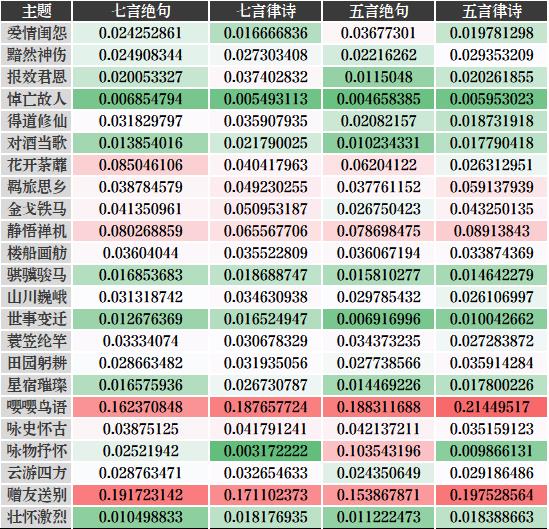
笔者将诗歌数据集中的朝代按照时间顺序由远及近进行排列,并合并其中年代接近的朝代,将其与23个热门诗歌题材做(占比)交叉分析,得到下图
(点击图片可放大查看)
:
在上图中,可以分别从横向维度(朝代)和纵向(诗歌题材)维度来看。
从横向维度上看,有两个题材经久不衰,即“赠友送别”和“嘤嘤鸟语”。
古时候由于交通不便,通信极不发达,亲人朋友之间往往一别数载难以相见,所以古人特别看重离别。离别之际,人们往往设酒饯别,折柳相送,有时还要吟诗话别,因此“赠友送别”就成为古代文人吟咏的一个永恒的题材。在这浓浓的感伤之外,往往还有其他寄寓:或用以激励劝勉,如“莫愁前路无知己,天下谁人不识君”;或用以抒发友情,如“桃花潭水深千尺,不及汪伦送我情”;或用于寄托诗人自己的理想抱负,如“洛阳亲友如相问,一片冰心在玉壶”;甚至洋溢着积极向上的青春气息,充满希望和梦想,如“海内存知己,天涯若比邻”。
“嘤嘤鸟语”题材的诗歌一般用“比兴”的手法来寄寓自己的情感,笔者所了解的有两类:一是通过写鸟语描摹诗人淡薄、回归山野自然的平静心境,这方面的诗王摩诘写的最多,如“月出惊山鸟,时鸣春涧中”、“漠漠水田飞白鹭,阴阴夏木啭黄鹂”、“雉雊麦苗秀,蚕眠桑叶稀”等;二是通过子规(杜鹃)、鸿雁等意象来表达诗人淡淡的忧伤,如“杨花落尽子规啼,闻道龙标过五溪”的依依惜别之情、“两边山木合,终日子规啼”的思乡归家之情、“雁尽书难寄,愁多梦不成”的思君心切...
从纵向维度上看,隋末唐初时期除了上述提及的两大热门题材外,关于“报效君恩”题材的诗歌占比较高。彼时适逢华夏第三次大一统,“贞观之治”、“开元之治”这两大盛世荣耀大唐在“朕即国家”的时代,广大热血青年渴望驰骋疆场,建功立业,报效国家。
此外,笔者也注意到,
从金代到到当代,“花开荼蘼”、“羁旅思乡”、“金戈铁马”和“静悟禅机”等题材就一直葆有较高的热度,结合前面提及的2大经久不衰的诗歌题材,这表明这段时期的诗歌创作方向具有一定的延续性。
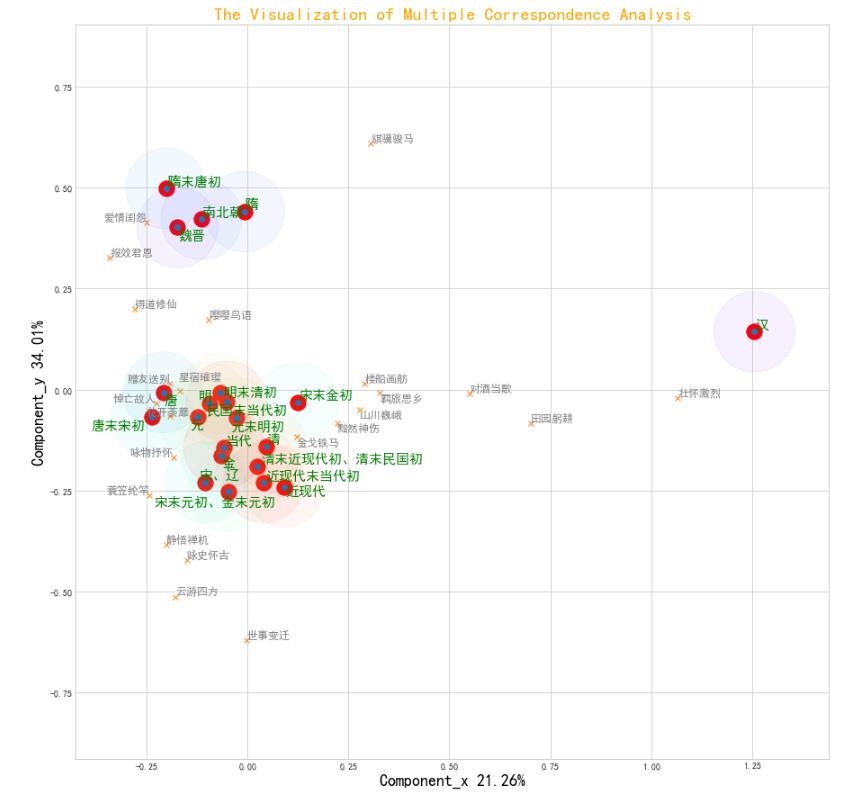
从上表中,我们能有一些发现,但如果想更获取一些更深层次、潜藏在表层数据中的信息,我们还需要用高阶的数据挖掘方法将其转换一下。在这里,笔者使用多元对应分析的方法将其高维表示(也就是上面的21*23维的图表)映射为二维表示(分解为2个二维矩阵,题材为23*2,朝代为21*2),从而更直观的揭示出诗歌题材之间、诗歌题材与朝代之间的关联关系,如下图所示(点击图片可放大查看):
在上图中,有两类坐标---外围有半径圆圈的红色点是朝代的,“x”的诗歌题材的坐标。
汉代的坐标“孤悬海外”是因为数据量过小,统计特征不甚明显,故笔者在这里不做分析。
在图的左上角,魏晋、南北朝、隋末唐初、隋这几个朝代的圆圈重合度较高,说明它们的诗歌题材数量分布较为相似,联想到这几个朝代前后相继,这又一次体现了诗歌创作具有时代延续性的特征。
同样,
唐代及其以后的圆圈呈“扎堆状”,标明它们的诗歌写作题材的数量分布较为相似,反映出唐以降的朝代在诗歌创作题材方面的差异度较小,题材创作方向的创新性不高。究其原因,在于诗歌在唐代已经进化到“究极状态”:
唐诗的题材和意境也几乎无所不包,修辞手段的运用已达到炉火纯青的程度。它不仅继承了汉魏民歌、乐府传统,并且大大发展了歌行体的样式;不仅继承了前代的五、七言古诗,并且发展为叙事言情的长篇巨制;不仅扩展了五言、七言形式的运用,还创造了风格特别优美整齐的近体诗。近体诗是当时的新体诗,它的创造和成熟,是唐代诗歌发展史上的一件大事。它把我国古曲诗歌的音节和谐、文字精炼的艺术特色,推到前所未有的高度,为古代抒情诗找到一个最典型的形式,至今还特别为人民所喜闻乐见。
唐诗代表了中华诗歌的最高成就,无疑是中华以及世界文坛上浓墨重彩的笔触!这对于想要另辟新境的宋代诗人来说无疑是巨大的压力。正如王安石和鲁迅所言:
“世间好语言,已被老杜道尽;世间俗语言,已被乐天道尽”,
“我以为一切好诗,到唐朝已被做完,此后倘非翻出如来掌心之‘齐天大圣’,大可不必再动手了”。
从某种程度上讲,诗歌生成是从另一维度对诗歌进行深度分析。
生成什么诗歌,跟诗歌生成模型“吃下去”什么是息息相关的。诗歌生成模型的“生成”不是“无源之水”、“无本之木”,它是在充分学习和吸收前人的若干诗作后,习得了一定的“创作手法”,因而能生成效果尚可的诗歌。
同时,我们也能从生成的结果中发现诗歌创作的一些规律,做一些深入探究。
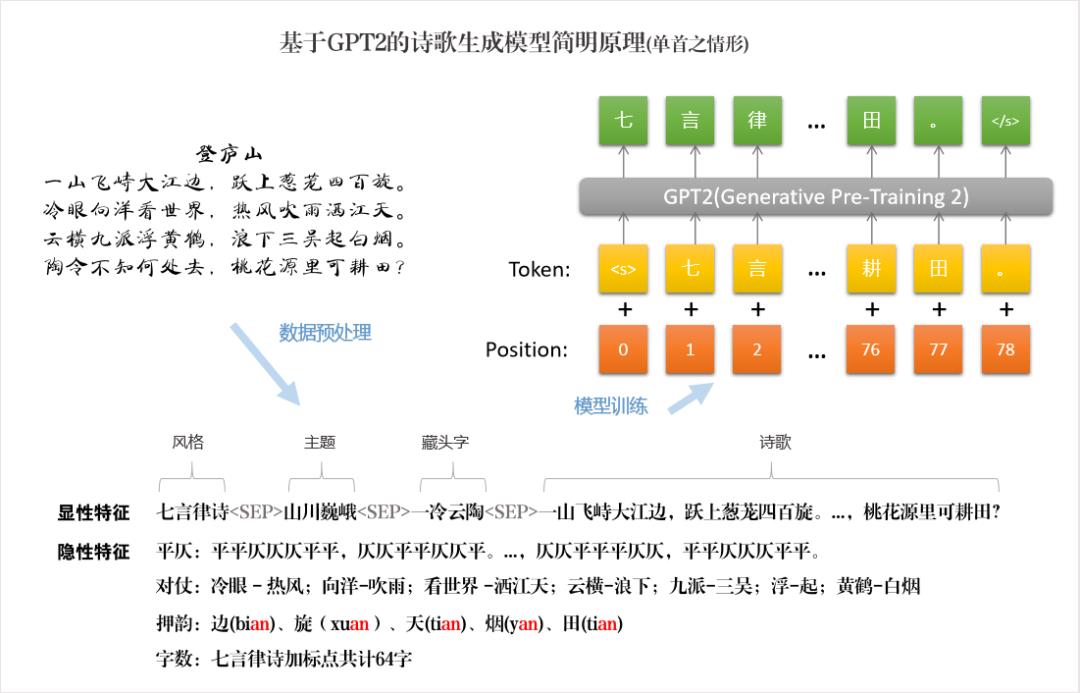
在这一部分,笔者用于训练诗歌生成模型的语料库是基于热门题材标签体系得到的带有题材标签(目前是23个)的律诗(七言和五言)和绝句(七言和五言),它们都满足诗歌的结构性、音调性和语义性的要求。
这里笔者采用的是GPT2(Generative Pre-Training 2nd),它是一个无监督语言模型,能够生成具有连贯性的文本段落,在许多语言建模任务基准中取得了领先级表现(数据量级和参数量级摆在那里,当然跟它的后浪GPT3不能比...)。而且该模型在没有任务特定训练的情况下,能够做到初步的阅读理解、机器翻译、问答和自动摘要。其核心思想可以总结为“给定越多参数以及越多样、越大量的文本,无监督训练一个语言模型或许就可让该模型具备更强的自然语言理解能力,并在没有任何监督的情况下开始学会解决不同类型的 NLP 任务”。
在文本的诗歌生成任务中,笔者从零到一训练一个诗歌生成的GPT2模型,力求让该模型学习到诗歌数据集中的各类显性特征(题材与诗歌的关系、诗歌与风格的关系、藏头字和诗歌的关系等)和隐性特征(主要是诗歌的韵律),其大致原理如下图所示:
相比3年前笔者写时用的LSTM诗歌生成模型,GPT2模型进步巨大:
生成的诗歌更加通顺,每一联的出句和入句的衔接也显得更为自然
能成全局(即整首诗)着眼,记忆能力好,考虑上下文语境,前后生成的诗句紧密关联,不会出现“跳题材”的情况
能学习到诗歌数据中较为隐性的特征,如押韵、平仄、对仗、疑问语气等
因拥有上述3个优势,生成的诗歌“废品率”大大降低
下面,笔者将“花式”呈现GPT2的诗歌生成能力:
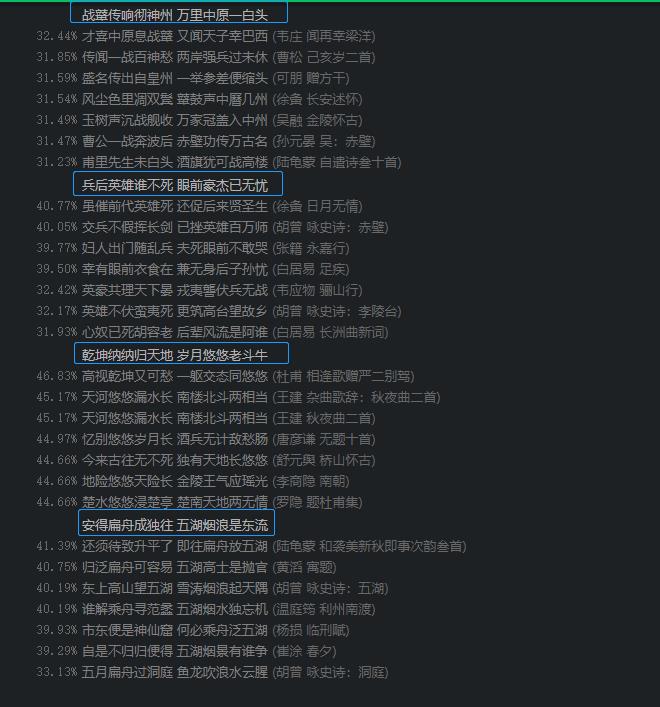
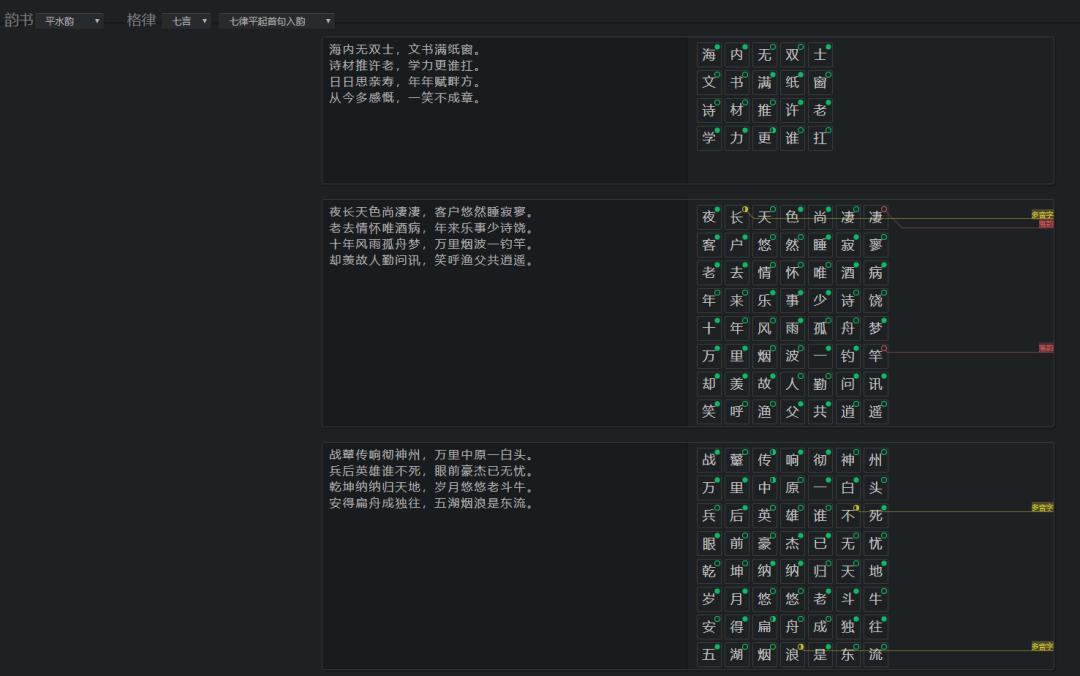
1)生成的诗歌可能会和前人写的诗句有一定的相关性,但是GPT2模型可以进行“魔改”,很难看出直接的“抄袭对象”,例如以下由GPT2模型生成的七言律诗,每一联都能在语料库中找到语义最为接近的一句:
战鼙传响彻神州,万里中原一白头。
兵后英雄谁不死,眼前豪杰已无忧。
乾坤纳纳归天地,岁月悠悠老斗牛。
安得扁舟成独往,五湖烟浪是东流。
2)很多生成的诗歌能较好的学习到韵律,比如符合《平水韵》的用韵规则:
上一个示例就是《平水韵》中七律平起(首句入韵)的一个样例:
即使一些诗歌不是严格的用韵(即一首诗只能押一个韵),也会自动采用邻韵的方式来缓解韵律失和的问题。
3)对人张若虚的乐府旧题《春江花月夜》(因为是乐府诗,字数较多,未参与诗歌生成模型的训练)中的若干诗句,采用对对子的方法生成下联,毫无违和感:
【上联】春江潮水连海平,海上明月共潮生 【下联】
古塔风云绕山青,峰顶彩霞共霭晖
【上联】滟滟随波千万里,何处春江无月明 【下联】
幽幽如幻五十年,此间尘世有风流
【上联】江流宛转绕芳甸,月照花林皆似霰 【下联】
山势氤氲浮翠霭,风梳杨柳欲飞烟
【上联】斜月沉沉藏海雾,碣石潇湘无限路 【下联】
春江漫卷漾烟雨,长河日夜有缘人
【上联】不知江月待何人,但见长江送流水 【下联】
只向渔家寻旧迹,试问何处答耕桑
【上联】白云一片去悠悠,青枫浦上不胜愁 【下联】
碧水千层横漠漠,赤雁南来正飞歌
【上联】鸿雁长飞光不度,鱼龙潜跃水成文 【下联】
渔家小住月相随,鸥鹭往来船载歌
【上联】此时相望不相闻,愿逐月华流照君 【下联】
何处觅人犹有约?欲邀仙子去还家
【上联】江畔何人初见月?江月何年初照人 【下联】
天下有地可藏龙,海风哪处可观心
【上联】江天一色无纤尘,皎皎空中孤月轮 【下联】
杨柳千丝犹有梦,蒙蒙江上满船灯
4)嵌入笔者所在的公司名称---“达观数据”作为藏头字,分别以“山川巍峨”、“得道修仙”、“田园躬耕”为题材,生成三首七言律诗:
《其二》
《其三》
5)在训练和生成式引入更多的诗歌标签信息,如风格、题材和藏头字,引导GPT2朝期望的方向的生成诗歌。训练好模型后,笔者输入诗歌风格(七言绝句、七言律诗)、藏头字(沧海月明)和题材(金戈忒吗、世事变迁、静悟禅机等),生成如下诗歌:
七言绝句<sep>
戢戈为武<sep>
金戈铁马<sep>
戢
兵十万羽林郎,
戈
壁纵横百战场。
为
报将军能破敌,
武
功原是好封疆。
七言律诗<sep>
沧海月明<sep>
金戈铁马<sep>
沧
海干戈一战场,西风吹泪洒衣裳。
海
门万里烽烟息,天地千秋雨露凉。
月
下楼船喧鼓角,夜深笳鼓动旌旗。
明
年此夕登临处,独倚阑干对夕阳。
七言律诗<sep>
沧海月明<sep>
金戈铁马<sep>
沧
波渺渺接长河,极目苍茫感慨多。
海
上楼船三百里,云间楼阁五千过。
月
明古渡渔歌起,秋入荒城鼓角和。
明
日相逢又相别,不堪回首泪滂沱。
七言律诗<sep>
沧海月明<sep>
金戈铁马<sep>
沧
波渺渺白鸥群,极目苍茫万里云。
海
上楼船三万里,天边烽火一孤坟。
月
明古渡渔歌起,霜落空山雁影分。
明
日相逢又相别,故乡回首泪纷纷。
七言律诗<sep>
沧海月明<sep>
世事变迁<sep>
沧
桑劫火几兴亡,回首沧桑感慨伤。
海
上楼台空劫火,人间禾黍自悲凉。
月
明古渡渔歌起,风静寒潮雁影长。
明
日相逢又相别,故乡回首一凄凉。
七言律诗<sep>
沧海月明<sep>
静悟禅机<sep>
沧
浪万顷白鸥群,此地曾经此地分。
海
上楼台今夜月,山中楼阁几秋云。
月
明古寺僧初定,潮落空江雁正闻。
明
日相逢又相别,不知何处是离群。
上述生成结果,平仄符合,押韵亦可,诗意也不错。不敢说很完美,但至少很多人写不出如此观感的诗歌。
此外,上述按题材生成的结果,笔者进行了大量的题材诗歌生成测试,结果表明诗歌题材和生成诗歌之间的关联性较高,这也从侧面验证了笔者上述构建的诗歌题材语料库具有一定的合理性。
此外,笔者还通过生成的诗句发现了古今诗歌表达方面的一些差异,例如,笔者以“金戈铁马”作为生成题材,分别用毛主席《人民解放军占领南京》和陈老总的《梅岭三章》中的首联打头,各生成9首诗歌,结果如下(点击可查看大图):
上面两张图中占据中间C位的是原诗歌,其余的诗歌由毛主席和陈老总诗歌的首联“引导”而成,基本含有“金戈铁马”相关的意象,题材贴合度较高,大都跟征战、戌边、杀敌保国有关,比如:
然而,可能跟学习了大量封建时代的诗歌有关,这些生成的诗歌到末尾大都是一个悲情的基调,略显消极,如以下几句:
上述生成的诗句缺乏革命主义的乐观豪情,这是封建时代的诗歌不具备的特质,但这恰好毛主席和陈老总这两首诗歌的与众不同之处。且看这两句:
“
文章合为时而著,歌诗合为事而作
”,上述的结果也恰恰从侧面体现了诗歌创作具有时代感和现实感,尽管是写同一题材,但由于诗人的人生轨迹和面临的时代背景不一样,胸中所内含的气象也大不相同。
上述由GPT2生成的诗歌看起来都还不错,很多到了以假乱真的地步,这种情况下,我们该如何甄别出其中哪些是人写的,哪些是机器写的?
机器写作诗歌归根到底还是一个
统计学问题
,“解铃还须系铃人”,甄别“真伪”的事情还得统计学来解决。
诗歌生成建模大致的原理是:
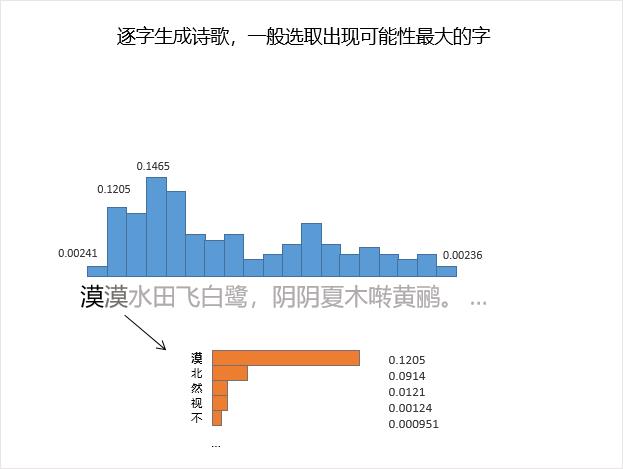
通过大量诗歌语料,诗歌生成模型能学习到任一诗句中相邻的字词之间的依赖关系
,比如出现一个“漠”,GPT2按照学习到的经验,会猜测接下来会出现哪个字,这些字都会以概率的形式“存放”在GPT2模型的“记忆”之中,如:
一般情况下,机器“作诗”时会选择过往出现几率最高的字,以此类推,直到碰到“终止符”才结束,逐渐生成整首诗歌。
这是最简单的情形,生成的效果也就非常一般,很多时候是文理不通。
为了保证生成效果,一般会(同时)用到一些复杂的生成策略,如Beam Search、Top-k sampling、Top-p sampling(NUCLEUS SAMPLING,核采样)、Repetition_penalty(对重复性进行惩罚)、Length_penalty(对生成过长的诗句进行惩罚)等,这样会兼顾诗歌生成的一些其他因素,如流畅度、丰富度、一致性等,诗歌生成的效果也能得到较大的提升。
笔者基于哈佛大学的
GLTR( Statistical Detection and Visualization of Generated Text)
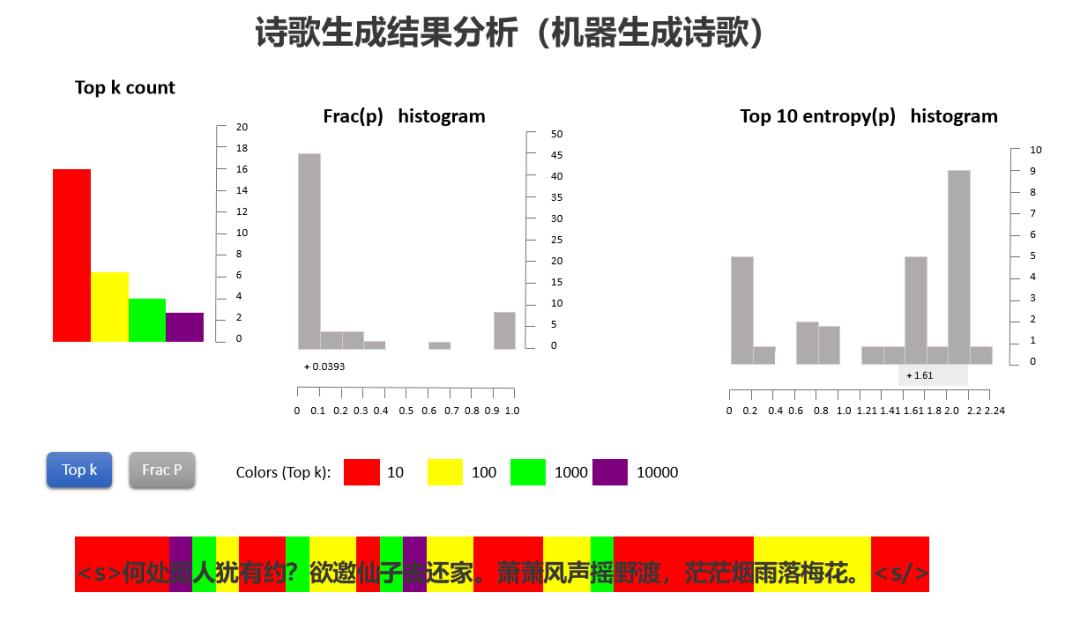
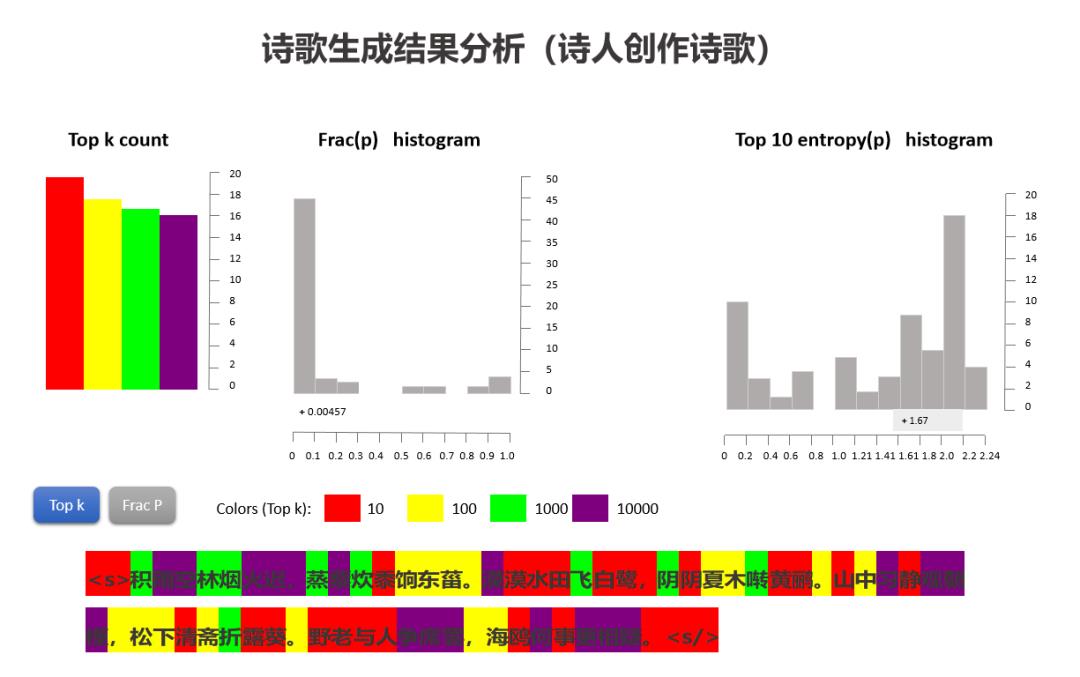
来探究下机器和人作诗时的一些差异,该工具输入的是诗歌,输出的是机器和人作的诗歌的字出现概率分布统计,我们从中可以发现诗歌“炼字”的一些奥秘。笔者试举一例:
在上图中,色块的颜色代表的是字所在的概率区间,红色代表出现概率TOP10的字,黄色的是TOP100,绿色的是TOP1000,紫色的是TOP10000。
从结果中,我们可以看到机器作诗时,红色和黄色的字概率分布区间占比较大,逐字生成时一般是从头部的字概率分布中来取,从而导致会诗句生成较为常见的表达;人创作诗歌时,各颜色代表的字概率分布区间占比较为接近,至少是差异不大,最终导致诗歌的表达千变万化,不落俗套。
古时诗人作诗,重在“炼字”。炼字,指锤炼词语,指诗人经过反复琢磨,从词汇宝库中挑选出最贴切、最精确、最形象生动的词语来描摹事物或表情达意。从这个角度来看,具有统计学意义的“选字”策略基本不可取 --- 不是词不达意就是容易落“俗套”。
比如,
陶渊明的那句“采菊东篱下,悠然见南山”中“见”换成“望”就不好。虽然按从诗歌数据集学到的概率来讲,“望”在过往出现的概率远大于“见”,但“见”通“”现,有“无意中看见”的含义,标明作者是不经意间抬起头来看见南山,表达了整个诗句中那种悠然自得的感触,好像在不经意间看到了山中美景,符合“山气日夕佳,飞鸟相与还”这种非常自然的、非常率真的意境,而“望”则显得有些生硬
。
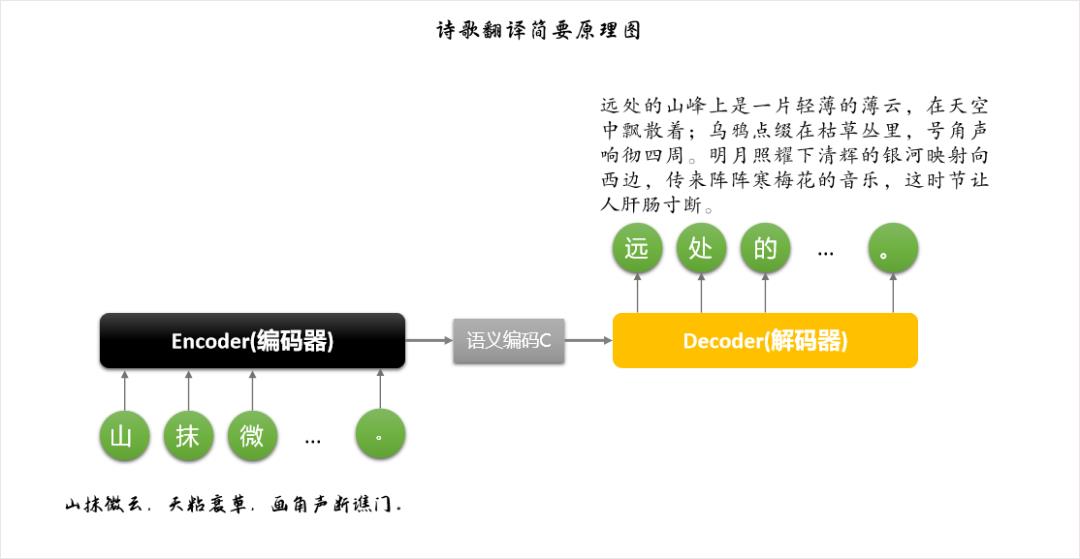
诗歌翻译,也就是将文言文色彩浓重、一般人不易看懂的诗歌翻译成现代人容易理解的白话文。
笔者此处用到的模型是两个BERT构成的Encoder-Decoder,目标是输入一句或者一首诗歌,生成相应的白话文翻译。
考虑到古现代汉语存在大量词汇方面的语义延续性,不像中英互译这样,源语句和目标语句之间的语义和语法结构差异极大,它们会有很多共享词汇,所以训练的语料数量可以适当少些。诗歌翻译模型会从大量的翻译语句对中学习到它们之间的语义对应关系,而且是以较为流畅(较理想的情况下)的形式进行输出
。
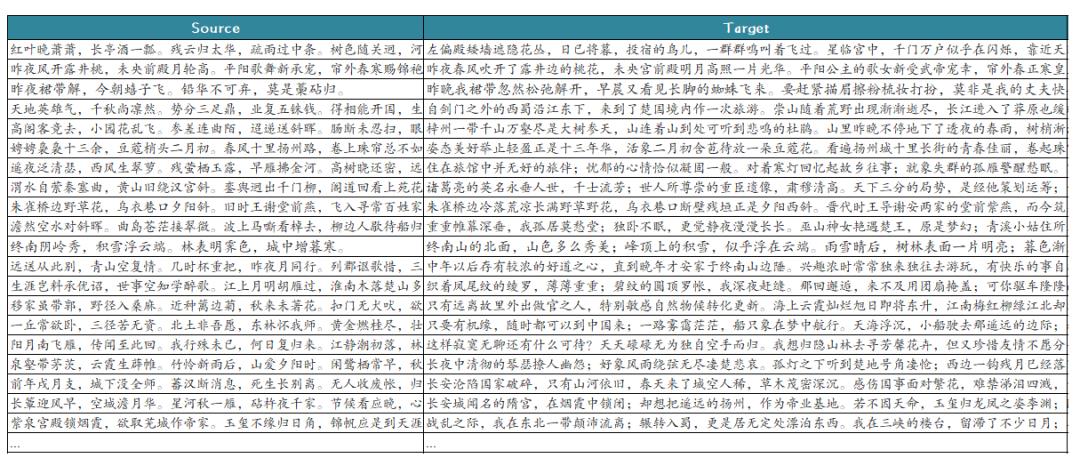
笔者编写爬虫采集了某诗歌分享网站上的若干诗歌及其翻译数据,经清洗后,得到3万条训练语句。
训练模型后,笔者选取部分未出现在训练集中的语句作为文本翻译的示例,部分示例如下:
【词】问君何事轻离别,一年能几团圆月。杨柳乍如丝,故园春尽时。(菩萨蛮·问君何事轻离别,清,纳兰性德)
【翻译1】
你在什么时候才能够回家?只有那美丽的桃花已经过去了。
【翻译2】
请你问我为什么这样的轻易消失呢?一年里正是三次月下的清明之夜。杨柳刚像丝丝般柔软,就好似在家乡春天已经快要过去了
。
【词】山抹微云,天粘衰草,画角声断谯门。水流明月,风送残花,诗心韵动江楼。(《满庭芳·山抹微云》,前一句作者是宋,秦观,后一句作者是GPT2)
【翻译】远处的山峰上是一片轻薄的薄云,在天空中飘散着;乌鸦点缀在枯草丛里,号角声响彻四周。明月照耀下清辉的银河映射向西边,传来阵阵寒梅花的音乐,这时节让人肝肠寸断。
【对联】帝道真如,如今都成过去事。民心所向,自古都是往来人。(杨度自挽联,上联作者是民国,杨度,下一联作者是GPT2)
【翻译】京城大道实在了解我的知识,就像当年地方一样经历过了。百姓心里依旧保护着百姓生活世界,自古以来都是从前人们来往的人间吧!
【诗句】万户千门入建章,金绳界路柳丝黄。和风偏度乐声细,晴日自随宫泉长。(《宫词·万户千门入建章》,宋,王仲修)
【翻译】皇上的宅院已经关闭了建立功名利禄,皇家大道路两旁的杨柳依旧是那样的嫩芽。春天来到这里,宫殿高耸入云霄,宫殿中传出一阵清脆婉转的流水。
【诗句】沅湘两水清且浅,林花夹岸滩声激。洞庭浩渺通长江,春来水涨连天碧。(《少年湖南歌》,民国,杨度)
【翻译1】沅江两岸的流淌在这里是多么高远呢?树丛生的野草和小洲环绕着江面,河畔的波涛好像是那样宽阔无际;春天来了时节,水面上涨起伏着一片青色。
【翻译2】沅江两岸的流淌着一片清澈的江水清澈,茂密的树林环绕在河岸上。洞庭湖广阔无际,春水滔滔不断地流向远方。
【翻译3】潇湘两岸的流淌着一片清澈的水,树林间的花瓣随风飘荡。洞庭湖广阔无际,波涛汹涌,波光粼粼,好像是天空相接。
【翻译4】沅水湘江清澈见底,水波荡漾,岸边树木繁茂如浅的流动。洞庭湖浩淼远望去,水天相接处连成一片。
从结果上来看,3万来句的效果还马马虎虎,很多翻译不是直译过来的,更倾向于“意译”,机器翻译的时候会“脑补”一些场景,如对“山抹微云,...,诗心韵动江楼”的翻译,机器能够“揣摩”出“这时节让人肝肠寸断”,开始“有内味”了。
如果采用一些手段扩充下语料,如将整首诗歌和对应翻译逐句拆分、对白话文部分进行文本增强(同义词替换、随机插入、随机交换等)和将意译改为直译等,训练处的模型可能会更强大些,翻译效果能提升不少。
通过
上述
诗歌语料库分析流程
,笔者想说一下对于
(
文本
)
数据
挖掘
的一些看法:
所谓挖掘,通常带有“发现、寻找、归纳、提炼”等内涵,既然需要去发现和提炼,那么,所要找寻的内容往往都不是显而易见的,而是“隐蔽”和“藏匿”于文本之中,或者是人无法直接在大范围内发现和归纳出来的。如果要抽丝剥茧,需要结合领域知识(如文中的诗歌常识),运用多种分析手段(如文中的各类NLU和NLG方法),有时甚至需要逆向思维(如文中的诗歌生成),且各类分析最好是一个前后相继、互为补充有机整体,这样才能以最高的效率来完成文本数据的探索任务。
参考资料:
《数学与文学的共鸣》,丘成桐
《迦陵说诗.嘉莹说诗讲稿》, 叶嘉莹
《文本数据管理与分析》,翟成祥
《文本数据挖掘》,宗成庆
《古代汉语基础》,吴鸿清
《诗词格律》,王力
《语言的科学》,诺姆.乔姆斯基
《现代汉语词汇学教程》,周荐
《语言的认知研究和计算分析》,袁疏林
《自然语言处理的认知方法》,Bernadette Sharp
《自然语言处理入门》,何晗
https://github.com/Werneror/Poetry
https://github.com/kpu/kenlm
https://github.com/jiaeyan/Jiayan
《Catching a Unicorn with GLTR: A tool to detect automatically generated text》,http://gltr.io
《Better Language Models and Their Implications》,https://openai.com/blog/better-language-models/
《自由度+凝固度+统计的新词发现》,https://blog.csdn.net/qq_39006282/article/details/91357603
看了上面的文章,如果想学,可以看笔者之前的“文本挖掘系列”文章,原理和笔代码兼有~
特别推荐|【文本挖掘系列教程】:
以上是关于文本挖掘实操用文本挖掘剖析54万首诗歌的主要内容,如果未能解决你的问题,请参考以下文章
数据挖掘实操用文本挖掘剖析近5万首《全唐诗》
万字长文!用文本挖掘深度剖析54万首诗歌
数说用文本挖掘剖析近5万首《全唐诗》
用文本挖掘剖析近5万首《全唐诗》
近5万首《全唐诗》里有趣的秘密,大数据用文本挖掘告诉你
用文本挖掘分析了5万首《全唐诗》,竟然发现这些秘密