对知乎16W+问题进行文本挖掘,发现了这些秘密
Posted 达观数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对知乎16W+问题进行文本挖掘,发现了这些秘密相关的知识,希望对你有一定的参考价值。
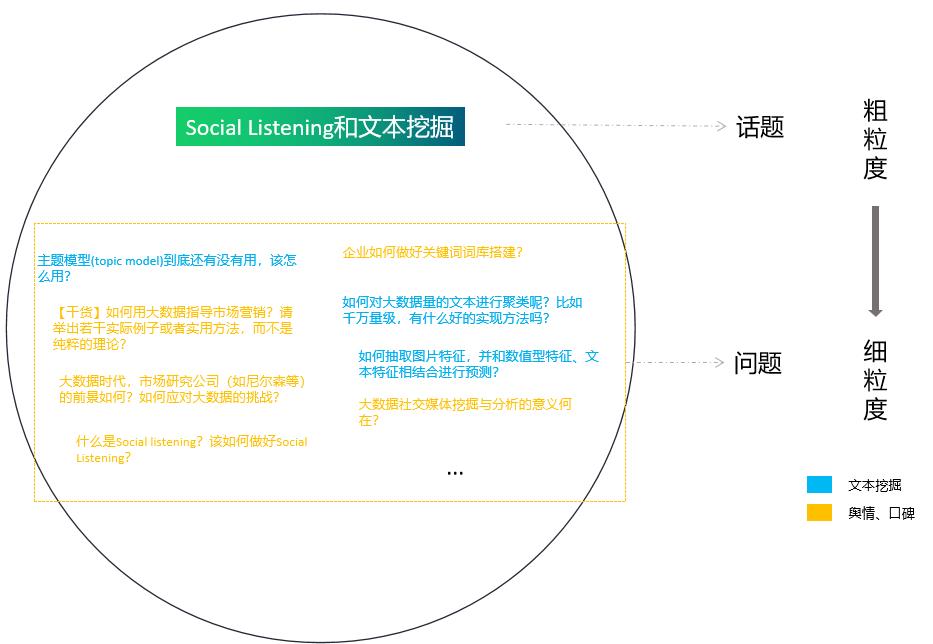
在这里,笔者抛出一个假设:
各个话题下的热门问题会对其关注用户产生认知上的影响,挖掘热门内容就能预判用户群感兴趣的内容倾向。
要理解这个假设,不得不提到传播学领域的“议程设置理论”。
“议程设置理论”认为媒体上的信息往往不能决定人们对某一事件或意见的具体看法,但可以通过刻意安排相关的议题(在知乎上可以理解为话题、问题或者具体的内容)来有效地左右人们关注哪些事实和意见,以及他们谈论的先后顺序。各类媒体报道和用户UGC赋予各种议题不同程度的显著性的方式,影响着人们的对周围世界的大事及重要性的判断。
了解知乎数据分析相关话题的“议程安排”,我们就能了解占领相关人群心智的是哪些热门事件和内容。
在本分析项目中,笔者认为广大关注“数据分析”的知乎用户对于数据分析领域(包括数据分析的学习、就业、技能等)中重要问题的认识和判断与知乎上的各类信息,尤其是话题和问题之间,存在着一种高度对应的关系,即知乎上的热门话题和热门问题,同样也作为重要信息反映在公众的意识和脑海中;知乎上提问越多、回答越多、关注越多的问题,用户对该问题的重视程度越高。根据这种高度对应的相关关系,我们可以认为认为知乎上的热门问题具有一种形成“议事日程”的功能,知乎上的热门问题可以赋予各种议题不同程度“显著性”的方式,影响着数据分析相关的用户所瞩目的焦点和对“数据分析”相关问题的认知。了解这些热门话题和问题,我们就能间接的知悉数据分析相关人群的利益诉求点是哪些。
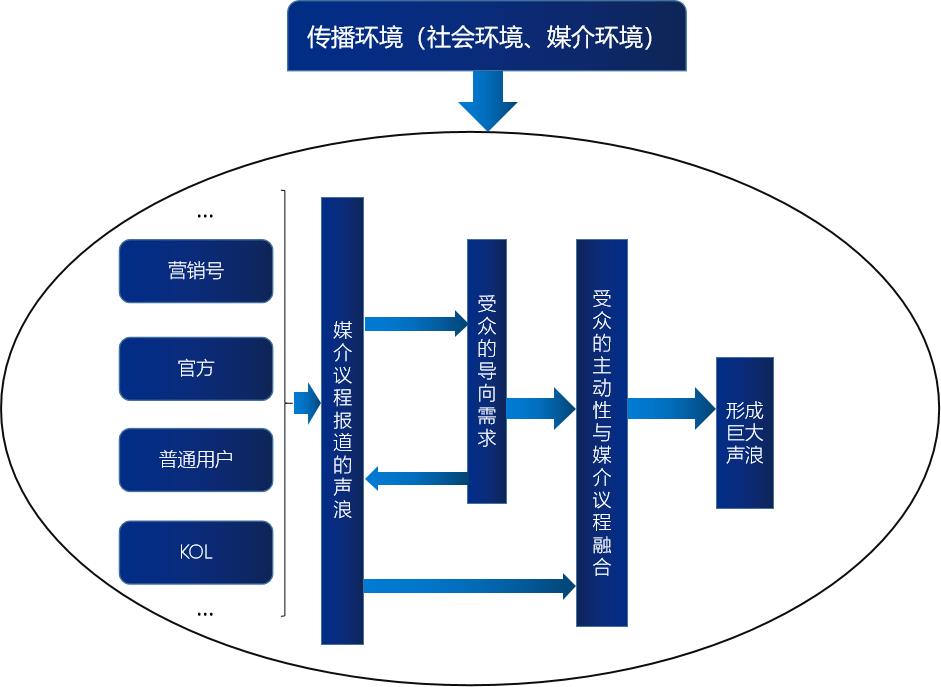
在对问题数据分析之前,我们先来了解下知乎平台上,话题和问题的关联逻辑,这有利于我们更好的理解分析结果。
问题是由用户自发提出而生成的,每个问题都可以选择添加话题标签,所能添加的话题标签数0=< 话题标签数<=5,假如某个问题添加了一个话题标签,那么
问题会出现在该话题的全部问题中,根据问题及其回答的质量和热度,可能会出现在话题动态和精华页中
问题会根据一定规则出现在该话题的各页面中
相关用户在该话题下的回答数、获赞数会发生变化
关注该话题的用户的话题动态页中会出现这个问题。未来,取决于条目和用户的相关性,部分问题或者回答还会出现在关注该问题的首页feed流中
本文根据问题数量选取了跟“数据分析”相关的10大话题,依次是数据、数据分析、算法与数据结构、商业数据分析、数据挖掘、数据科学、数据统计、数据结构、大数据分析和互联网数据分析,从中采集了16W+的问题,其中会出现有个问题对应多个话题情况,也就是说,这16W+的问题存在重复。
下图是各个话题下问题数量的分布情况:
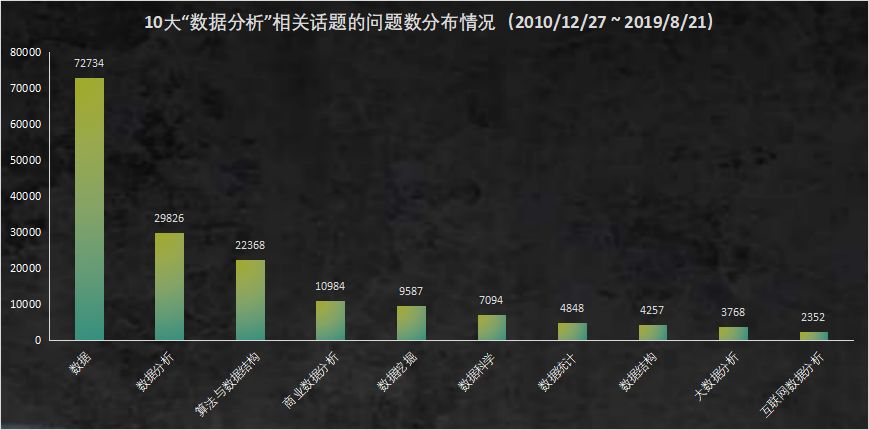
数据从2010年12月份开始统计,在整体上,各大话题下的问题数量是上升的趋势,其中“数据”话题下的提问数量增幅最大,多半是因为该话题外延较大,所有跟“数据“相关的问题都能打上”数据“这一话题标签。

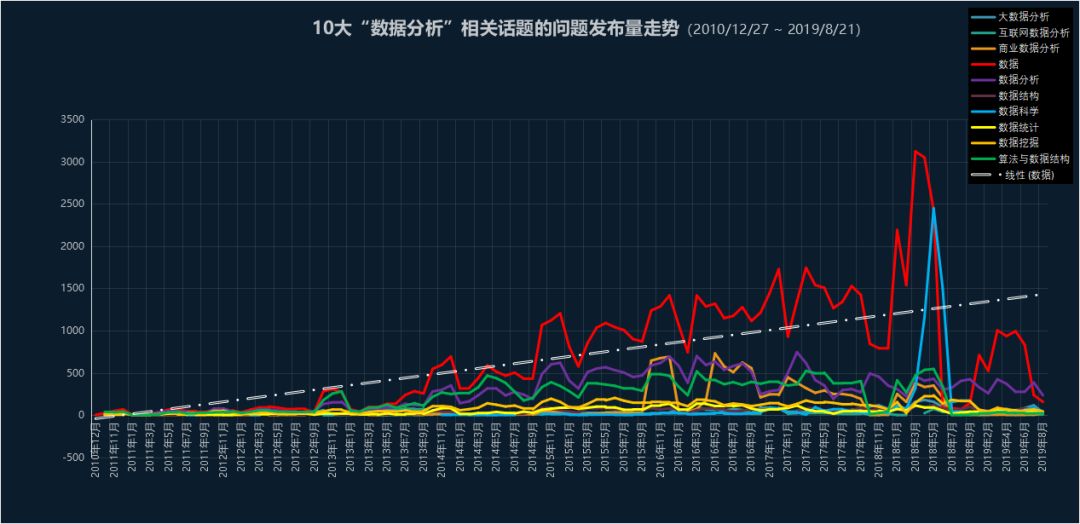
从上个图可以看到,在2018.03-2018.07这段时间,绝大部分话题下的数据提问数量达到一个较高的数值,“数据科学”这一话题下的问题突然猛涨,说明这段时间知乎上用户对数据相 -关的问题关注度较高,间接映射出这段时间数据行业及其职位的火热程度。
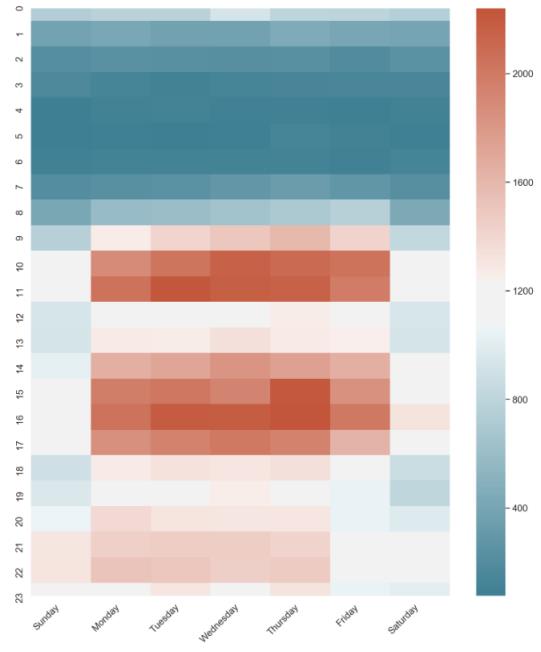
此外,上图还反映了一个有意思的现象,即周一到周四大家都会在下班后的20时~23时之间有活跃,但是在周五下班后却活跃度大大降低,看来临近周末,大家追求、探寻知识的热情也大大降低了。
下面,再来根据互动数据找出这10个话题下16W+问题中的热门问题。
那么,问题来了?怎么定义热门?如何客观的评价问题的热门程度?
不急,接着往下看~
TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution),中文名为“优劣解距离法”。TOPSIS 法是一种常用的组内综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。基本过程为基于归一化后的原始数据矩阵,采用余弦法找出有限方案中的最优方案和最劣方案,然后分别计算各评价对象与最优方案和最劣方案间的距离,获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的依据。该方法对数据分布及样本含量没有严格限制,数据计算简单易行。
举一个容易理解的例子:
16W+问题中,会存在一个问题对应多个话题的情况,所以需要做去重处理,去重之后有10W+的问题量,每个问题都有如下4个维度:
answer_count(回答量)
comment_count(评论量)
follower_count(关注量)
view_count(阅读量)
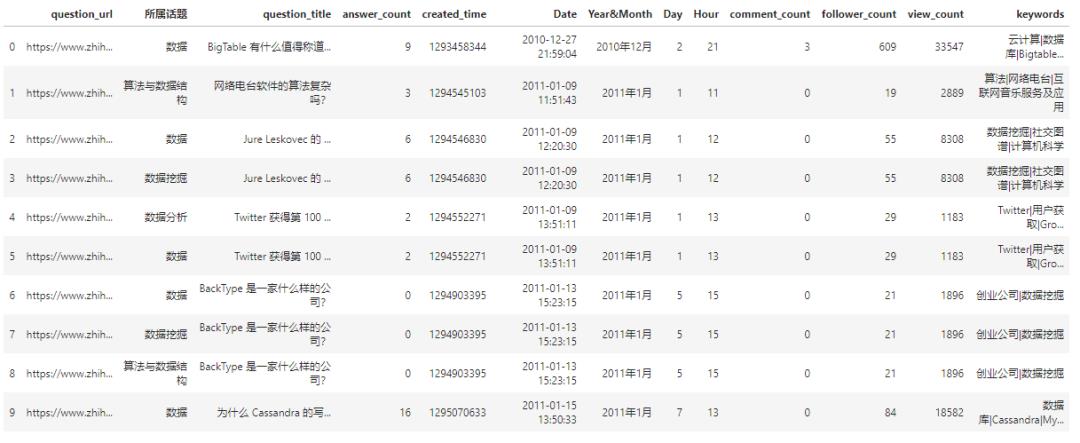
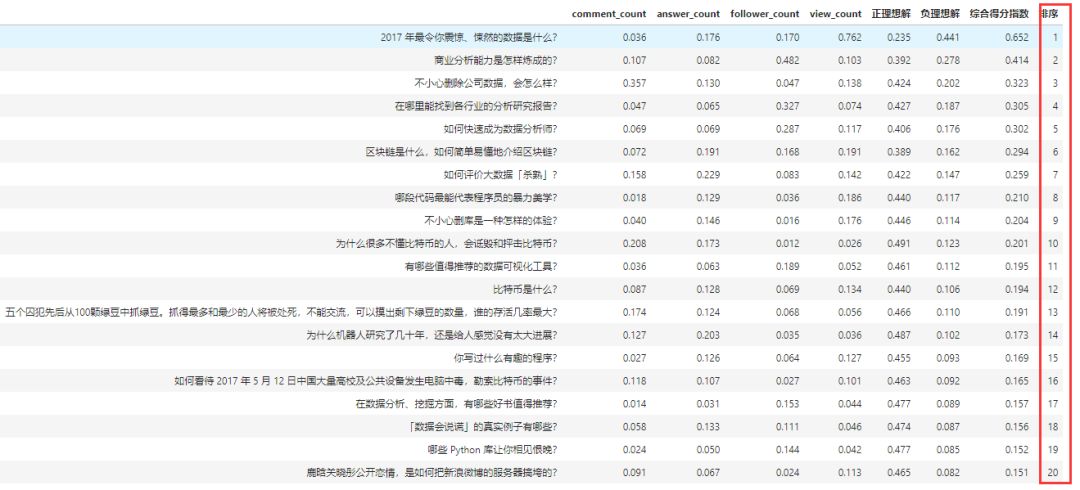 为了避免看不清,再次罗列下TOP20热门问题:
为了避免看不清,再次罗列下TOP20热门问题:
(一)2017 年最令你震惊、悚然的数据是什么?
(二)商业分析能力是怎样炼成的?
(三)不小心删除公司数据,会怎么样?
(四)在哪里能找到各行业的分析研究报告?
(五)如何快速成为数据分析师?
(六)区块链是什么,如何简单易懂地介绍区块链?
(七)如何评价大数据「杀熟」?
(八)哪段代码最能代表程序员的暴力美学?
(九)不小心删库是一种怎样的体验?
(十)为什么很多不懂比特币的人,会诋毁和抨击比特币?
(十一)有哪些值得推荐的数据可视化工具?
(十二)比特币是什么?
(十三)五个囚犯先后从100颗绿豆中抓绿豆。抓得最多和最少的人将被处死,不能交流,可以摸出剩下绿豆的数量,谁的存活几率最大?
(十四)为什么机器人研究了几十年,还是给人感觉没有太大进展?
(十五)你写过什么有趣的程序?
(十六)如何看待 2017 年 5 月 12 日中国大量高校及公共设备发生电脑中毒,勒索比特币的事件?
(十七)在数据分析、挖掘方面,有哪些好书值得推荐?
(十八)「数据会说谎」的真实例子有哪些?
(十九)哪些 Python 库让你相见恨晚?
(二十)鹿晗关晓彤公开恋情,是如何把新浪微博的服务器搞垮的?
秉着“抓大放小”的原则,笔者针对上述筛选出的TOP100热门问题使用内容分析法进行分析。
内容分析法(Content Analysis)是一种对传播内容(包括且不限文本、图片、视频等)进行客观、系统和定量的描述的研究方法。其实质是对传播内容所含信息量及其变化的分析,即由表征的有意义的词句推断出准确意义的过程。内容分析的过程是层层推理的过程。
定性内容分析的常见起点通常是转录采访文本。定性内容分析的目的是将大量文本系统地转换为关键结果的高度组织和简洁的摘要。对逐字记录的访谈中的原始数据进行分析以形成类别或主题,这是在分析的每个步骤中进一步提取数据的过程;从表面化的文字内容到其蕴藏的内涵。

在实操方面,基于MECE分析法( Mutually Exclusive Collectively Exhaustive,中文意思是“相互独立,完全穷尽”)对TOP100热门问题中的议题做到不重叠、不遗漏的分类,该分类务必完全、彻底、能适合于所有问题,使所有分析单位都可归入相应的类别,不能出现无处可归的现象,借此有效把握“数据分析”相关问题的内容结构和内容倾向,发现其中的热门主题。
笔者在浏览TOP100热门问题,将其划分为以下6类:
学习方法:怎么样学习数据分析
技能&工具:进行数据分析的相关工具,如Excel、SPSS或Python等,以及一些操作小技能,比如怎样用excel绘制旭日图
分析&洞察:利用数据(分析)产生的洞见
应用:数据(分析)的实际应用
数据采集:数据爬虫或者采集软件
学习资源:数据(分析)相关的书刊、资料
做数据分析不得不看的书有哪些?---> 学习资源
中国现在各行业的发展情况如何?---> 分析&洞察
怎样用 Excel 做数据分析?---> 技能&工具
怎样进行大数据的入门级学习?---> 学习方法
有哪些网站用爬虫爬取能得到很有价值的数据?---> 数据采集
新兴专业 BA(business analytics)到底学什么?发展前景怎样?---> 应用
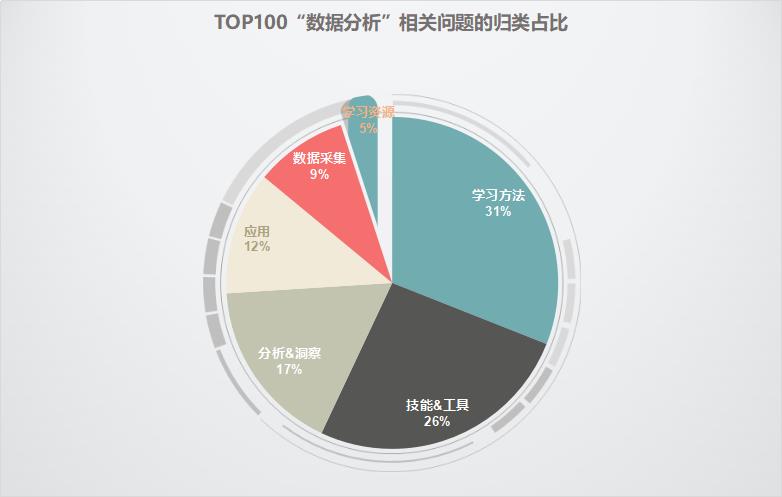
目前热门问题中谈到数据分析“学习方法”的较多,其次是“技能&工具”,二者数量之和占到TOP100的一半,结合一些具体问题描述,可以反映出2点:
许多用户在数据分析(包括大数据、编程、机器学习等)的学习路径方面摸不清头脑,他们想了解如何在较短的时间内取得较好的学习效果,这是数据分析相关人群的一个很迫切的利益诉求;
许多用户对于数据分析的实操很感兴趣,想了解如何通过使用数据分析工具将数据分析工作落地,这方面的阅读需求表现在对干货内容(这里是回答)的“痴迷”上。
与此相比,“分析&洞察”、“应用”、“数据采集”占比偏少,这类内容相对深奥或者技术性较高,读者看起来也比较吃力,阅读兴趣随之降低。
此外,“学习资源”的提问占比最少,这从侧面反映广大知乎用户(数据分析相关人群)不太愿意花时间(系统性的)阅读数据分析相关的书刊、PDF资料或者github开源代码,惰性暴露无遗~
总体说来,如果将技巧比作“术”,强调如何将数据分析用具体的技能和工具落地;将数据的应用、分析比作“道”,强调如何高屋建瓴的用数据分析解决实际问题。那么,这部分数据反映出数据分析相关用户对于高层次数据分析内容的阅读需求不大,其阅读兴趣主要集中在科普类、技巧类的浅层次内容。
与用户的话题关注列表相比,问题下的标签列表元素组合会更容易理解一些。在这里,笔者将话题标签之间的共现关系抽象成图,采用图聚类的方法对热门话题标签进行聚类,以期从问题的角度去发现热门主题(在这里,笔者将“主题”设置为一个比“话题”内涵更大的概念)。
每一个标签都代表一个话题,是一个词汇。以词汇为基本要素的聚类方法打破了所有文档的边界,对整个文档集合构建词汇共现网络。网络中的节点对应文档集合中的词汇,网络中的边描述词汇的共现关系。基于词汇共现网络,可以采用社区发现算法将复杂网络分割成若干子图网络结构。每个子图网络结构包含若干在内容上密切相关的词汇,它们指向特定的话题。
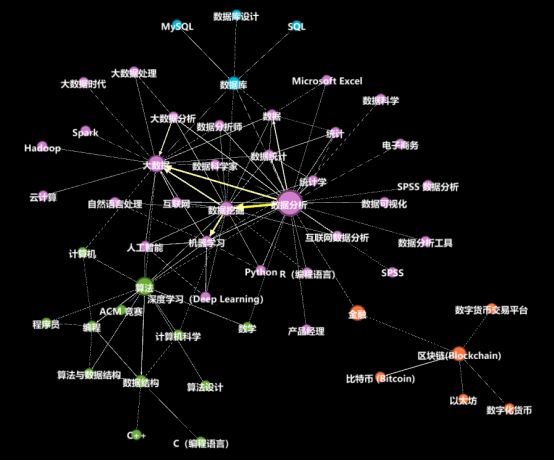
橙色系:虚拟货币
绿色系:算法
紫色系:大数据及数据分析
蓝色系:数据库
根据每个聚类的节点数多少、 聚类中心的节点大小以及线条的粗细,我们可以知道
大数据&数据分析是其中最为热门的主题
数据分析、数据挖掘、大数据、机器学习这几个话题间存在很强的相关性,也就是说数据相关的问题,同时出现这几个话题标签的可能性较大
文本挖掘中常常会涉及到“分布式假设”:如果两个词的上下文相似,那么这两个词也是相似的(Words that occur in similar contexts tend to have similar meanings.)。
举例来说,有以下两段话分别是周武王和魏征对商纣王和隋炀帝的评价:
今商王受无道,暴殄天物,害虐烝民,为天下逋逃主,萃渊薮
炀帝恃其俊才,骄矜自用,故口诵尧、舜之言而身为桀、纣之行,曾不自知,以至覆亡也
上面的评价对两位帝王的具体措辞不同,但形容纣王和隋炀帝的语境相同,都提到两位帝王的施政暴虐,不恤民情,因而纣王和炀帝的所作所为基本相同,二者一同划到“暴君”的行列。
进一步来讲,如果词汇w的含义由分布式表示(w的上下文词汇)uw 概括,则w含义的变化应该能在uw 中反映出来。如下图所示,在1850s/1900年代、1950年代和1990年代的英语世界,gay、broadcast和awful的词义分别有不同的内涵,内涵的变迁可以通过其语境(上下文词汇)呈现出来。同时,内涵的变迁也折射出社会人文环境的变化,比如“broadcast”在1850年代是“播撒种子(通过sow、seed可以看出)”的意思,但到了1900年代,由于大众媒体和无线电的产生,出现了一个引申含义 --- “传播或者无线电广播(通过newspapers、radios可以看出)”,再到了1990年代,又引申到播放电视节目了(通过BBC、television可以看出)...
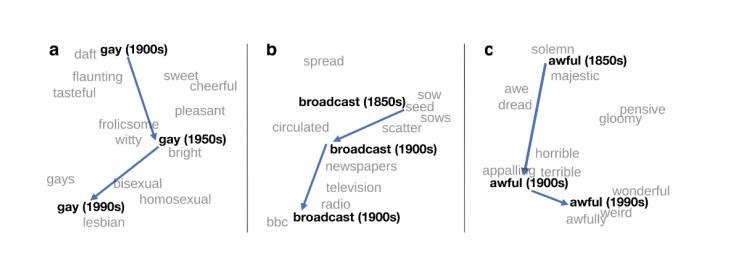
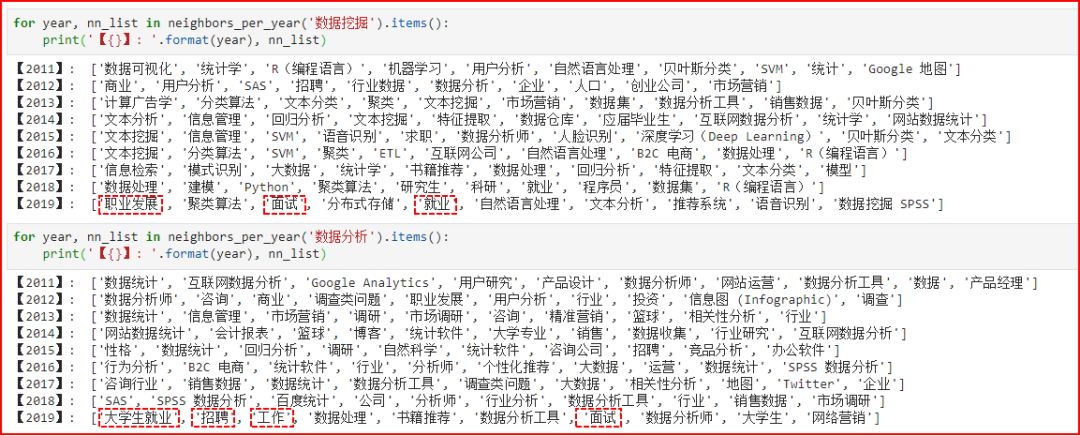
从上面的图示中,我们可以发现两个词汇上下文中的“稳定”与“变化”。变化的是趋势,稳定的是规律。比如,较长的时间段内容,“数据挖掘”话题跟文本挖掘、NLP方面的话题联系紧密,“数据分析”跟咨询、行业研究联系密切;而二者在2019年跟招聘、面试、职业发展等相关话题沾上了边,反映了相关用户对数据挖掘/分析方面的就业比较关心,间接反映出该领域的就业问题比较突出,广大从业者不再是前几年毕业就遭哄抢的“香饽饽”了。

从上面的分析中,结合直接和间接反映的结果,以及笔者的推断,得出如下结论:
数据分析相关的问题大都是提问者在上班“摸鱼”期间提出的,也就是说,这部分用户在知乎上的活跃时间是周一到周五,9:00-12:00,14:00-18:00;
知乎上数据分析技巧类和学习方法类的内容较为“吃香”,这也折射出这部分用户执着于对数据分析之“术”的追求,而对数据分析之“道”,即应用的关注较少;
虚拟货币、算法、大数据、数据库等话题是数据分析相关提问中最为热门的4个头部话题;
去年的数据(分析)话题的一个高峰,彼时相关岗位还比较热门,但由于某些原因(中美贸易战、经济下行等),这部分工作目前供过于求,不再是香饽饽了。
作者介绍
苏格兰折耳喵:达观数据高级解决方案经理。擅长数据分析和可视化表达,热衷于用数据发现洞察,指导实践。
以上是关于对知乎16W+问题进行文本挖掘,发现了这些秘密的主要内容,如果未能解决你的问题,请参考以下文章