Python文本分析初探:《人民的名义》知乎网友都关注什么?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python文本分析初探:《人民的名义》知乎网友都关注什么?相关的知识,希望对你有一定的参考价值。
参考技术A 文本分析是在机器学习数据挖掘中经常要用到的一种方法,主要是指对文本处理,并对文本建模取得有用的信息。目前,文本分析使用愈来愈广泛,包括对新闻、电视剧、书籍、评论等等方面的文本挖掘并进行分析,可以深入找到表面文字看不到的细节。介于《人民的名义》这部剧这么火,本人以此为基础,通过对知乎上网友提出的问题进行爬取,并搜集到每一问题的关注、浏览数,进行分析。在未登录的情况下,找到知乎——《人民的名义》主题网页下的等待回答——全部问题(见下图),时间截止到2017年4月15日,地址为: https://www.zhihu.com/topic/20047590/questions 。(在登录状态下,可以显示更多信息,但是需要设置知乎登录函数,同时登录之后可能反爬虫机制会严格)。
每一个问题对应一个链接,点击进去会有该问题的关注者、浏览者等相关信息,如果有人回答还会有回答人数等等,如图。
(1)抓取问题信息
基于上述构造,本文编写爬虫函数来爬取这些信息,第一步先通过《人民的名义》主题网页抓取每一个问题的链接,第二步再通过每一个链接,抓取每一个问题的内容、关注者、浏览者信息。
(2)将信息转入dataframe数据结构,并进行统计分析
在构建get_info(page_url)的基础上,采用map抓取信息,并装入dataframe数据结构中。
得到结果为:
可以看到,知乎网友关注较多的还是剧中的角色,特别是达康书记——该剧目前最火也最有话题性的人物,其次该剧一些争议性的话题,包括穿帮与硬伤等,对陆毅扮演侯亮平的演技,以及比较令人讨厌的角色(郑氏父子、林华华等)的讨论,赵东来撩妹作为近期比较火的一个话题也上了top10.
(3)浏览者最多的问题
对df1数据按照浏览者的数量“reviews”进行排序,并筛选出关注者最高的前10个问题。
可以看到浏览者的top10与关注者基本一致。
(4)对问题的文本分析
对这800多个问题进行分本分析与挖掘,以便深入分析网友提问的关注角度。
根据分词结果,排序找到知乎网友提问问题中使用较多的词,这是从另一个角度分析知乎网友对《人民的名义》关注的相关点。
得到图形:
从上图来看,书记、达康这个最火的话题仍然是提问者比较关注的,但与前边关注者统计不同的是,提问者对祁同伟的关注度较高,其次蔡成功(成功)、高育良、欧阳菁、丁义珍等人也有一定的关注度,大风集团也有一定的关注度。
另外,问题中提到“现实”这个词语的有这样一些:
现实中有像易学习这样的领导干部吗?
现实里有几个人可以做到像李达康一样不为自己人谋福利?
现实中有没有像易学习一样的基层干部?
现实之中真的有像李达康这样的书记吗?
现实中李达康这样的领导是否值得追随?
如何看待最高检拍摄<人民的正义>取得巨大得成功?现实情况如确实如此,是否应该怒其不争?
侯亮平如果在现实官场中,际遇会如何?
……
基本上都是将剧中人物、事件与现实对照,探究该剧现实的可能性。
在过滤无关词语的基础上,
绘制词云图如下:
可以看到,侯亮平、李达康等关注度较高,其次对拍摄方面有一些关注,比如镜头、手法、拍摄、好看,对受贿、贪官、行贿、利益等腐败问题关注度也比较高。另外,由于送审样片的流出,对送审的关注度也较高。
(5)总结
综合看来,从知乎问题关注者、浏览者的角度来看,所关注的问题基本上是目前网友也比较关心的问题,比如达康书记、陆毅的演技、讨厌的角色(郑氏父子、林华华)、赵东来撩妹、豆瓣刷一星等等。
从提问者关注的角度来看,对更多的角色有所关注,比如祁同伟、高育良、蔡成功等等,另外还关注拍摄技巧、腐败问题、与现实的对照性等等。无论是关注者的角度还是提问者的角度,达康书记是最高的关注点。
同时,从上述文本分析来看,由于jieba分词的精确性,在初步的文本挖掘中,还是存在着欠缺的地方,比如部分词语不完整或遗漏,这需要更精确的文本挖掘方式,比如设置《人民的名义》词库,或者采用机器学习算法来智能地深入分析。
Python3爬取今日头条有关《人民的名义》文章
Python3爬取今日头条有关《人民的名义》文章
最近一直在看Python的基础语法知识,五一假期手痒痒想练练,正好《人民的名义》刚结束,于是决定扒一下头条上面的人名的名义文章,试试技术同时可以集中看一下大家的脑洞也是极好的。
首先,我们先打开头条的网页版,在右上角搜索框输入关键词,通过chrome调试工具,我们定位到头条的search栏调用的的API为:
http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E4%BA%BA%E6%B0%91%E7%9A%84%E5%90%8D%E4%B9%89&autoload=true&count=20&cur_tab=1其返回的数据是标准的json,所有的相关文章链接在data中,key值为article_url,好准备工作完成,我们开始动手coding。
首先,我们构造头条必要的search条件:
query_data =
'offset': offset,
'format': 'json',
'keyword': '人民的名义',
'autoload': 'true',
'count': 20, # 每次返回 20 篇文章
'cur_tab': 1
当然,我们除了search参数之外,还需要必要的header头信息,仔细查看之后我们可以看到,
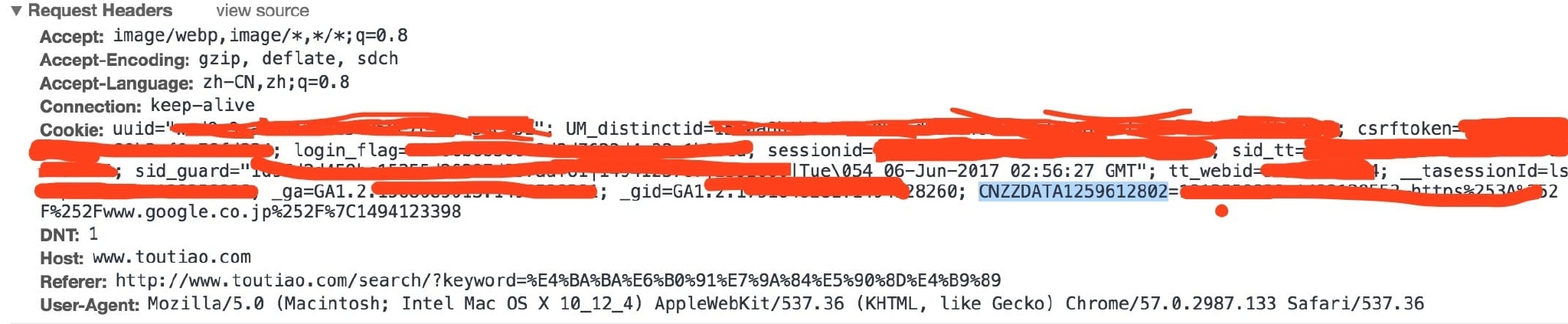
我们只选取其中必要的信息,不放cookie;

然后是编码查询条件

其中_get_query_string方法将query_data编码;
拿到article_req之后解析获取当前搜索结果的所有文章链接,实现如下:
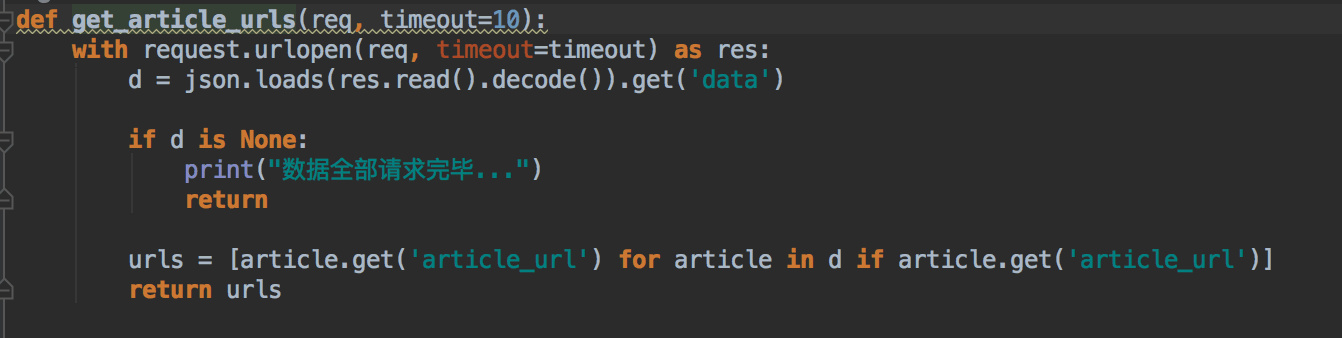
获取到文章链接之后,我们打开每一个url进行解析。
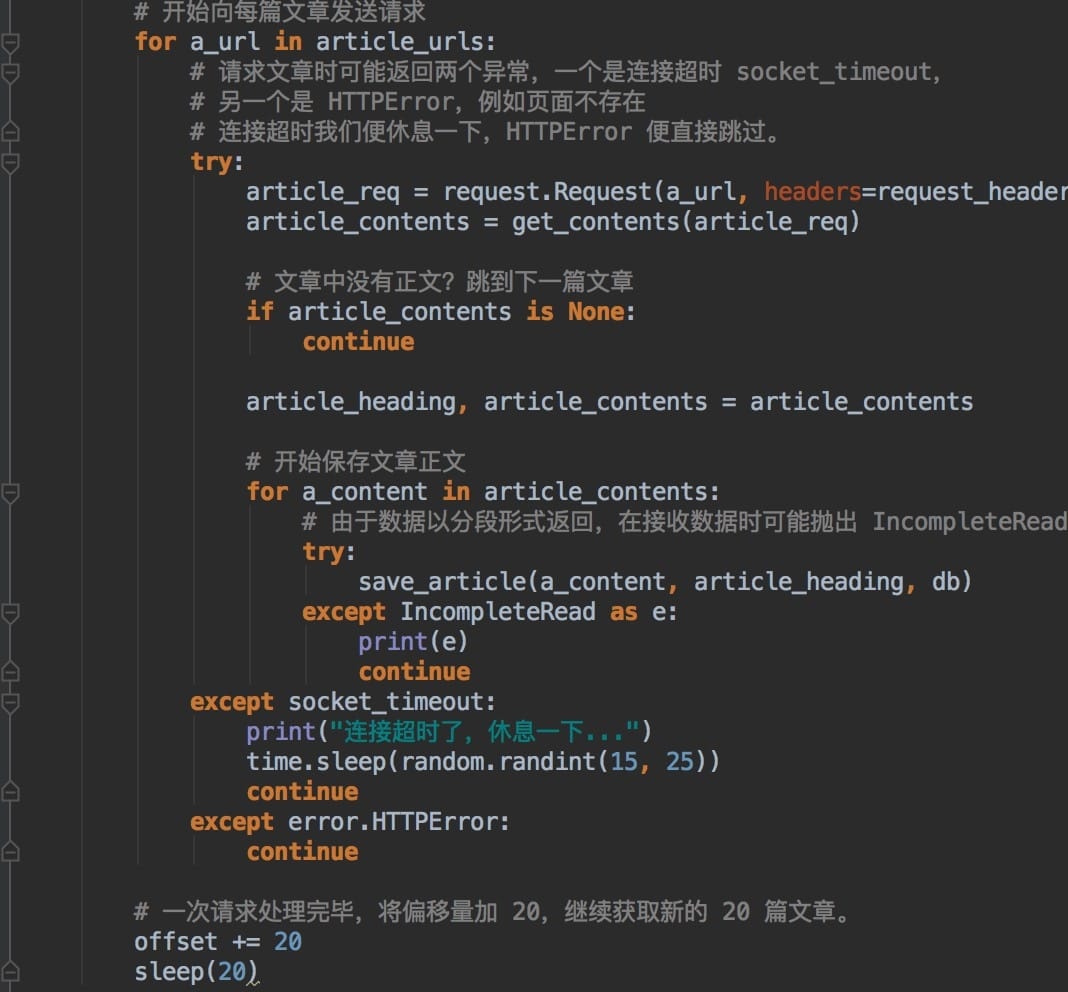
此处,我们简单地对article_content进行解析,取出文章标题、内容和图片。
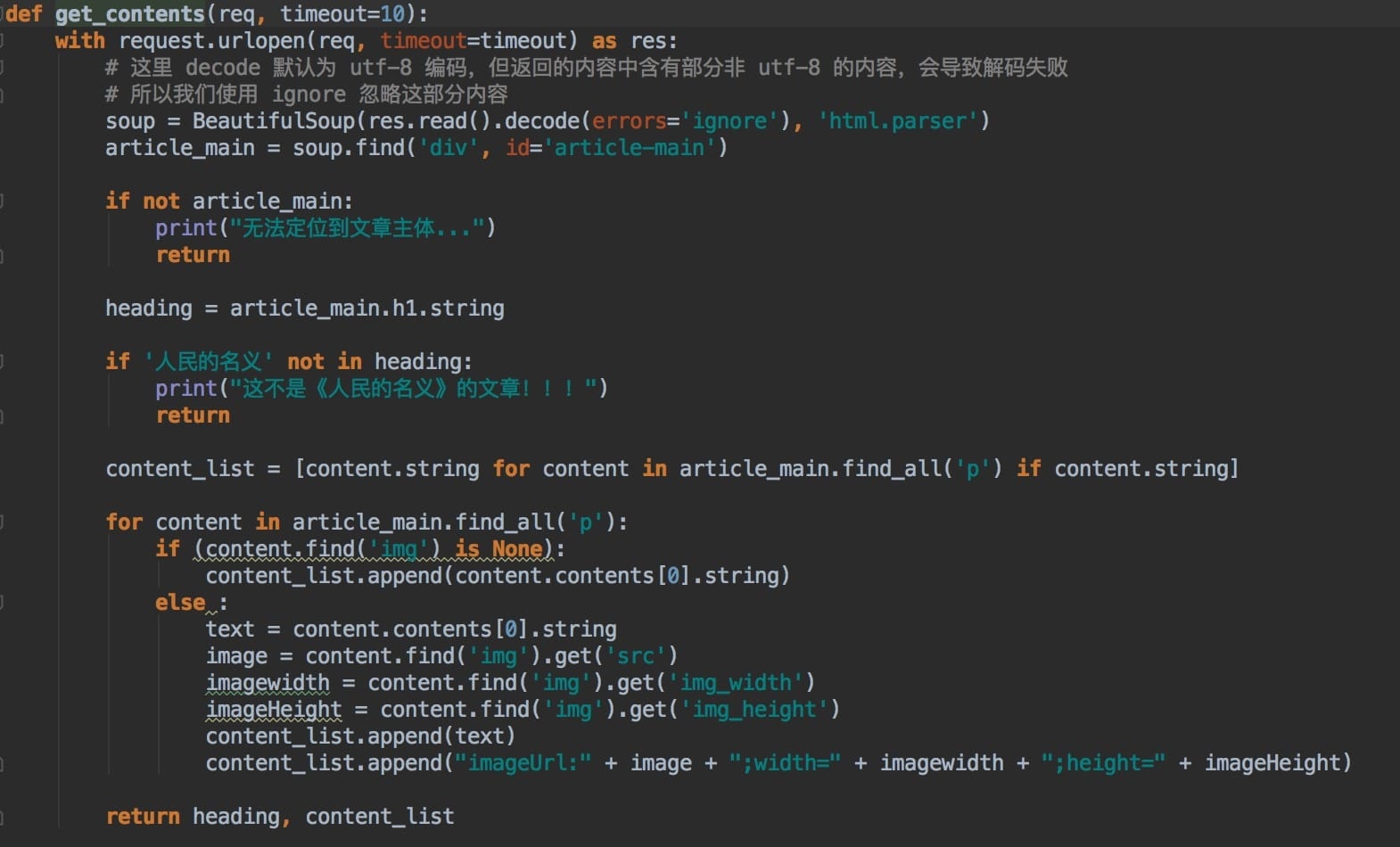
解析完成之后,我们将内容保存到mongo中,方便后续的取数分析。

然后我们运行一下程序,

运行程序的时候我们发现,通过search来搜索最后得到的文章数量有限,只有几十篇文章,估计是头条的限制。
下一篇我们将介绍如何通过一篇文章和相关推荐进行链式爬取所有的关联推荐文章。
以上是关于Python文本分析初探:《人民的名义》知乎网友都关注什么?的主要内容,如果未能解决你的问题,请参考以下文章