Python3爬取今日头条有关《人民的名义》文章
Posted Derrick_gu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3爬取今日头条有关《人民的名义》文章相关的知识,希望对你有一定的参考价值。
Python3爬取今日头条有关《人民的名义》文章
最近一直在看Python的基础语法知识,五一假期手痒痒想练练,正好《人民的名义》刚结束,于是决定扒一下头条上面的人名的名义文章,试试技术同时可以集中看一下大家的脑洞也是极好的。
首先,我们先打开头条的网页版,在右上角搜索框输入关键词,通过chrome调试工具,我们定位到头条的search栏调用的的API为:
http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E4%BA%BA%E6%B0%91%E7%9A%84%E5%90%8D%E4%B9%89&autoload=true&count=20&cur_tab=1其返回的数据是标准的json,所有的相关文章链接在data中,key值为article_url,好准备工作完成,我们开始动手coding。
首先,我们构造头条必要的search条件:
query_data =
'offset': offset,
'format': 'json',
'keyword': '人民的名义',
'autoload': 'true',
'count': 20, # 每次返回 20 篇文章
'cur_tab': 1
当然,我们除了search参数之外,还需要必要的header头信息,仔细查看之后我们可以看到,

我们只选取其中必要的信息,不放cookie;

然后是编码查询条件

其中_get_query_string方法将query_data编码;
拿到article_req之后解析获取当前搜索结果的所有文章链接,实现如下:

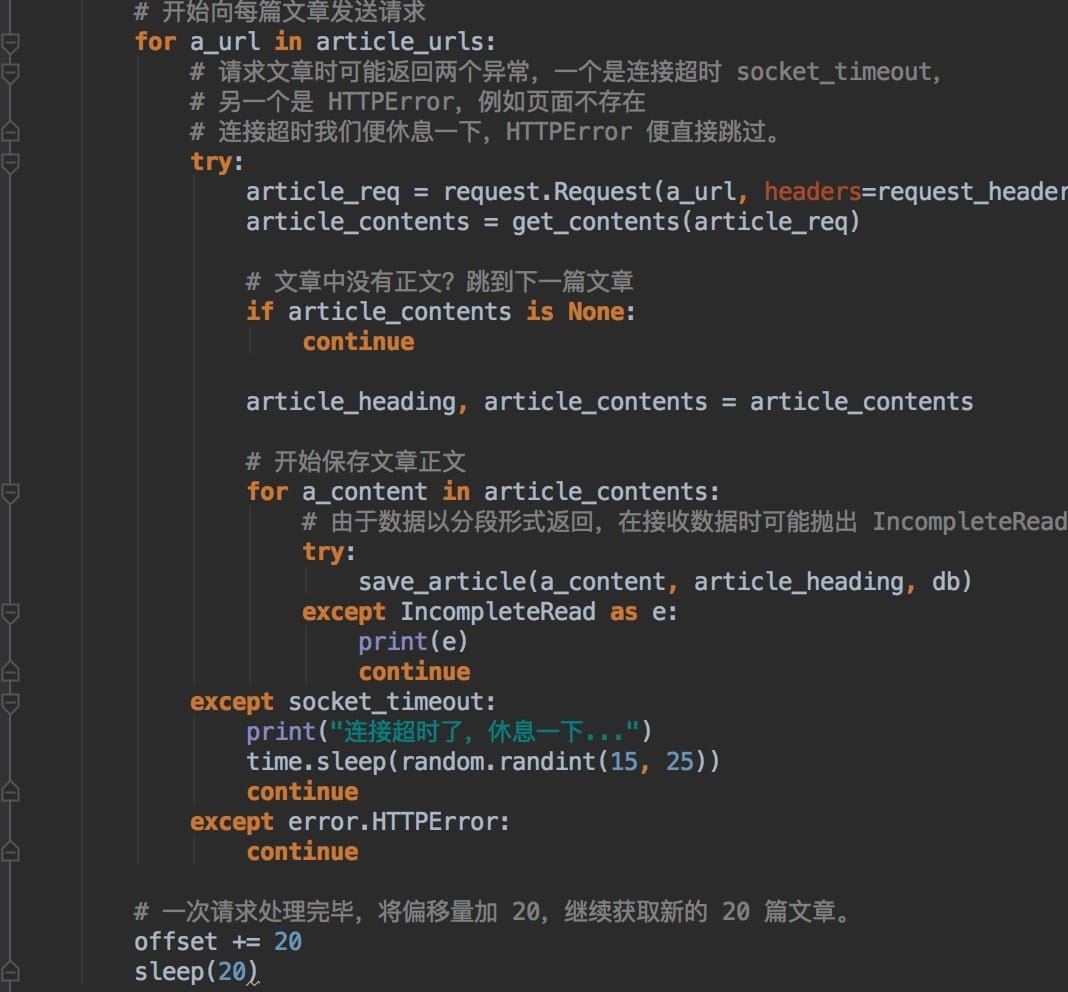
获取到文章链接之后,我们打开每一个url进行解析。
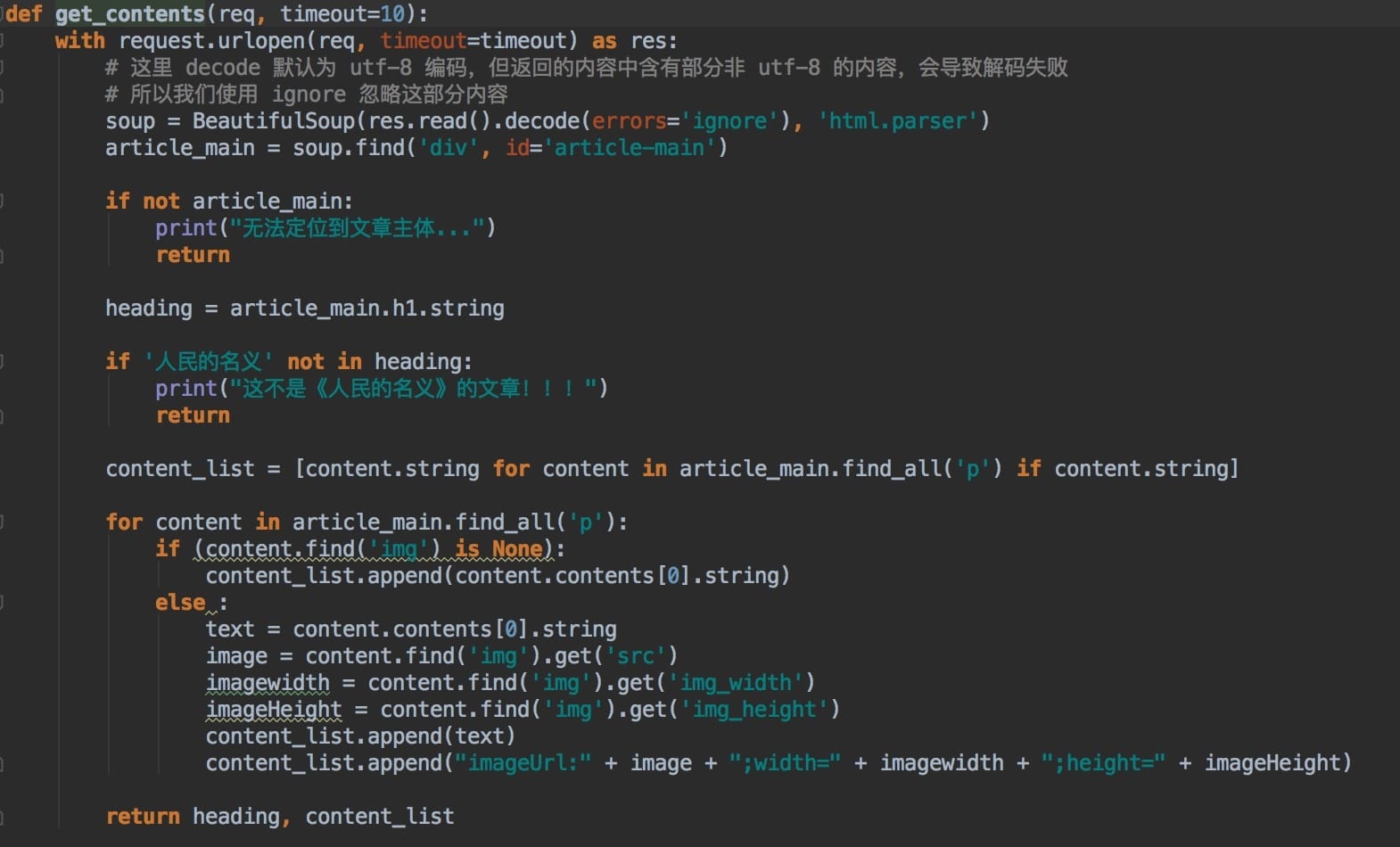
此处,我们简单地对article_content进行解析,取出文章标题、内容和图片。
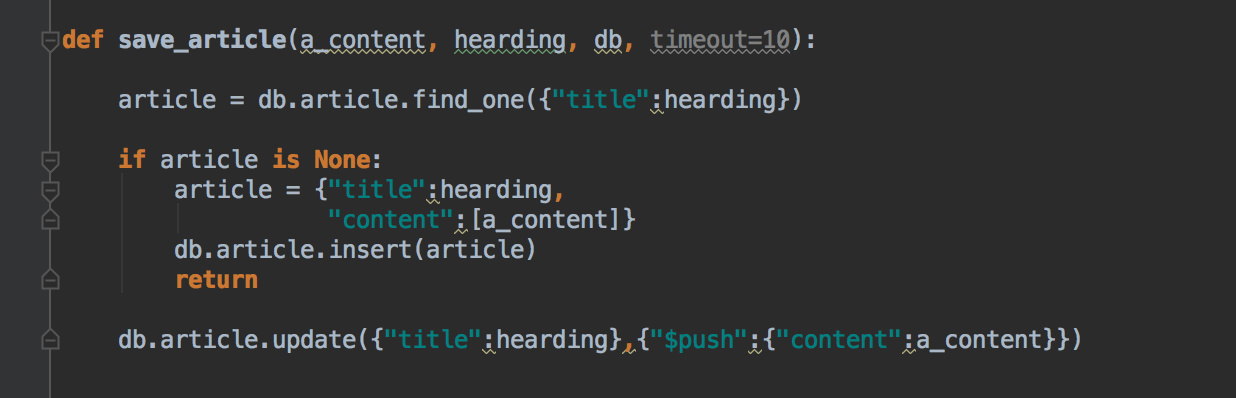
解析完成之后,我们将内容保存到mongo中,方便后续的取数分析。
然后我们运行一下程序,

运行程序的时候我们发现,通过search来搜索最后得到的文章数量有限,只有几十篇文章,估计是头条的限制。
下一篇我们将介绍如何通过一篇文章和相关推荐进行链式爬取所有的关联推荐文章。
以上是关于Python3爬取今日头条有关《人民的名义》文章的主要内容,如果未能解决你的问题,请参考以下文章
Python3网络爬虫开发实战 分析Ajax爬取今日头条街拍美图