JDOS 2.0:Kubernetes的工业级实践
Posted 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDOS 2.0:Kubernetes的工业级实践相关的知识,希望对你有一定的参考价值。
JDOS(Jingdong Datacenter Operating System)1.0于2014年推出,基于OpenStack进行了深度定制,并在国内率先将容器引入生产环境,经历了2015年618/双十一的考验。团队积累了大量的容器运营经验,对Linux内核、网络、存储等深度定制,实现了容器秒级分配。
意识到OpenStack架构的笨重,2016年当JDOS 1.0逐渐增长到十万、十五万规模时,团队已经启动了新一代容器引擎平台(JDOS 2.0)研发。JDOS 2.0致力于打造从源码到镜像,再到上线部署的CI/CD全流程,提供从日志、监控、排障,终端,编排等一站式的功能。JDOS 2.0迅速成为Kubernetes的典型用户,并在Kubernetes的官方博客分享了从OpenStack切换到Kubernetes的过程。 JDOS 2.0的发展过程中,逐步完善了容器的监控、网络、存储,镜像中心等容器生态建设,开发了基于BGP的Skynet网络、ContainerLB、ContainerDNS、ContainerFS等多个项目,并将多个项目进行了开源。本次分享,我们主要分享的是在JDOS2.0的实践过程中关于Kubernetes的一些经验和教训。
注:Kubernetes版本我们目前主要稳定在了1.6版本。本文中的实践也是主要基于此版本。我们做的一些feature和bug,有的在Kubernetes后续发展过程中进行了实现和修复。大家有兴趣也可以同社区版进行对照。

为什么定制?
加固主要指的是在任何时候、任何情况下,将容器的非故障迁移、服务的非故障失效的概率降到最低,最大限度的保障线上集群的安全与稳定,包括etcd故障、apiserver全部失联、apiserver拒绝服务等等极端情况。
裁剪则体现为我们删减了很多社区的功能,修改了若干功能的默认策略,使之更适应我们的生产环境的实际情况。
在这样的原则下,我们对Kubernetes进行了许多的定制开发。下面将对其中部分进行介绍。
线上很多用户都希望自己的应用下的Pod做完更新操作后,IP依旧能保持不变,于是我们设计实现了一个IP保留池来满足用户的这个需求。简单的说就是当用户更新或删除应用中的Pod时,把将要删除的pod的IP放到此应用的IP保留池中,当此应用又有创建新Pod的需求时,优先从其IP保留池中分配IP,只有IP保留池中无剩余IP时,才从大池中分配IP。IP保留池是通过标签来与Kubernetes的资源来保持一致,因此ip保持不变功能不仅支持有状态的StatefulSet,还可以支持rc/rs/deployment。
1.2 检查IP连通性
Kubernetes创建Pod,调度时Pod处于Pending的状态,调度完成后处于Creating的状态,磁盘分配完成,IP分配完成,容器创建完成后即处于Running状态,而此时有可能IP还未真正生效,用户看到Running状态但是却不能登录容器可能会产生困惑,为了让用户有更好的体验,在Pod转变为Running状态之前,我们增加了检查IP连通性的步骤,这样可以确保状态的一致性。
1.3 修改默认策略
Pod的restart策略其实是Rebuild,就是当Pod故障(可能是容器自身问题,也可能是因为物理机重启等)后,kubelet会为Pod重新创建新的容器。但是在实际过程中,其实很多用户的应用会在根目录写入一些数据或者配置,因此用户会更加期望使用先前的容器。因此我们为Pod增加了一个reUseAlways的策略,并成为restart的默认策略。而将原来的Always策略,即rebuild容器的策略作为可选的策略之一。当使用reUseAlways策略时,kubelet将会首先检查是否有对应容器,如果有,则会直接start该容器,而不会重新create一个新的容器。
1.4 定制Controller
在实践过程中,我们有一个深刻的体会,就是官方的Controller其实是一个参考实现,特别是Node Controller和Taint Controller。Node的健康状态来自于其通过apiserver的上报。而Controller仅仅依据通过apiserver中获取的上报状态,就进行了一系列的操作。这样的方式是很危险的。因为Controller的信息面非常窄,没法获取更多的信息。这就导致在中间任何一个环节出现问题,比如Node节点网络不稳定,apiserver繁忙,都会出现节点状态的误判。假设出现了交换机故障,导致大量kubelet无法上报Node状态,Controller进行大量的Pod重建,导致许多原先的健康节点调度了许多Pod,压力增大,甚至部分健康节点被压垮为notready,逐渐雪崩,最终导致整个集群的瘫痪。这种灾难是不可想象的,更是不可接受的。
1.5 资源限制
Kubernetes默认提供了CPU和Memory的资源管理,但是这对生产环境来说,这样的隔离和资源限制是不够的,因此我们增加了磁盘读写速率限制、Swap使用限制等,最大限度保证Pod之间不会互相影响。
我们对大部分的Pod,还提供了本地存储。目前Kubernetes支持的一种容器数据本地存储方式是emptyDir,也就是直接在物理机上创建对应的目录并挂载给容器,但是这种方式不能限制容器数据盘的大小,容易导致物理机上的磁盘被打满从而影响其它进程。鉴于此,我们为Kubernetes的新开发了一个存储插件LvmPlugin,使其支持基于LVM(Logical Volume Manager)管理本地逻辑卷的生命周期,并挂载给容器使用。LvmPlugin可以执行创建删除挂载卸载逻辑盘LV,并且还可以上报物理机上的磁盘总量及剩余空间给kube-scheduler,使得创建新Pod时Scheduler把LVM的磁盘是否满足也作为一个调度指标。
对于数据库容器或者使用磁盘频率较高的业务,用户会有限制磁盘读写的需求。我们的实现方案是把这限制指标看作容器的资源,就像CPU、Memory一样,可以在创建Pod的yaml文件中指定,同一个Pod的不同容器可以有不同的限制值,而kubelet创建容器时可以获取当前容器对应的磁盘限制指标的值并进行相应的设置。
1.6 gRPC升级
生产环境中,当集群规模迅速膨胀时,即使利用负载均衡的方式部署kube-apiserver,也常常会出现某个或某几个apiserver不稳定,难以承担访问压力的情况。经过了反复的实验排查,最终确定是grpc的问题导致了apiserver的性能瓶颈。我们对于gRPC包进行了升级,最终地使得apiserver的性能及稳定性都有了大幅度的提升。
1.7 平滑升级
我们于2016年就着手设计研发基于Kubernetes的JDOS 2.0,彼时使用的版本是Kubernetes 1.5,2017年社区发布了Kubernetes 1.6的release版本,其中新增了很多新的特性,比如支持etcd V3,支持节点亲和性(Affinity)、Pod亲和性(Affinity)与反亲和性(anti-affinity)以及污点(Taints)与容忍(Tolerations)等调度,支持调用Container Runtime的统一接口CRI,支持Pod级别的Cgroup资源限制,支持GPU等,这些新特性都是我们迫切需要的,于是我们决定由Kubernetes 1.5升级至当时1.6最新release的版本Kubernetes 1.6.3。但是此时生产环境已经基于Kubernetes 1.5上线大量容器,如何在保证这些业务容器不受任何影响的情况下平滑升级呢?
对比了两个版本的代码,我们讨论了对于Kubernetes进行改造兼容,实现以下几点:
Kubernetes 1.6默认的Cgroup资源限制层级是Pod,而老节点上的Cgroup资源限制层级是Container,所以升级后要添加相应配置保证老节点的资源限制层级不发生改变。
Kubernetes 1.6默认会清理掉leacy container也就是老的Container,通过对kuberuntime的二次开发,我们保证了升级到1.6后在Kubernetes 1.5上创建的老容器不被清理。
新老版本的containerName格式不一致导致获取Pod状态时获取不到IP,从而升级后老Pod的IP不能正常显示,通过对dockershim部分代码的适当调整,我们将老版本的Pod的containerName统一成新版本的格式,解决了这个问题。
经过如上的改造,我们实现了线上几千台物理机由Kubernetes 1.5到Kubernetes 1.6的平滑升级。而业务完全无感知。
1.8 bug fix和其他feature
我们还修复了诸如GPU中的NVIDIA卡重复分配给同一容器,磁盘重复挂载bug等。这些大部分社区在后面的版本也做了修复。还增加了一些小的功能,比如增加了Service支持set-based的selector,kubelet image gc优化,kubectl get node显示时增加Node的版本信息等等。这里就不详述了。
2.1 参数调优和配置
Kubernetes的各个组件有大量的参数,这些参数需要根据集群的规模进行优化调整,并进行适当的配置,来避免问题以及定制自己的特殊需求。比如说有次我们其中一个集群个别节点出现了不停的在Ready和NotReady的状态之间来回切换的问题,而经过检查,集群的各个服务都处于正常的状态。很是认真研究了一下,才发现是此Node上的容器数量太多,并且每个容器的ConfigMap也比较多,导致Node节点每秒向apiserver发送的请求数也很多,超过了kubelet的配置api-qps的默认值,才影响了Node节点向apiserver更新状态,导致Node状态的切换。将相关配置值调大后就解决了这个问题。另外apiserver的api-qps,api-burst等配置也需要根据集群规模以及apiserver的个数做出正确的估量并设置。
2.2 组件部署
Apiserver使用域名的方式做负载均衡,可以平滑扩展,Controller-manager和Scheduler使用Leader选举的方式做高可用。同时为了分担压力和安全,我们每个集群部署了两套etcd。一套专门用于event的存储。另一套存储其他的资源。
2.3 Node管理
使用标签管理Node的生命周期,从接管物理机到装机完成再到服务部署完毕网络部署完毕NodeReady直至最终下线,每一个步骤都会自动给Node添加对应标签,以方便自动化运维管理。Node生命周期如下图:

同时,Node上还添加了区域zone。可以方便一些将一些部门独立的物理机纳入统一管理,同时资源又能保证其独享。对于一些特殊的资源,比如物理机上有GPU、SSD等特殊资源,对应会给节点打上专属的标签用以标识。用户申请时可以根据需要申请对应的资源,我们在申请的Pod上配属相应的标签,从而将其调度至相应的节点。
2.4 上线流程管理
上线之前制定上线步骤,经相关人员review确认无误后,严格按照上线步骤操作。上线操作按照先截停控制台等入口,而后Controller、Scheduler停止,再停止kubelet。上线结束后按照反向,依次做验证,启动。
2.5 故障演练与应急恢复
为了防止一些极端情况和故障的发生,我们也进行了多次的故障演练,并准备了应急恢复的预案。在这里我们主要介绍下etcd和apiserver的故障恢复。
2.5.1 etcd的故障恢复
使用etcd恢复的大致流程。在etcd无法恢复情况下,另外启动一个etcd集群的方式。
将原etcd数据目录备份
另选3台机器,搭建一个全新的etcd集群(带证书认证)
将新etcd集群的etcd停止,数据目录下的内容全部删除
将备份数据拷贝到3台新etcd机器上,使用etcdctl snapshot restore逐个节点恢复数据,注意观察恢复后id是否一致。数据恢复完成后查看endpoint status状态是否正常。
2.5.2 apiserver的故障恢复
一般单台apiserver故障,将其进行维护即可。如果apiserver同时发生故障时,会导致Node节点状态出现异常,此时则需要立刻停掉Controller和Scheduler服务,防止状态判断失误造成的误决策。在apiserver修复后进行验证后,再启动其他组件。
3.1 Ansible
JDOS 2.0日常管理的物理机和容器规模庞大,平时的部署和运维如果没有好用的工具会非常繁琐,为此我们主要选用Ansible开发了2.0专属的部署和运维工具,极大的提高了工作效率。
3.2 Kubernetes Connection Plugin
为了方便操作各个容器,我们还开发了Ansible的Kubernetes插件,可以通过Ansible对容器进行批量的诸如更新密码、分发文件、执行命令等操作。
hosts配置:

结果样例:
3.3 巡检工具
日常巡检系统对于及时发现物理机及各个服务的异常配置和状态非常重要,尤其是大促期间,系统的角落有些许异常可能就带来及其恶劣的影响,因此特殊时期我们还会加大巡检的频率。
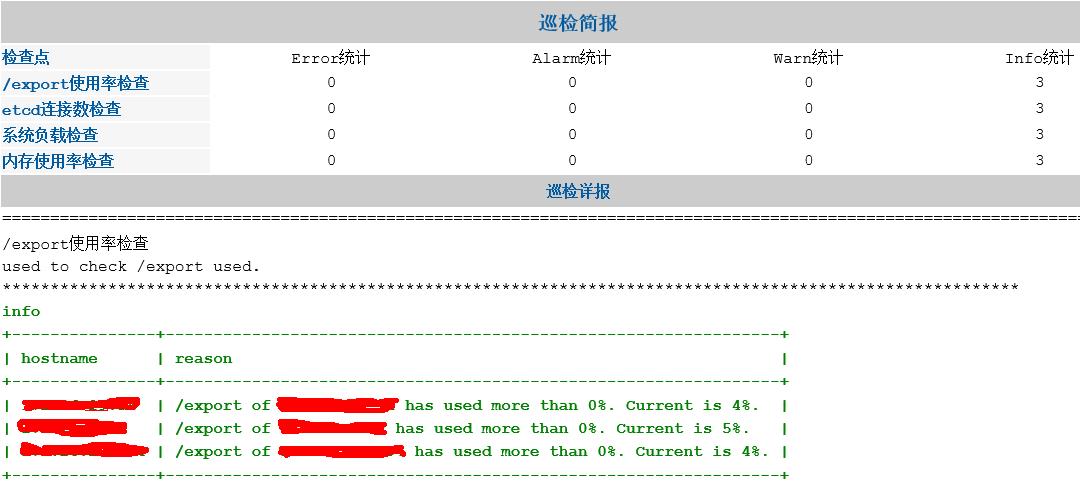
巡检的系统的巡检模块都是可插拔的,巡检点可以根据需求灵活配置,随时增减,其中一个系统的控制节点的巡检结果样例如下:
3.4 其他工具
为了方便运维统计和监控,我们还开发了一些其他的工具:
API日志分析工具:使用Python对日志进行预处理,形成结构化数据。而后使用Spark进行统计分析。可以对请求的时间、来源、资源、耗时长短、返回值等进行分析。
kubesql:可以将Kubernetes的如Pod、Service、Node等资源,处理成类似于关系数据库中的表。这样就可以使用SQL语句对于相关资源进行查询。比如可以使用SQL语句来查询mysql、default namespace下的所有Pod的名字。
event事件通知:监听event,并根据event事件进行分级,对于紧急事件接入告警处理,可以通过邮件或者短信通知到相关运维人员。
Q:LVM的磁盘IO限制是怎么做的?
Q:巡检工具是只检查不修复吗?
Q:使用的什么Docker storage driver?
Q:为了提升Pod更新速度,我们对容器删除的流程进行了优化,将CNI接口的调用提前到了stop容器,没太明白这里。
Q:有用PV PVC吗?底层存储多的什么技术?
Q:请问相同Service的不同Pod上的log,fm,pm怎么做汇总的?
Q:能详细描述一下“gRPC的问题导致了apiserver的性能瓶颈”的具体内容吗?
Q:请问多IDC的场景你们是如何管理的?
Q:加固环节(包括etcd故障、apiserver全部失联、apiserver拒绝服务等等极端情况)上面列举的几种情况发生时会造成灾难性后果吗,Kubernetes集群的行为会怎样,有进行演练过不,这块可以细说一下吗?
Q:Pod固定IP的使用场景是什么?有什么实际意义?
Q:请问系统开发完毕后,下一步有什么计划?进入维护优化阶段,优秀的设计开发人员下一步怎么玩?
Q:应用滚动升级,有无定制?还是采用Kubernetes默认机制?
Q:能否介绍一下对GPU支持这块?
以上是关于JDOS 2.0:Kubernetes的工业级实践的主要内容,如果未能解决你的问题,请参考以下文章