京东大规模Kubernetes集群的精细化运营(有彩蛋)
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了京东大规模Kubernetes集群的精细化运营(有彩蛋)相关的知识,希望对你有一定的参考价值。

梁小平
京东商城基础架构部资深架构师
十年IT与互联网开发和架构经验。2012年加入京东,现任京东商城基础架构部资深架构师,主要负责京东商城调度与集群管理系统阿基米德(Archimedes)调度和混合部署研发落地工作。
京东JDOS 2.0自上线以来,经历了2017~2018年618、双十一的多次大考,在京东商城多个数据中心进行了大规模的集群部署。本次分享将介绍JDOS团队在长达一年多时间里的大规模Kubernetes集群实践过程中的经验和教训。
主要内容:
大规模Kubernetes集群实践背景
Kubernetes重构、定制与优化
大规模Kubernetes集群运营
一、大规模Kubernetes集群实践背景
京东早在2016年年底就上线了JDOS2.0,成功从OpenStack切换到JDOS 2.0的Kubernetes技术栈,从基础设施升华到完整高效的PaaS平台。JDOS 2.0推进了业务从源码到编译打包构建镜像到上线的全流程,建设了一站式应用运行平台。这一年,我们逐步完善了容器的监控、网络、存储,镜像中心等容器生态建设,开发了ContainerDNS 、ContainerLB、ContainerFS、ContainerIS、ContainerCI、MDC、ContainerLog等多个项目,并将其中部分项目进行了开源。
参考链接:https://github.com/tiglabs/
我们为这个容器生态起了一个全新的名字:阿基米德,意为撬动数据中心的人。
其实京东容器化的数据中心已经建设了四五年的时间,已经比较稳定了,但我们的Kubernetes还是1.6版本,你会发现当Kubernetes使用到后期的时候,它并不能解决数据中心资源使用率的问题,它其实仅仅解决了发布或者是管理资源的容器这方面的一些东西。我们现在的重点就是往阿基米德这个方向改进,即往数据中心的资源调度这个方向发展。
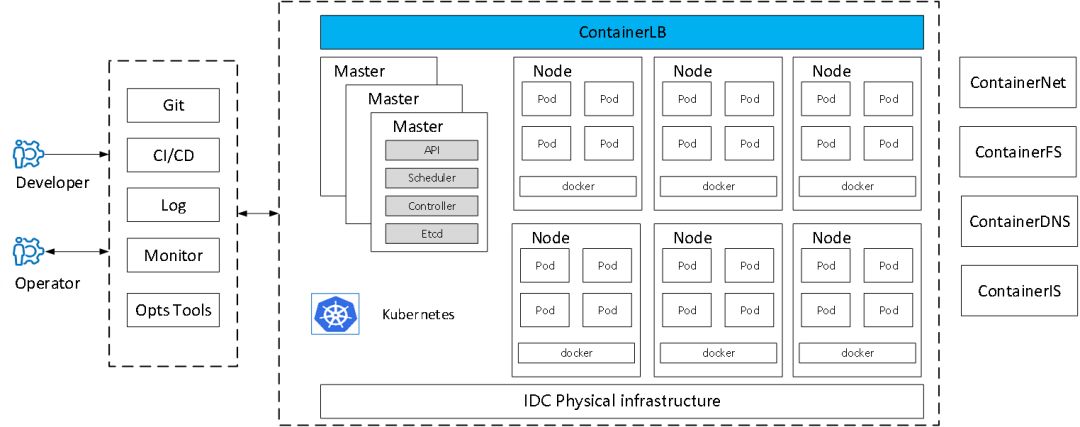
(数据中心的基础架构)
如图所示,我们数据中心的基础架构比较传统,会把负载均衡、域名以及我们包的这个Kubernetes的API统一抽象出来,整个就是一套。然后在每个数据中心部署若干套Kubernetes集群,每一个Kubernetes集群会管理三个物理Pod,大概是一万台的规模。
二、Kubernetes重构、定制与优化
许多人觉得Kubernetes社区很完善,为什么还要自己定制重构?其实这里面存在着一些认识的误区:
社区版本的确提供了相当丰富的功能,但是面对实际的生产环境时,总是会呈现一些水土不服,一个很重要的原因就是开源项目将目标应用和场景设定的过于理想化,而实际的应用需求则是五花八门,甚至千奇百怪的。这也应了那句俗语,看人挑担不吃力,事非经过不知难。因此需要对Kubernetes做必要的做裁剪和加固,用以适应不同的需求。
Kubernetes原生面向的应用比较理想,比如可以无状态启动,具有较好的横向扩展能力。而在实际为业务服务时,就会发现棘手的多。由于一些历史或者其他原因,许多业务的部署还不能达到较高的自动化。并且由于业务本身的一些特性,对于应用的升级也会有着较多的要求。
满足所有的需求当然是不可能的,我们的方法是将需求进行归类、整理和分析,并以此为基础进行定制。另外一种,也就是稳定性能驱动的定制,则主要是为了解决在生产时遇到的一些性能和稳定性的问题而进行的裁剪和优化。
京东基于业务方的各种需求,做了大量的功能性需求开发,很多功能的需求看似很不合理,甚至跟Kubernetes的设计理念冲突,但是当我们跟业务方仔细沟通之后,发现业务方的有些需求是非常合理的。
举个例子,很多业务对IP非常敏感,业务方外围很多其它系统对IP来源有一定的要求,比如黑白名单、数据库授权;还有比如配了很多host,除了有研发还有测试等等,所以我们不得不去面临这个问题,像容器升级更新IP保持不变、指定容器下线、本地缩容扩容、是否开启swap、资源锁定升级、指定不同版本个数灰度更新等这样的一些需求就必须要满足业务方的要求才能更好的推广下去。
业务需求
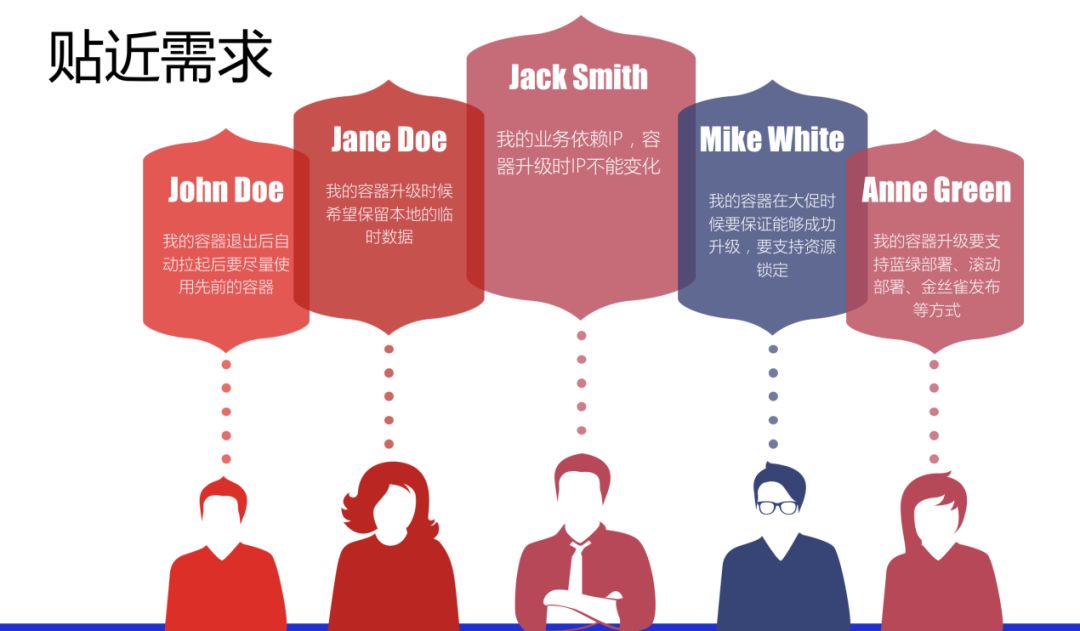
功能定制

node controller
在实践过程中,我们有一个深刻的体会,就是官方的Controller其实是一个参考实现,特别是Node Controller和Taint Controller。
Node的健康状态来自于其通过apiserver的上报。而Controller仅仅依据通过apiserver中获取的上报状态,就进行了一系列的操作,这样的方式是很危险的。因为Controller的信息面非常窄,没法获取更多的信息,这就导致在中间任何一个环节出现问题,比如Node节点网络不稳定、apiserver繁忙,都会出现节点状态的误判。
假设出现了交换机故障,导致大量kubelet无法上报Node状态;Controller进行大量的Pod重建,导致许多原先的健康节点调度了许多Pod,压力增大;甚至部分健康节点被压垮为notready,逐渐雪崩,最终导致整个集群的瘫痪,这种灾难是不可想象的,更是不可接受的。
因此,我们对于Controller进行了重构,节点的状态不仅仅由kubelet上报,在Controller将其置为notready之前,还会进行复核。复核部分交由一个单独的分布式系统完成,这样最大限度的降低了节点误判的概率。
group-controller
用户不仅仅满足于滚动升级,还希望能够较好的支持灰度发布。比如可以控制升级的容器个数,以方便其停留在某个版本上。我们实现了新的group-controller,用以支持该功能。用户可以指定滚动升级后,新版本和旧版本的容器个数。group-controller将最终停留在用户指定的状态。当然,用户也可以进行回滚,从而将新版本的容器个数逐渐减少。
group-controller支持优先本地rebuild的策略。该策略的实行条件为新版本与老版本的容器的规格一致。该策略在升级时,将优先采用使用replace的方式更新老版本的容器,使之成为新版本的容器的方式实现升级。如果没有足够的老容器,则创建新的容器。该策略可以保证用户在更新集群时,更新更加迅速,并且资源(包括容器资源磁盘资源网络资源)不被其它用户抢走,实现了资源锁定的效果。集群资源紧张时,将推荐用户优先使用该策略进行更新,以防止升级后出现容器无法创建的问题。
随着集群规模的扩大,用户为容器配置了大量的configmap。kubelet会定时向apiserver发送请求,获取最新的configmap文件,从而对configmap进行remount更新。
我们对apiserver的请求统计发现,configmap的相关请求,已经可以占到了总请求数的99%以上,这也带给了apiserver巨大压力,而实际中大部分用户的configmap其实是静态使用,也就是只有在容器创建和更新时候才会更新,其应用本身并没有办法动态reload配置文件或者没有需要动态reload配置文件。
鉴于此,我们对configmap的挂载过程进行了优化,使得pod支持静态和动态两种configmap的挂载方式,并默认采用静态挂载的方式进行挂载。对于静态挂载的配置文件,当容器创建、重建、重启时才会进行更新,而动态挂载的则保持现有的方式,即定时进行remount。通过改造,apiserver的请求的qps下降了98%。
我们还做了一些其他的定制和优化,限于篇幅,这里简要提一下,就不做详细展开了:
service支持更为灵活的set-based selector。
支持reuse容器策略。kubelet在容器退出后,可以选择是新创一个新的容器还是直接重新启动刚刚退出的容器。
支持request和limit的修改,以方便用户在重新评估其规格后,调整容器的配置。
rc缩减副本时,可以指定优先删除某几个容器。
grpc包升级,解决apiserver不稳定的问题。
pod支持修改env和volume,方便规格不变的容器直接可以在本地重新新建容器。
pod支持lvm外挂盘,方便进行容量和读写限速。
node支持上报lvm盘容量、devicemapper的data容量(剩余data容量过小时会导致容器无法创建)。scheduler增加相应的predict流程,过滤不适合的节点。
优化scheduler中priority的image相关的计算,对于容器请求的image与有相同镜像名的节点(tag名不同)的,认为两者可能会有共同的基础镜像,给予7的打分。如果完全相同(包括tag名也相同),则给予10的打分。
scheduler增加过滤磁盘过小的节点,防止调度到该节点中因为容器镜像无法拉取导致的容器长时间无法创建。
三、大规模Kubernetes集群运营

为什么要支持大型集群?
参考Borg的经验,一是为了允许运行大型任务,二是为了减少资源碎片。具体展开:
将大型集群划分为多个小型集群相较于整合的大型集群,需要更多的额外机器。
例如,将一个大型集群划分为两个小型集群,需要25~50%的额外机器。
大型集群还有利于离线和在线业务混合部署,相较于混合部署,将离线和在线业务进行隔离部署需要额外增加20~30%的机器。
不同用户的任务隔离部署较之混合部署,需要额外增加20~150%的机器。
可以看出,大型集群将资源池化可以显著节省成本。
目前经过我们优化,JDOS2.0的单个集群规模可以支持万台节点的规模了。
有些人会说,Kubernetes已经这么成熟了,都是开源的,而且已经有这么多的工具进行部署监控了,集群的运维会有什么难度?
其实不然,集群运营,特别是大规模集群运营,需要丰富的经验,成熟的体系,辅助的工具链等等,因此其难度并不亚于开发一套大型系统。
所谓治大国若烹小鲜,集群需要精细化的运营,对于细节的要求更是严格甚至苛刻。因为你直面的是生产环境,作为基础设施和平台,小小的疏漏可能会酿成规模性的灾难后果,这也是被无数案例实证过的教训。
所以,在上生产环境前,我们的建议是要问一下自己:大规模集群,你准备好了么?如何准备,相信很多人会一下子感觉无处着手,没有头绪。这里,我们把我们的一些经验分享给大家。

稳定是基础设施的生命线。所谓皮之不存,毛将焉附。如果没有稳定,那么其他的再多花哨的功能也没有存在的必要和基础。从OpenStack,到Kubernetes,我们团队积累了丰富的运营经验,特别对于稳定的需求,深有体会。我们将对稳定的需求总结为了稳定三问。在集群运营之前,就可以先对照这三个问题来看看自己的集群是否足够稳固。
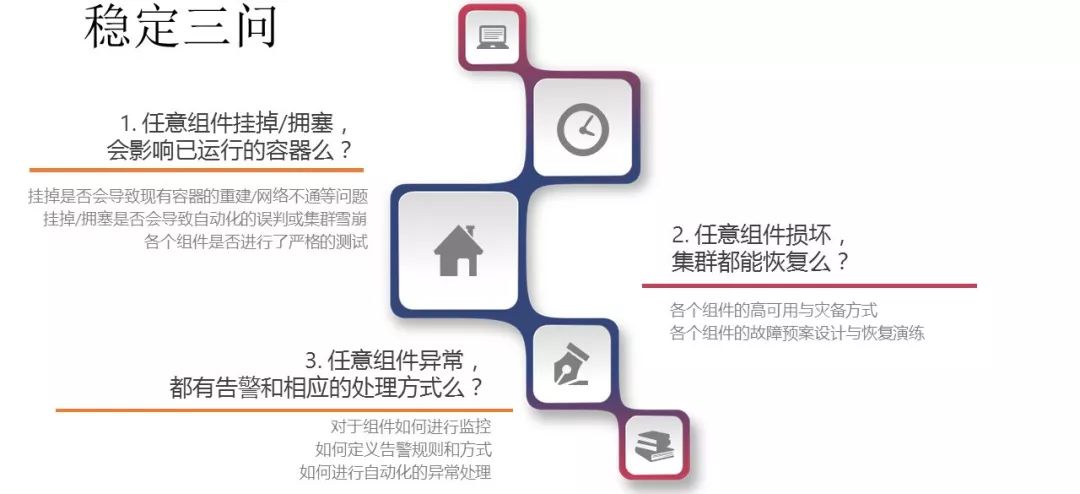
第一问:任意组件挂掉/拥塞,会影响已运行的容器么?
从OpenStack到Kubernetes,集群管理都是由若干项目若干个组件组成的。这些组件相互合作,构建成了整个容器的生态。这其中,有集群管理的组件、网络管理的组件、存储管理的组件、镜像管理的组件……凡此种种,都属于本文中的组件范畴。
第一问在OpenStack中容易回答一些,因为相对来说,OpenStack对于容器的使用是静态的,因此组件的故障对于已经运行的容器来说,影响会比较小。而Kubernetes的运营难度较之OpenStack大大提升,其中一个很重要的原因就是controller的存在。在实现了较高的自动化的同时,也带来了许多潜在的风险。
举例来说,由于某种原因,导致apiserver多个节点故障,仅一台apiserver进行工作,此时大量的请求(来自于kubelet、scheduler、controller及外部的api请求)均涌入apiserver,导致apiserver很快到达负载上限,大量返回409错误。
此时可能若干节点的kubelet均无法正常上报心跳,在controller处会将其置为not ready。而后可能会导致由rs触发重启的重建,service摘除相对应节点上容器的流量等等。
但实际上,这些节点的容器其实原本是正常运行的,出现问题的仅仅是apiserver的拥塞而已。
又比如,采用的网络方案,如果网络元数据的存储故障了,是否会导致现有容器的网络受到影响,是否会导致网络瘫痪?
展开来说,“任意组件的挂掉/拥塞是否会导致正常容器的重建/网络不通等问题?挂掉/拥塞是否会导致自动化的误判或者集群的雪崩?所有的组件是否都得到了严格的测试?”这些问题均需要认真的审视,对各个组件的工作原理和流程进行详细的梳理,以确保各个环节都在掌握之中。
第二问:任意组件损坏,集群都能恢复么?
组件的故障,无论是由于组件本身亦或是组件所在的节点故障,在大规模的加持下,发生的概率会大大提高。因此对于各个组件做高可用,设计灾备方式都是十分必要的。
不仅如此,对于各组件,特别是关键组件要进行故障的预案设计,并进行恢复演练。正所谓养兵千日,用兵一时。到真正出现故障时,不至于手忙脚乱,毫无头绪。
这里以etcd为例。
毫无疑问,etcd是Kubernetes的核心中枢,但是etcd并不是想象中那么万无一失。在实际中,遇到过多次莫名其妙的故障,导致整个etcd集群无法写入数据,甚至完全故障。最后不得不启动先前的故障预案。
在之前的故障预案中,我们做了多种计划和多次演练,包括:
上策:从etcd集群原节点恢复;
中策:将数据迁移到新的节点进行恢复;
下策:从定时备份的数据中恢复。如果从定时备份的数据中恢复,则难免会有一部分数据丢失。
在实际中,我们遇到过的最坏情况是将数据迁移到新节点进行集群重建恢复。但是三种情况的演练仍然是必要的,以确保在最坏情况下,仍然能最大限度的保障集群的稳定和安全。
第三问:任意组件异常,都有告警和相应的处理方式么?
组件的故障异常既然不可避免,那么对于如何对组件进行监控告警、如何定义告警的规则和和方式以及告警后如何接入自动化的处理就需要进行认真的思考。
比如,各个组件所在的容器/物理机需要配合相应的资源监控告警,组件本身也需要进行健康检查等方式的监控告警,甚而,还需要对组件本身的性能数据进行监控告警。从宏观角度来说,各个组件其实也是一种应用,是平台层或者系统层的应用。所以对于传统的业务应用的一些监控告警手段,一样也可以用于这些组件之上。
集群的运营不能靠运维人员的感觉,而是要依赖数据支持。集群运营的数据采集自集群的各个组件,用以反映各个组件的状态、性能等指标,为集群规模的估计提供参考。
运营数据的采集方式多种多样,可以来自于组件的上报,暴露对应的数据接口,通过日志进行数据分析等等。以apiserver为例,apiserver的主要相关数据包括每秒api请求的数量、请求时间的统计等。在我们的实际运营中,则更加精细化,通过对于apiserver日志的分析,进而统计出每个请求的请求方法、请求的资源类型、namespace、资源名称、请求时间、来源ip等等信息,使用TSDB,在多个维度上进行聚合分析。
以某个测试集群为例,该集群大概1000台node的规模,pod数约为25,000个,而配合的configmap数达到了15,000。在未进行优化前,api的QPS可以达到8500+。
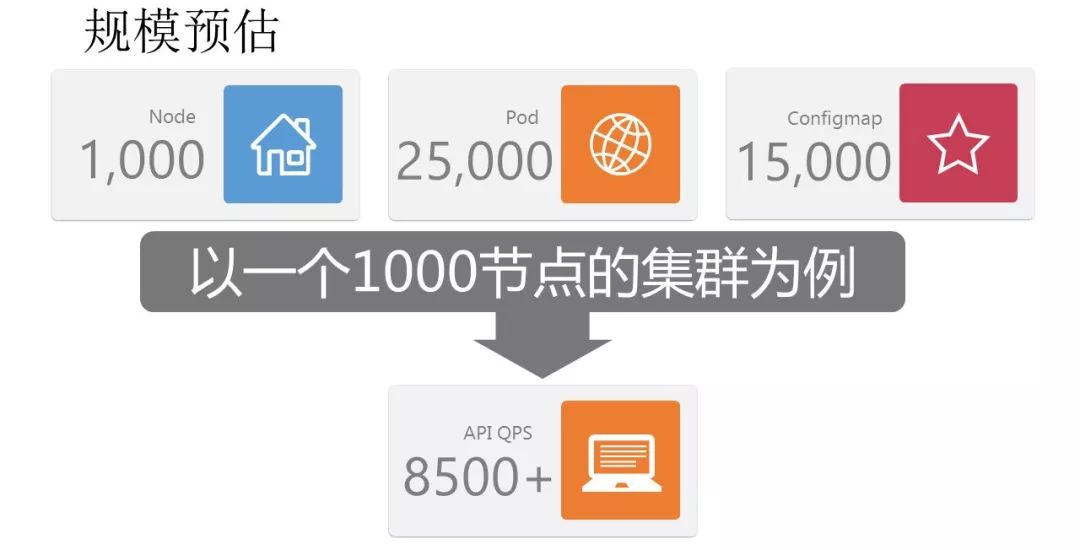
我们通过对于请求资源类型的分析,发现api各请求资源类型中configmap占比可以到90%以上。通过进一步分析后,对configmap进行了改造,使之支持动态和静态挂载两种方式,将api的请求数缩减了98%,优化后该集群api请求仅为140+。
集群规模不断扩大,因此对于集群的状态需要进行宏观的表达。一种简介明了的方式就是将运营的数据进行收集整理,并使之可视化。
实际的运营人员与Kubernetes的研发人员对于Kubernetes的掌控能力会有一定的区别,因此可视化可以极大地方便运维人员更好的掌握集群的状态,通过图表对集群的状态和性能有更加直观的感受和体验。
同时,可视化也可以清晰看到数据变化的趋势,并结合数据分析集群目前可能存在的问题和遇到的瓶颈以及优化前后的对比,对Kubernetes的研发人员也有着极大的参考价值。
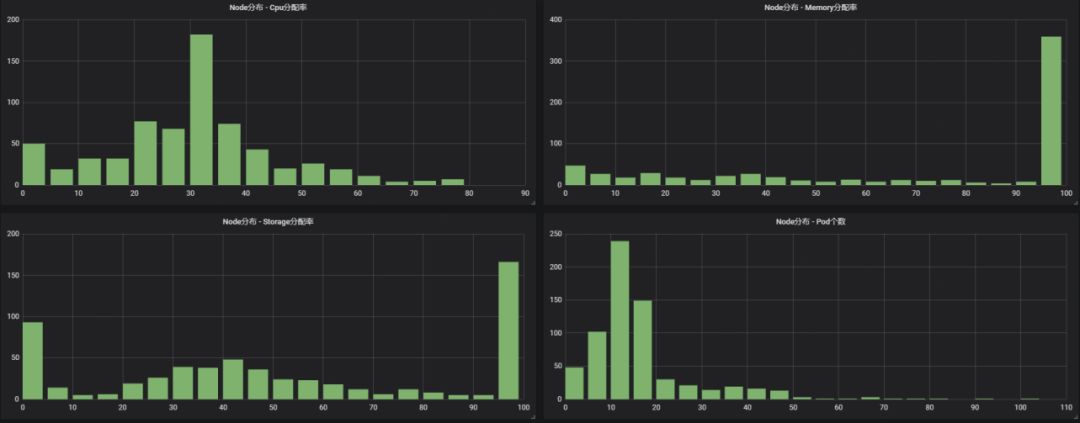
借助于运营数据的收集和可视化,我们发现了更多在集群规模扩充时可能发生瓶颈的潜在问题,也对其进行了优化处理。
etcd的容量。etcd默认是2G的容量,在大规模的集群下很容易达到瓶颈。因此可以根据不同的resource进行分开不同的etcd集群进行存储,同时修改etcd默认的容量上限。
etcd读速率。统计发现,API中大部分为GET请求,因此采用Redis缓存数据,用以疏解GET请求。
调度耗时。随着节点数的增加,调度的predict、priority流程耗时也随之呈现线性增长。我们删减了不必要的predict和priority函数,支持采用自适应步长的方式,在小幅牺牲调度准确性的基础上,大幅度提升了调度的速率和吞吐量。
镜像中心存储规模与镜像拉取速度。镜像中心我们使用了自研的containerFS进行存储,并在各个数据中心提供了缓存和P2P加速,保证了镜像中心的可扩展性。
大规模的运营需要成套的运营工具链进行辅助,缓解运营人员的工作压力,同时也提供更为自动化的流程,对整个集群提供更为稳固的保障。
巡检工具
日常巡检系统对于及时发现物理机及各个服务的异常配置和状态非常重要,尤其是大促期间,系统的角落有些许异常可能就带来及其恶劣的影响,因此特殊时期我们还会加大巡检的频率。 巡检的系统的巡检模块都是可插拔的,巡检点可以根据需求灵活配置。我们将巡检系统用在了各个组件上,用以检查配置、状态、参数等等。

Kubernetes ansible connection plugin
日常的运营管理我们使用的是基于Ansible开发的定制工具,其中部署集群、扩容集群、更新配置、升级代码等操作都有已经定制好的模板。当上线时,只需要修改模板中的几个参数就可以成功更新,省时省力,十几万物理机的规模只需要几个运营人员就可以轻松管理。
为了方便直接操作各个容器,我们还开发了Ansible的Kubernetes插件,可以通过Ansible对容器进行批量的诸如更新密码、分发文件、执行命令等操作。
hosts配置:

结果样例:
该plugin我们已经贡献给社区,并合入了Ansible。
其他工具
除此之外,我们还开发了其他许多工具,这里作一下简要介绍,就不一一详述了:
kubesql:可以将Kubernetes的如Pod、Service、Node等资源,处理成类似于关系数据库中的表。这样就可以使用SQL语句对于相关资源进行查询。比如可以使用select count(metadata.name) from kubepod where metadata.namespace = 'default'来查询ns为default的容器个数。
event事件通知:监听event,并根据event事件进行分级,对于紧急事件接入告警处理,可以通过邮件或者短信通知到相关运维人员。
-
pod/node全纪录:监听记录pod/node的有效状态变化,并记录入数据库中。可以方便查询pod/node的变化历史。
Q1:一般node的配置多少内存CPU?
A:node的配置与硬件的批次有关,内存一般都有128G或者256G,CPU为32核或者64核。
Q2:node可以使用物理机吗?
A:可以。
Q3:网络选型是什么?或者说有什么这块的经验?
A:网络这块采用的是自研网络方案,支持百万级容器网络ContainerNet。
https://m.qlchat.com/topic/details?topicId=2000001624688863
彩蛋来了
在本文微信订阅号(dbaplus)评论区留下足以引起共鸣的真知灼见,小编将在本文发布后的隔天中午12点选出留言最精彩的一位读者,送出以下书籍一本~
注:同一个月里,已获赠者将不可重复拿书。
近期热文
近期活动
(点击上图可查看详情并报名)
(点击上图可查看详情并报名)
以上是关于京东大规模Kubernetes集群的精细化运营(有彩蛋)的主要内容,如果未能解决你的问题,请参考以下文章
京东是如何打造全球最大Kubernetes集群支撑万亿电商交易的
云原生在京东丨最适合云原生的分布式存储平台—— ChubaoFS