技术分享:基于 Kubernetes 的 AI 训练实践
Posted 七牛云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术分享:基于 Kubernetes 的 AI 训练实践相关的知识,希望对你有一定的参考价值。
2017 China KEUC(Kubernetes End User Conference)秉承开放协作、技术共享的宗旨,致力于为业界带来最新 Kubernetes 技术、行业应用案例展示与最佳实践,同时将中国已有的优秀实践经验推广到全球,这对于 Kubernetes 从理论到落地推广、并走向国际化将有着极为深远的意义。近日,七牛云亮相Kubernetes 中国用户大会,来自七牛容器云部门的后端研发的陆龙文,聚焦 Kubernetes 新特性,发表精彩的主题演讲。
七牛云的 AI 部门属于容器云部门的客户,针对于 AI 训练这样一个特殊的训练场景,具体落实到 k8s 的实践上具体实施工作怎样做的,带给七牛怎样的好处,以及从中碰到一些什么样的问题陆龙文对此做了分享。
1
AI 训练的业务情况
七牛本身有一个深度学习的平台,这是一个端到端的深度学习平台,包括从对原始富媒体数据的打标,到制成一个可以被训练任务读取的样本集,到训练任务的触发以及训练成果的存储,包括对于最后训练出来模型的评估,评估完成以后最后将这个模型打包成你的线上业务,通过 API 形式对外提供服务一整套流程的平台。
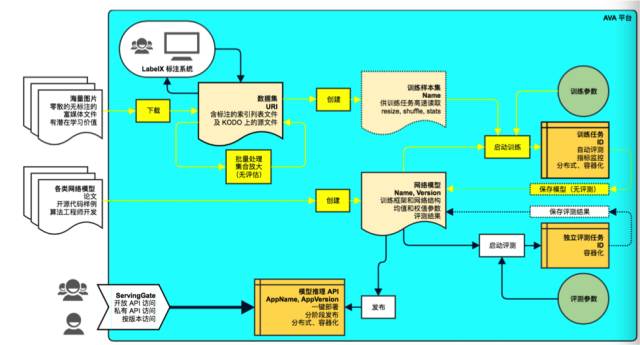
AI 训练是这个平台中的一个部分。AI训练迭代是怎样的一个事情?
AI 训练迭代分两个阶段:
第一,样本集的生成,任务输入是两个:一是来自于七牛对象存储的原始数据,主要是一些图片、音视频流富媒体数据;二是 ava 平台本身有一个打标系统,可以对原始数据进行标签,通过样本生成器生成样本集,存储到容器云平台的存储当中,这是一个分布式的网络存储。
第二,一旦你的样本集生成完成以后会自动触发或者人工触发一个训练任务进行一个训练,读取整个平台由算法工程师事前准备的算法模型、训练参数到你的训练任务当中进行 。
训练,最后将你的训练任务输出到存储,最后上传到对象存储当中去的整个过程。
2
Kubernetes 的优势
我们这边遇到的痛点是什么?
第一,使用 Kubernetes 做平台之前,训练流程上需要算法工程师通过脚本、控制训练任务的触发以及训练任务要存储到什么地方,同时训练任务可能因为一些硬件错误导致失败,失败需要人工介入。
第二,资源规划方面,GPU 集群是很多人共享的,其中 GPU 资源需要人为协调,耗费掉很多精力。
第三,训练任务完成以后并没有把占用的 GPU 释放掉,造成一定的资源浪费。
第四,存储,训练任务的存储往往是非常大的样本集,需要容量非常大的网络存储支撑,在此之前我是用的是 NFS,服务可用性没有办法达到需求,水平扩展以及性能也没有办法满足训练任务的要求。
k8s 主要有两个优势:
第一,k8s 支持 GPU 调度的,我们积极将整个实践过程当中取得的成果回馈到社区;
第二,k8s 支持多种 Workload 的调度方式,适应不同的业务场景,JOB 与训练任务两者切合度非常高。
k8s 和现在开源社区结合非常好,包括监控日志方案社区已经取得了相当成果,在搭建平台的时候这个部分省了很多人力。
3
基于 Kubernetes 的 AI 训练
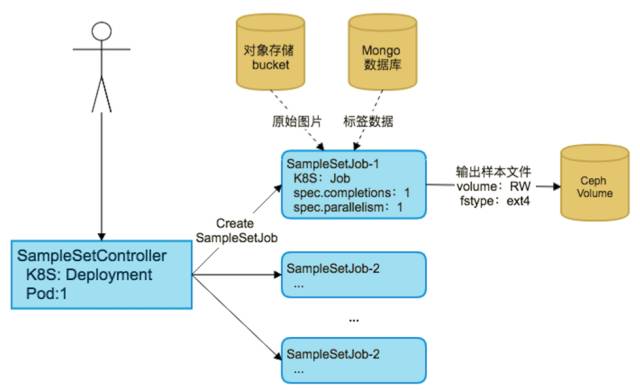
AI 训练-生成样本集
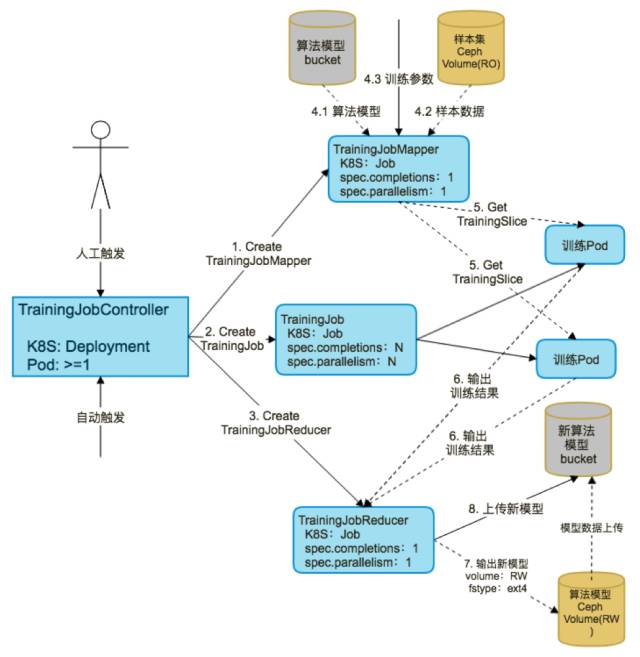
整个调度仅仅利用 k8s 调度没有办法很好的满足业务需求,我们对样本集的生成有 SampleJobController 做整个样本集生成任务的调度,生成任务从对象存储和 mongo 数据库中读取输入数据,产出一个样本集输入到 CEPH 存储。
AI 训练-启动训练任务
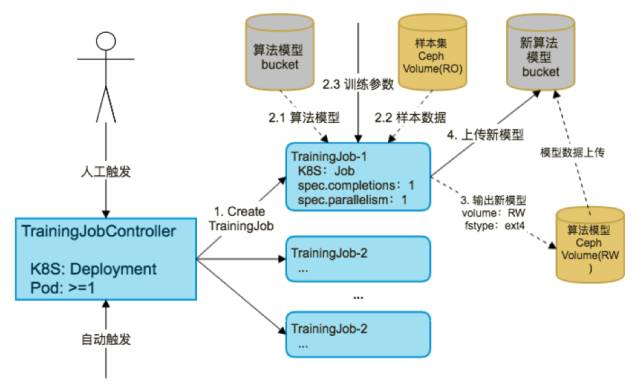
以上任务完成以后会触发一个 Training Job Controller 的训练任务,这个训练任务从刚刚的样本集里读取数据,同时配合算法模型和训练参数,对于算法模型的权重进行计算,最后训练完成以后再将新的算法模型输出到 CEPH 存储当中,如果评估下来比较好的话可以上传到对象存储当中,CEPH 这部分存储资源可以释放掉了。
AI 训练-使用 CEPH 存储
使用的 CEPH 存储训练 AI 训练任务场景主要有三个好处:
第一,数据规模可以支持非常大,最大样本集可以达到一个样本集 10T 数据,需要读取数据服务一定需要有一个网络共享来支撑,这样在物理机发生故障时,pod 在别处被重启后仍然能访问之前的数据;
第二, CEPH 存储是分布式存储,水平扩展性非常良好,训练级规模上升以后可以很快速的进行水平扩展;
第三,读写控制,Kubernetes 一个独占的读写和多个 Pod 同时读取的模型,适用于训练模型的整个流程,包括之前样本集生成有一个样本生成,一旦完成以后可以进入只读模式,多个任务同时读取进行并发训练。CEPH 使用过程中我们把积极地改进回馈给社区,比如说 ImageFormat2 的支持,还有 k8s 对 CEPH 调度需要有一个 Provisioner 去支持的,现在整个社区演进方向希望将这些存储 Provisioner 全部变成独立部署的形式,便于它的升级扩展。
GPU资源规划采用Node Label+Node Selector,对训练任务进行调度,我们的 GPU 卡可能有不同的型号,对不同训练任务会有型号上的偏好,这个时候可以为每一台机器上装的具体型号的显卡帮助它打上一个标签,之后进行训练任务调度的时候可以使用 Node Selector 将这个任务调度上去。
关于资源方面的,Kubernetes 提供了比较好的 Limits+request 资源分配模型,Limits 表示这个 Pod 最多使用多少资源,Request 是说要将这个任务调度起来最少需要多少资源,目前对于 GPU 这样的模型没有办法很好的工作,我们缺少一个有效的机制监控 GPU 使用多少,限制对 GPU 使用,对于 CPU 和 Memory 可以有效的使用这样的模型,进行合理超卖,提资源的利用率。
关于 Nvidia GPU Driver,训练任务需要在 Pod 当中使用具体显卡的驱动,每一台机器安装不
同型号的显卡驱动版本也是不一样的,但是我们 Pod 并不关心这个版本,只是调度到这台机器上就需要这台机器上对应型号显卡的驱动,我就可以通过 k8s 的 Hostpath 方式挂载到 Pod上去,打包镜像的时候完全不需要关心 GPU 驱动这个事情。
物理机监控
基于 Prometheus Node Exporter
获取 CPU、内存、磁盘、网络维度信息
容器监控
kubelet 内嵌 cadvisor
监控注册
Prometheus 从 kubernetes apiserver 获取需监控的资源
GPU 监控
GPU 使用率
现存使用率
GPU核心使用率
关于监控和日志方案采用的是 Prometheus,它本身提供的 Prometheus Node Exporter 可以很好的帮助我们关注整个集群里物理机结构的信息,kubelet 里已经集成 cadvisor 帮助我们提供容器内部的监控信息,我们还在上面做了一个改进就是将 GPU 的监控信息添加到监控方案当中去,并且贡献给社区。
关于日志方案我们采用了由七牛自主研发的分片的 Elastic Search 自研的 Sharding 集群,承载了目前所有七牛的业务数据以及包括外部客户的数据,把 Elastic Search 运维的工作完全交付给七牛 pandora 日志存储分析平台。
4
一次踩坑经历
接下来分享一下我们在运维当中碰到的问题,最后造成很严重后果的事故,首先介绍要一下 k8s 使用 CEPH 存储是怎样一个过程?我们知道 CEPH 存储是通过 CEPH 的 RBD 命令,将 CEPH 的 image attach 到你的宿主机成为一个块设备,k8s 将这个设备 Mount 到 Kubelet 的Pulgins 文件夹下面,再次通过 Mount rbind 的方式绑定到对应需要的 POD 的目录下,这是 CEPH image 绑定到 POD 的过程。 mount rbind 是挂载命令,本身是有三种模式: Shared、slave、private,k8s 在使用的时候是 1.6,仅仅支持 Private 模式。
因为这样一个原因导致了故障的发生:我们有一个容器 A 已经运行起来了,是只读的方式挂载了一个存储,接下来 Node Exporter 要进行监控采集,为了获取某些监控数据,会以 Make-private 挂载整个宿主机根目录,刚才提到已经有容器 A 将 RBD Volume 挂在起来了,势必之后的挂载也将这个带到了 Promethus 的 Node Exporter,导致了 A 容器运行完成以后将容器销毁了,卸载 RBD Volume 成功,但是 RBD umap 失败,主要是因为 Node-Exporter 仍在在 RO 挂载。我们也没有发现这个问题。
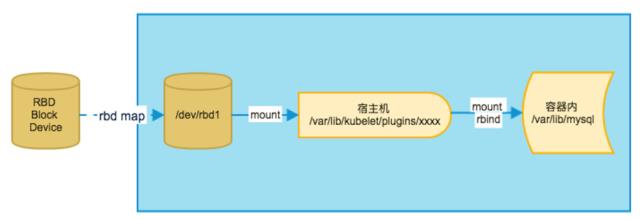
又一个新的容器 B 要试图读取这个 Volume 的时候,发现这个 Volume 这个设备已经存在物理机上,再次以读取的方式挂载,导致了挂载失败,k8s 在这种情况下会试图获取设备的文件系统信息,因为我们之前犯的另外一个错误,获取文件信息就失败了,k8s 获取文件信息是空的,处理方式也比较简单粗暴,认为获取失败这个盘就是没有格式化过的,就触发了格式化,把我们之前训练好的数据直接全部格式化掉了。
整个故障原因就是 Node-exporter 挂载根目录方式比较危险,导致了之后挂载 ceph 卷失败。挂载卷失败这原本不是一个太严重的问题,也是因为我们之前部署上的问题导致了 ceph 服务端和客户端版本不一致,致使获取文件信息失败,本身 k8s 对这种情况处理方式简单粗暴,种种原因放在一起导致了整个事故的发生。反思这次事故,主要有几个点:
第一,部署流程需要固化,因为我们每次部署都要需要人手工操作,一些配置文件都是当时修改出来的,要把整个部署流程固化下来,在部署完成以后要检查相应的版本。
第二,即便你真正犯了错误的时候,需要有一个完整的机制把系统组件的日志抓取出来,配置成告警的形式及时的跟进,因为回顾排查的时候由于版本不一致的问题已经在日常工作中产生了错误日志,但是我们并没有引起重视,一直到事故发生,发生数据丢掉的时候回过头来看的时候才发现这个问题。

第三,对于 Kubernetes 使用知识了解不够,这些知识也是对整个事故跟进的时候,发现 Kubernetes 处理逻辑是这个样子的。团队对于 Kubernetes 相关处理逻辑要进行梳理,避免一些潜在的隐患。最终我们通过使用二进制在物理机部署 Node Exporter 的方式来暂时缓解这个问题。
5
接下来的工作
第一,自配置监控。Prometheus 对 k8s 的支持是比较好的,现在已经支持自动从 k8s 的 APIServer 里获取 Service,发现需要抓量的 Service 自动抓取,这个已经应用到系统组件当中,但是对于我们的AI训练服务,自动配置的监控工作还没有落实,这是我们接下来要完善的一步。
第二,分布式训练。我们整个训练模型还是单机版的模式,对于一个比较完整的深度学习平台需要有一个分布式学习的方式,也需要容器团队和 AI 团队一起梳理整个业务流程从而去支撑这样一个训练方式。
我们接下来的作也把我们现在关于 Kubernetes 运维经验产品化以后变成七牛公有云的平台,会在 11 月份上线 preview 版本。

福利时间
七牛容器云产品内测
正式开启
扫描下方二维码
免费申请试用
友情推广
点击「阅读原文」领取福利
以上是关于技术分享:基于 Kubernetes 的 AI 训练实践的主要内容,如果未能解决你的问题,请参考以下文章
与京东交谈:Kubernetes云原生和CNCF项目推动大数据和AI
摆脱 AI 生产“小作坊”:如何基于 Kubernetes 构建云原生 AI 平台
工艺分享 || 基于代谢网络模型和AI技术预测CHO细胞营养物质消耗速率