快手基于 Kubernetes 与 Istio 的容器云落地实践
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快手基于 Kubernetes 与 Istio 的容器云落地实践相关的知识,希望对你有一定的参考价值。
作者简介
张夏
快手 资深技术专家

大家好,我是来自快⼿的张夏,今天非常荣幸能有机会分享和交流快⼿在Kubernetes、CI/CD,以及 Service Mesh 的一些实践。
今天分享的内容,主要有以下⼏个方⾯:
基于 Kubernetes 容器云建设
利用 Helm 应⽤发布与管理
采用 Gitlab CI/CD 构建 CI/CD
使用 Istio 进⾏行微服务治理
随着近几年微服务化与 DevOps 的兴起,容器不止在国内外大型互联网公司中深受追捧,即使对于传统⾏业或一些规模相对较小的企业,对于容器化也是摩拳擦掌、跃跃欲试。
容器落地需要解决2个方面的问题: 首先,容器技术本身存在的问题和不足,另外,新技术如何与公司现有系统快速对接。
那么我主要针对以上2个方⾯,来说明下容器化落地要面临和解决的问题。
1. 基于 Kubernetes 的容器云建设

首先,对于容器技术本身来说,国内的 IDC 环境的不稳定众所周知,跨 IDC 的网络抖动有时比较厉害,跨机房容灾就是我们一个难点;接下来,我们面对的是如何在保证服务质量前提下,提供计算资源的利⽤率。容器化之后,大家还吐槽的⼀个问题是 debug 起来比较困难了,容器化之前直接ssh 登录到机器上可以随心所欲、为所欲为,但现在容器化后限制了想象。
另外,容器的生命周期是短暂和不确定的,比如内核问题导致系统崩溃,容器漂移到别的机器上,如果数据保留在本地,就会导致容器服务迁移但数据没有迁移的困境等。
对于容器化落地,对于非初创公司,⼀般都是投⼊了⼤量的⼈⼒物⼒造就了祖传的⼯具和平台系统,引⼊容器之后呢,不大可能会从头推倒重来,更快速的对接现有系统平台才是正道。但⼈间正道是沧桑,新⽼技术对接并不会⼀帆风顺,如何更多快好省的对接,使容器技术在公司快速的落地,是我们需要考虑的问题。
术业有专攻,开发⼈员⼀般并不关⼼容器化技术的⼀些细节,学习成本越少越好,越简单易⽤、傻⽠式越好。
上⾯介绍完容器落地难点之后呢,我来介绍下快⼿在容器化之路的一些实践。期望可以多、快、好、省的踏上容器化之路。
首先,我会⾸先介绍下基于 Kubernetes 的容器云中的⼀些实践,避免走⼀些弯路;接下来我会介绍下基于 Gitlab CI 的CI/CD,作为有历史包袱的公司,即使采⽤相同的技术栈,做出的 CI/CD 也五花八门,甚至一个公司内部不同部⻔也会有不同的 CI/CD 方案,⽐如某鹅厂。
第三部分,会介绍下 Kubernetes 服务编排领域的唯一开源⼦项目 Helm 进⾏应⽤编排和应用级别的配置管理,最后会介绍下近⼀年快被炒糊了的 ServiceMesh 落地的⼀些经验。

我之前经常被问到⼀个问题之⼀就是: 为什么要自己开发容器云,⽽不直接用⼤大⼚提供的⼀站式容器云⽅案。当你真正打算落地业务的时候,发现现有的容器云方案各种水土不服,定制开发也会非常的麻烦。
我们不生产容器,我们只是容器的搬运⼯。下⾯介绍下搭建私有容器云过程的一些实践,为即将容器化或正在容器化的同学们提供一个参考。
我们先看⼀下容器云的架构,分为几个部分来阐述:
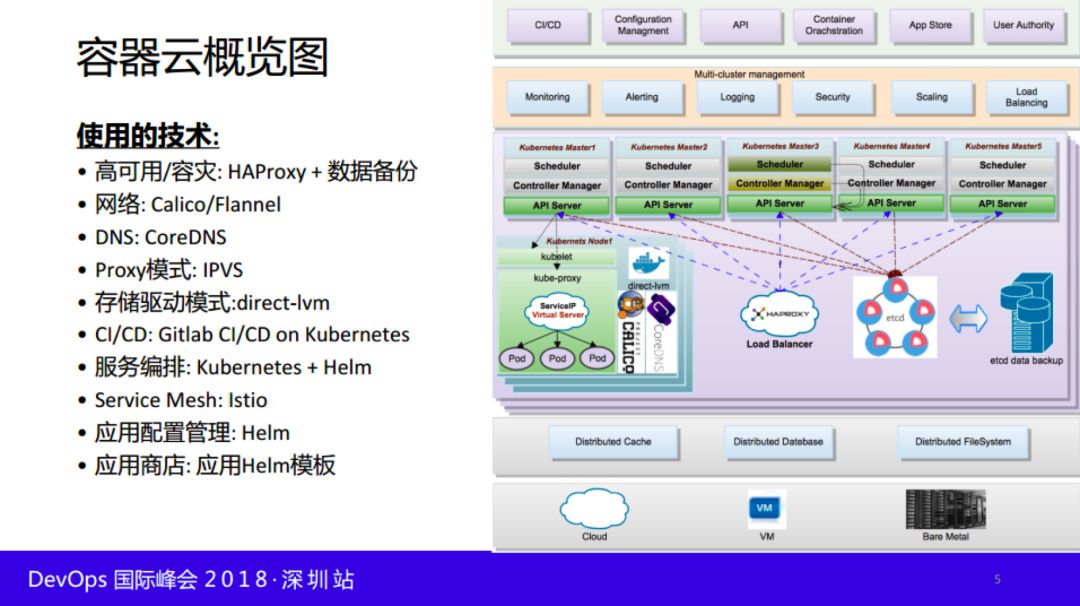
使用的技术如下:
高可用/容灾:Haproxy/DPVS
数据备份:etcd
网络:Calico/Flannel
DNS:CoreDNS
Proxy模式:IPVS
存储驱动模式:direct - LVM
CI/CD:Gitab CI/CD on Kubernetes
服务编排:Kubernetes + HELM等等
Service Mesh:Istio
应用配置管理:Helm
应用商店:应用HELM模板

首先,看下容器镜像构建实践,构建容器镜像,刚开始使用容器时,被用户吐槽 Dockerfile 学习成本高,构建、拉取镜像慢等问题,这些问题 Docker 不能背锅,像造手机一样,都是友商提供的硬件,手机⼚商要做的事情就是把积木堆好。我们也是一样,通过充分的利⽤ Docker 的镜像分层复⽤功能和微镜像就可以很好地解决这个问题。
关于镜像层数,最需要做的是减少镜像层数,细⼼的同学可能注意到,构建一个 Docker 镜像时,对于 Dockerfile 里面的每命令行,⾄少要分为3个步骤:首先,启动一个临时容器,执行 Dockerfile 命令行中的命令,然后执⾏ docker commit命令通过容器⽣成一个镜像,最后销毁临时容器。
之前场景在 docker后台进程⽐较忙的时候,创建容器、commit、销毁容器3个步骤,⼤概需要⼗几秒时间。简单的说,减少一个 Dockerfile 命令行,可以节省约十⼏秒的时间,量化一下,一个Dockerfile ⾥有30个命令⾏,如果可以合并为10⾏以内呢,可以节省20*10秒的构建时间。
我们如何减少镜像层数的呢? 我们把 Docker 镜像进行逻辑的分层,目的是更好的复用。
接下来谈⼀下微镜像Alpine,Alpine Linux 是⼀款独立的⾮商业性的通⽤ Linux 发行版,Alpine Linux 围绕 musl libc 和 busybox 构建,尽管体积很小,Apline 提供了完整的 Linux 环境,其存储库中还包含了⼤量的软件包备选,它采⽤自有的名为 apk 的包管理器。
⽤Alpine跑了JDK8的镜像结果发现,JDK还是无法执⾏行。后来翻阅文档才发现Java是基于GUN Standard C library(glibc),⽽Alpine是基于MUSL libc(mini libc),所以Alpine需要安装glibc的库,以下是官方给出wiki:
https://wiki.alpinelinux.org/wiki/Running_glibc_programs。
至于如何安装,可以参考:https://github.com/sgerrand/alpine-pkg-glibc 。

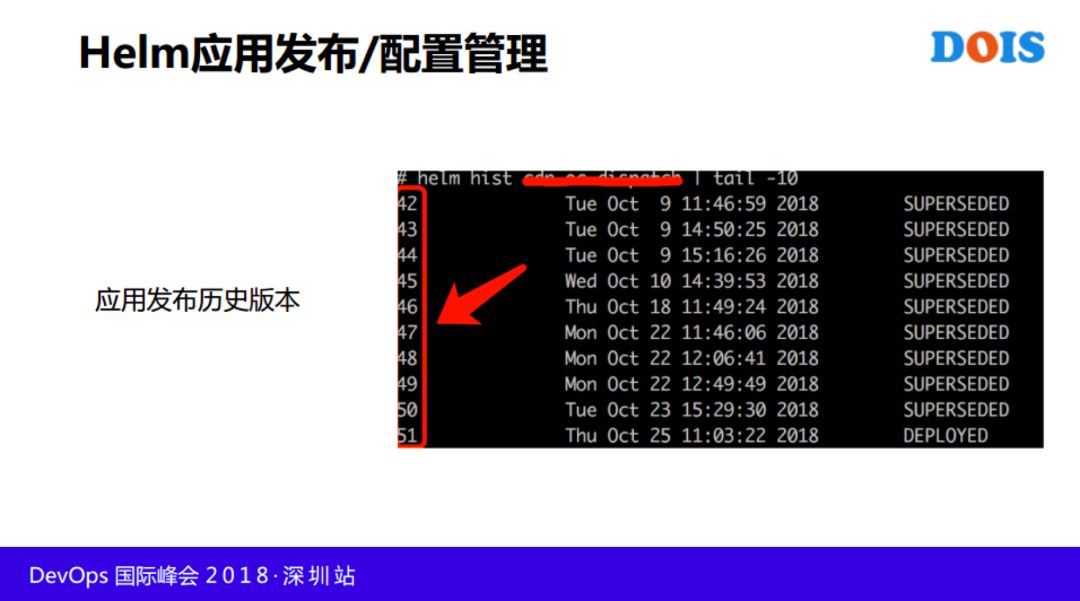
用Helm部署与管理复杂Kubernetes应用,基于GO模板语言,实现应用快速部署到K8s集群。Helm 是K8s服务编排唯一开源项目,做为K8s包管理工具,用于部署复杂K8s应用,处理复杂的服务间依赖。另外,可以用 Helm 查看发布历史与某一次发布的具体配置。

Helm采用了模板+配置的形式,针对不同的环境,无需修改模板,通过修改配置就可以发布到不同环境之中。

可以通过开源的 ChartMuseum 管理 Helm Chart 包。
 对应用可能发布多个版本,希望通过HELM看到历史发布的信息,一个应用发布了三次,第三次有问题,需要回滚,但不知道回滚第一次还是第二次合适,需要查看历史版本配置的功能。
对应用可能发布多个版本,希望通过HELM看到历史发布的信息,一个应用发布了三次,第三次有问题,需要回滚,但不知道回滚第一次还是第二次合适,需要查看历史版本配置的功能。
这就是我们刚才提的,如果用K8S处理的话,处理依赖的话,K8S用INITCONANIER,或者POSTSTORT、PRESTOP去做两个埋点,比如说在升级的时候,无论是蓝绿或者是灰度,做的时候考虑升级服务一定不能影响现在正在提供的服务,我们可以通过埋点做这个事情。

即使没有状态的服务,升级/回滚也不是无损的,因为要删除容器。我们看一下QoS,线下无所谓,预发布环境,线下环境,没有关系我们直接用K8S两个类型,可以提高自然利用率,但是一旦是我们线上环境,上容器化,新上经验不是很多的情况,建议都是用容器的方式做,定额分配资源,不会造成资源竞争。

相对来讲的话,只要分配给资源,K8S集群统一调度,不会与资源竞争。我们看一下服务发现,环境变量注入的方式不太推荐,早期采用了 Linux 环境变量方式,为每个 Service 生成对应的 Linux 环境变量,并在POD启动时,自动注入这些变量。

DNS我们推荐,通过ADD-ON方式引入DNS功能,通过把SERVICE NAME作为DNS域名,为了更简单把GUESTBOOK的例子摘出来的。大家可以看一下。
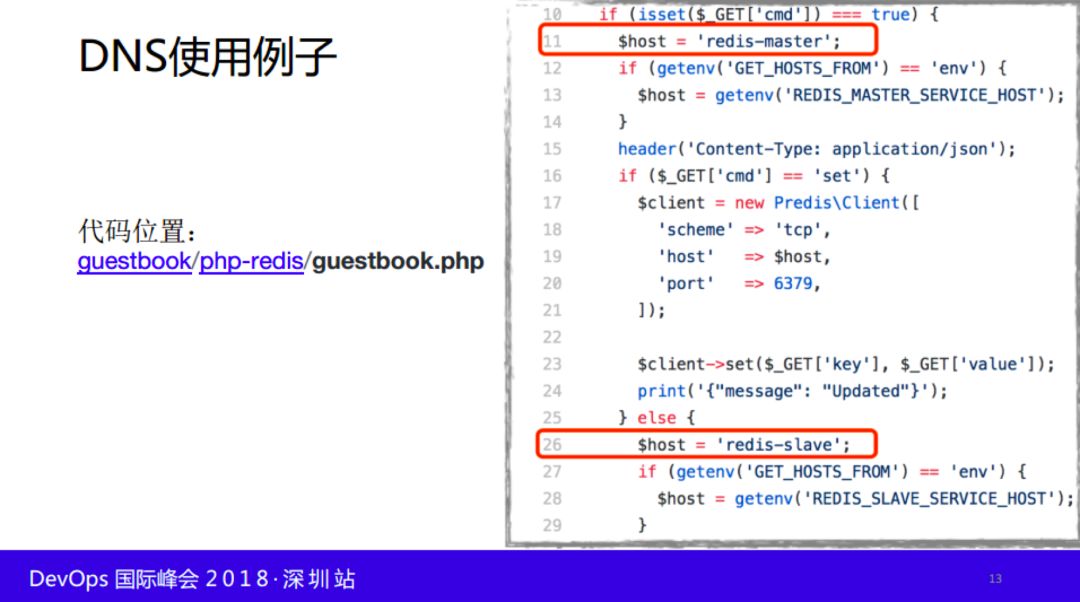
看一下七层服务发现,基于内部相互的去寻找另外一个服务,但是七层我们想集群外部,比如说容器化了,希望访问到别的容器服务,或者是别的集群服务,或者是我访问,或者外面的非容器内想访问容器内部的服务。

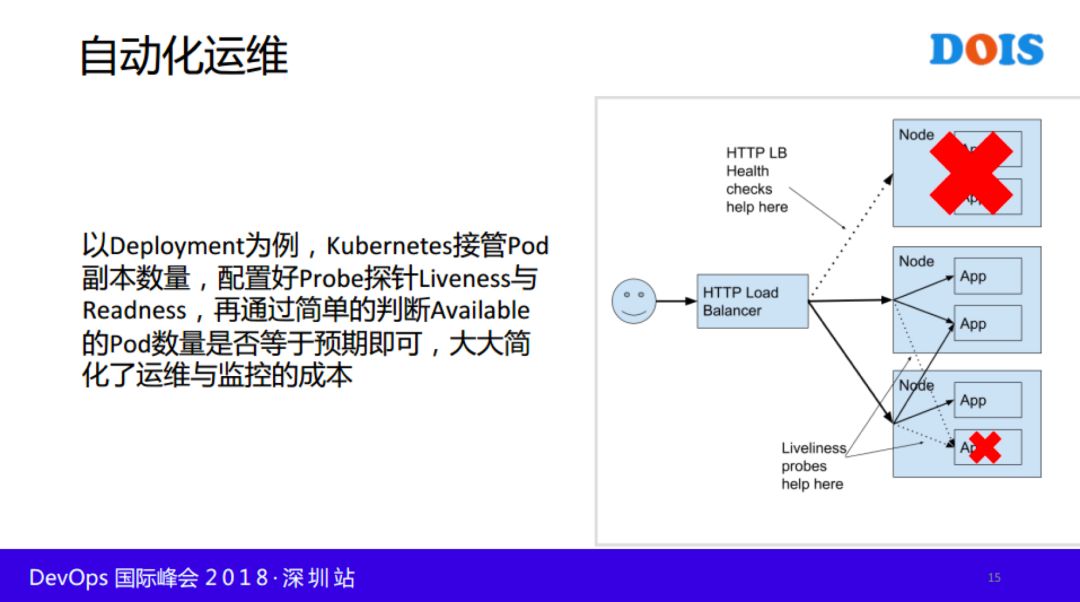
自动化运维只是简单举一个例子,K8S做了很多自动化的事情,我们可以利用起来,举一个例子,拿 Deployment 的例子讲,我们看一个服务正不正常,可以通过监控,POD的数量,配制好 Probe 探针LIVENESS与READNESS 再通过简单的判断 AVAILABLE 的 POD 数量是否等于预期的即可,大大简化了运维与监控的成本。
2. 利用Gitlab CI/CD构建CI/CD

其实目标很简单,希望能够CI/CD希望把公司的一些工具,比如说需要大中台,把工具能够串联起来,从提交代码开始,到最后发布能够串联起来,CI/CD干了这些事情。
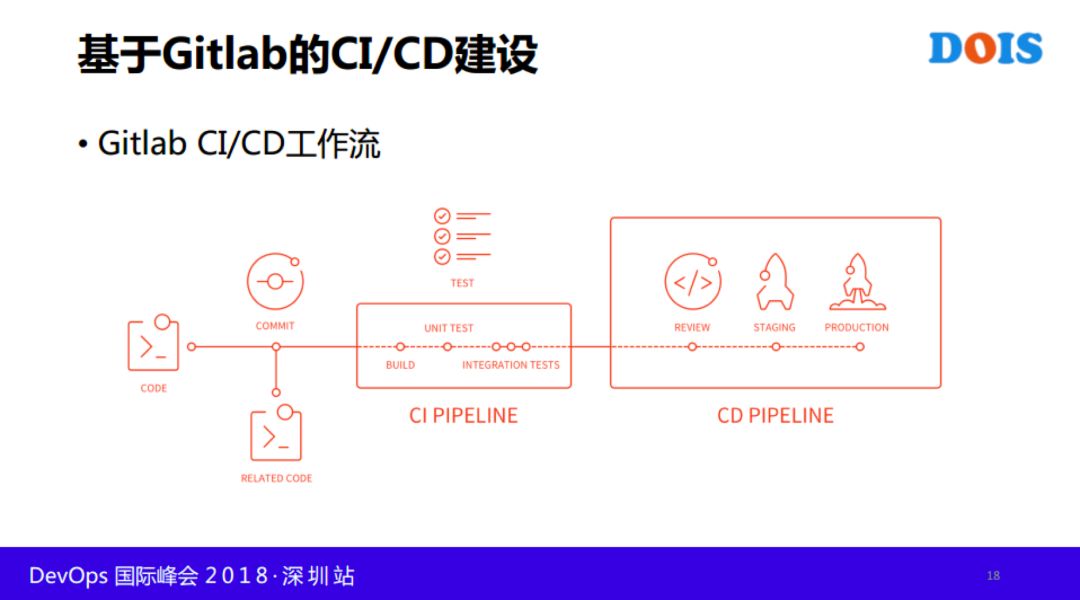
接下来讲一下CI/CD过程,这个是开发提交代码,提交代码之后是非常粗略的,后面可以详细的,代码比如说做编译,打包,走各种测试,组建测试完了之后,预发布环节有流量的话,希望这个服务上线之前有审批,最后去发布,包括上生产环境。
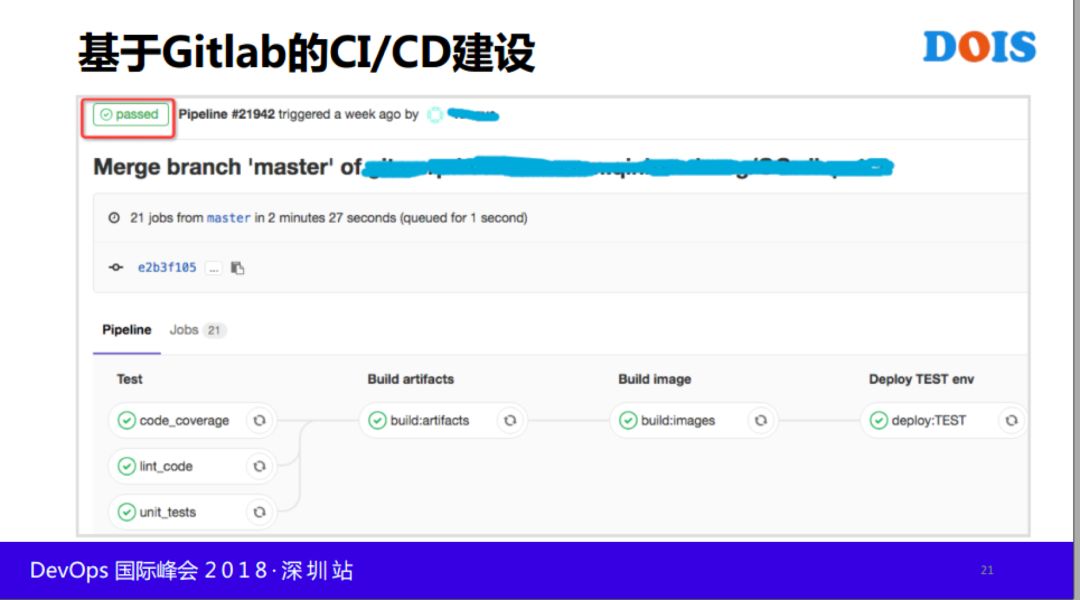
Gitalab CI/CD用起来非常简单和方便,不是很熟悉的人两三天就可以学的,提供很多的模板,现在这个公司大面积推CI,我们的业务很多,包括扩张非常厉害,几千人的规模,新业务老业务非常杂,把这些所有都谈了一遍,他们不需要做什么,提交代码就可以了,剩下的事情由我们来做。
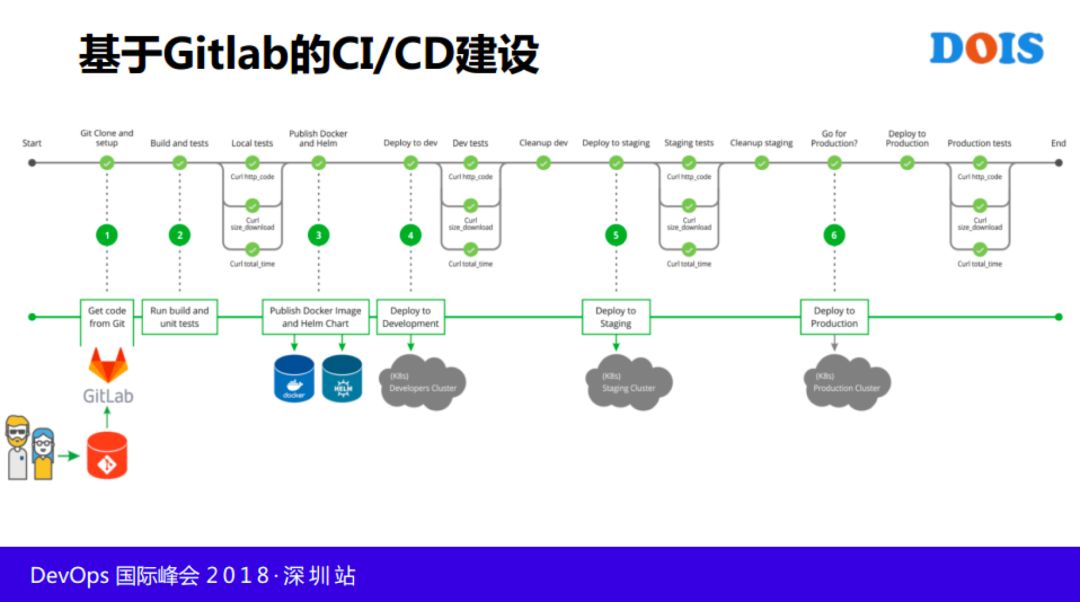

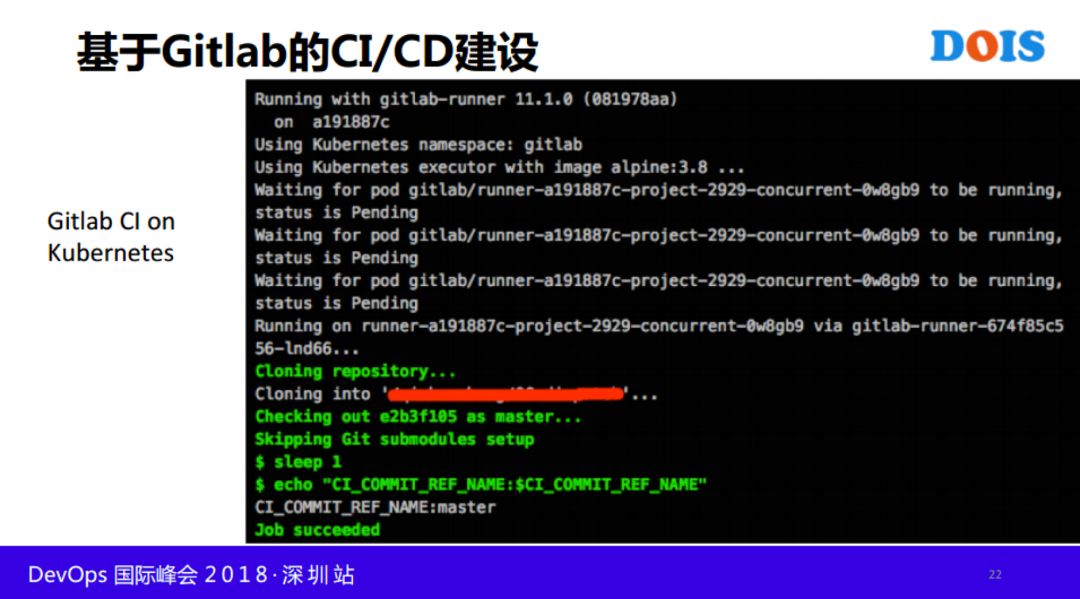
下面这个流程相对完整一点,但是不够完整,差得比较多,我们可以看一下,开发从提交代码之后,跑一些单元测试,代码风格检查,代码覆盖率,每个公司要求不一样,对代码的质量,有的公司要求代码覆盖率低于80%,有的90%,过了之后才可以往下走。
前面单元测试这些代码覆盖率,代码扫描过了之后,可以看看下面再往下走的时候,我们开始关心镜像,其实前面还有编译打包,跟别的方式做的不一样,包是不存的,Istio管代码,代码不会丢。因为编译环境不丢,代码环境不丢,我可以随时随地弄一个包出来,存在镜像里面,有镜像的名称,如果一旦线上有问题的时候,从后向前能够推导我们代码和版本做结合。
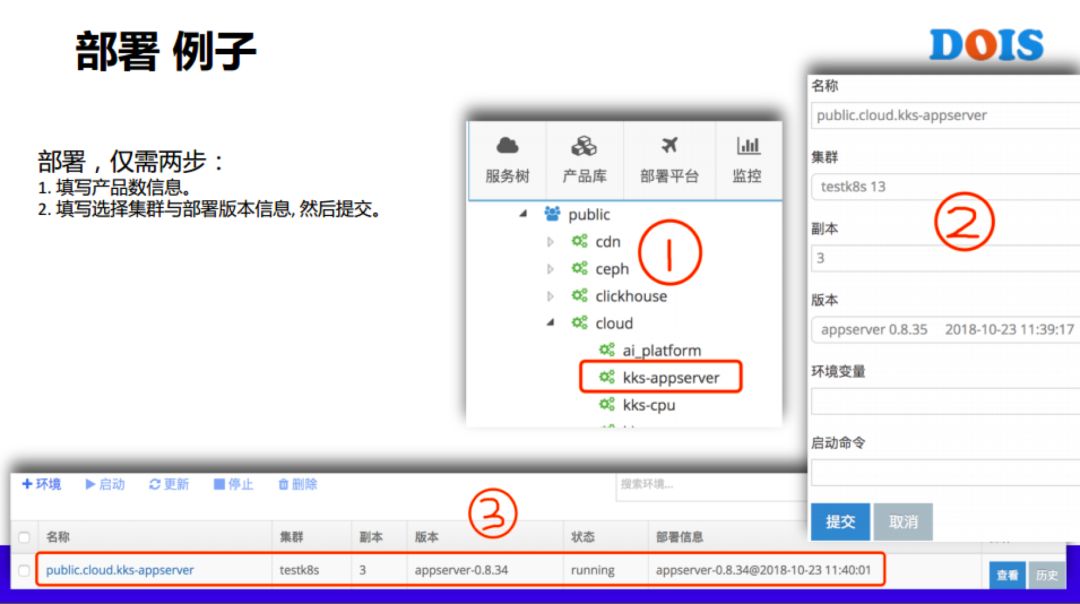
这个是我们一个例子,做到一键式发布,开发提交代码,把镜像的名称,Gitlab 都打到了刚才上面提的HELM包里面去,这里面都有关联,包括后面的经费,每一个业务线的经费,包括产品的后关联,我们从上面可以看到,我们想集群。
第二图我们有多少数,版本里面选的那个其实就是我们用CI阶段自动构建起来的HELM包出来的,这个包并不是一个真正的含镜像的包,只是含镜像的Gitlab,还是在镜像中心里面,包括如果说我们做环境变量的替换到原来的配置的话,也是可以做的,这些都达到我们HELM包里面的。
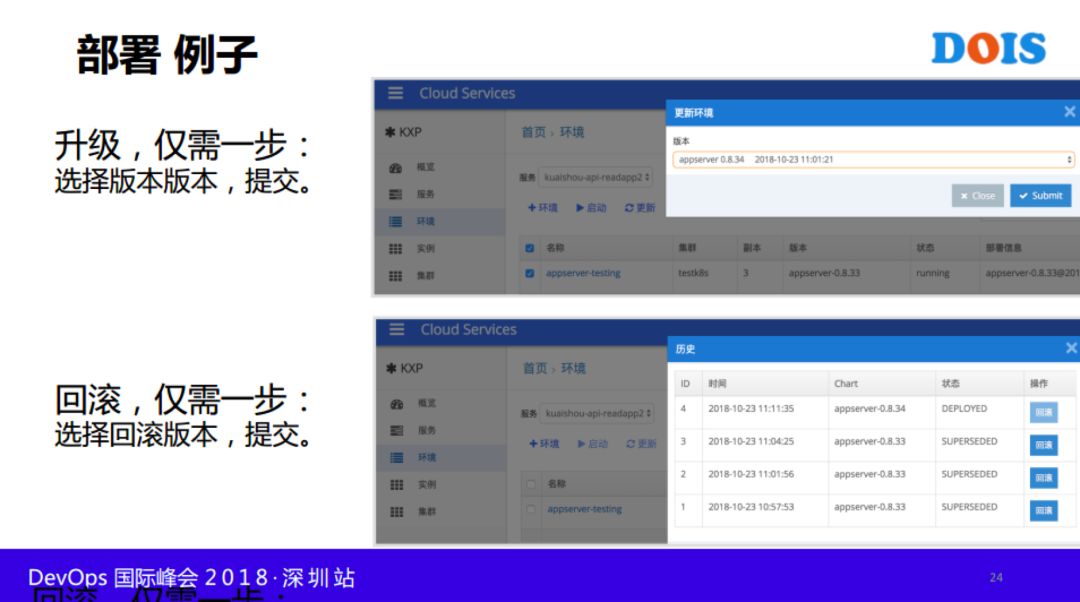
3. 基于Helm应用发布/配置管理
部署需要选一点东西,需要选择测试集群或者是预发布集群,但是升级和回本更简单的,我们选了一次,比如说现在想做升级,那我们直接点击升级,选择对应的包的回本,都是CI/CD打出来的,回滚其实也是类型,因为采用HELM做的,有一个历史的的信息。
这里面有一个小的问题,就是说,我们其实用HELM大家都知道,实际上我们没有HELM的顾虑,前面也提到的IDC环境并不是特别稳定,所以说就是不建议集群跨机房,一个集群只能在一个机房,基于这个结论之后,我们在比如说一个服务可能是说,这个服务高可用,可能只部署了一个机房,需要布多个机房,涉及多个集群,这种情况之后,无论是部署从升级回滚考虑一致性的问题。

第一个机房不成功的,第二个失败的,我们强制多回滚的状态。为什么呢?我们回滚第一个成功,第二个没有成功,第二个是没有rollback信息的,第三个有,然后把我简单说一下,他们做什么管理,做了一个开源HELM,我们用按照序列号激增的一个办法,把K8S部署得一堆文件包起来的,部署在一个地方。
大家可以看到,这个是具体服务,是我们上线的具体服务,发布了很多次,因为是新服务,做得不太好,所以总上线,总改,能有一个历史完整信息,可以看到发布这么多次,如果用HELM来看的话,有什么不一致,都可以看得到的。环境变量不一致,不需要自己关心的我们引用这一套方案之后呢,节约了成本,更简单了,不用考虑太多的事情,只关心自己的代码就可以了,既然服务网格的话,一定涉及到服务通信,所以Service mesh。
4. 使用serviceMesh做服务治理
下面简单介绍了Service Mesh是什么,以及我们为什么会选择Istio。


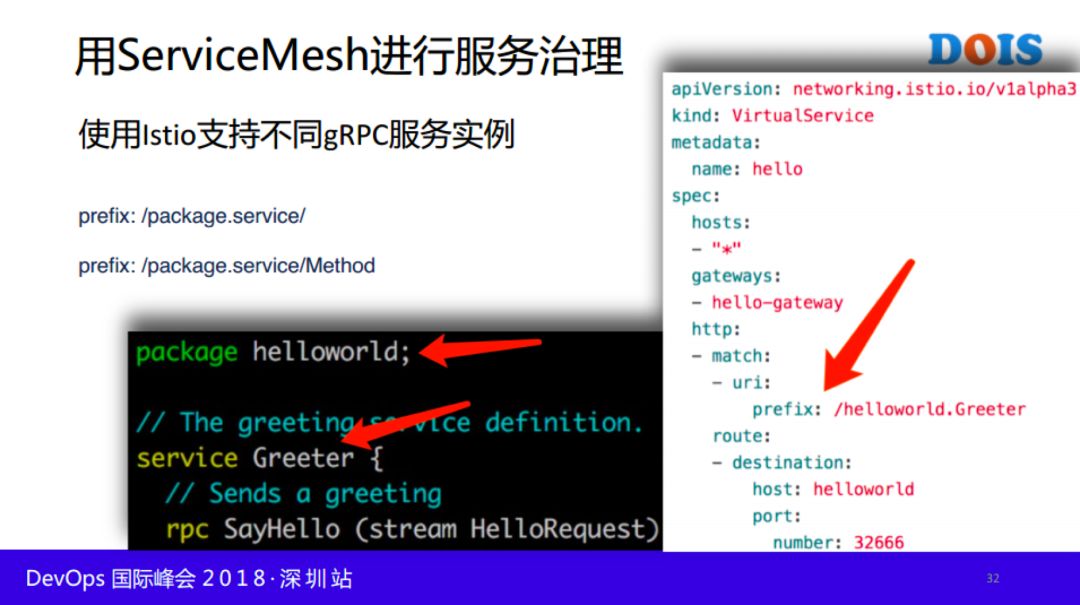
我们可以了解一下,首先我们现在用的功能最常见的功能是什么?公司用gRPC这个功能,是我们最常用的,后面有一些实践基于gRPC做的。

下面罗列了Istio如何支持多个不同的gRPC服务访问,方式非常多,参见如下:
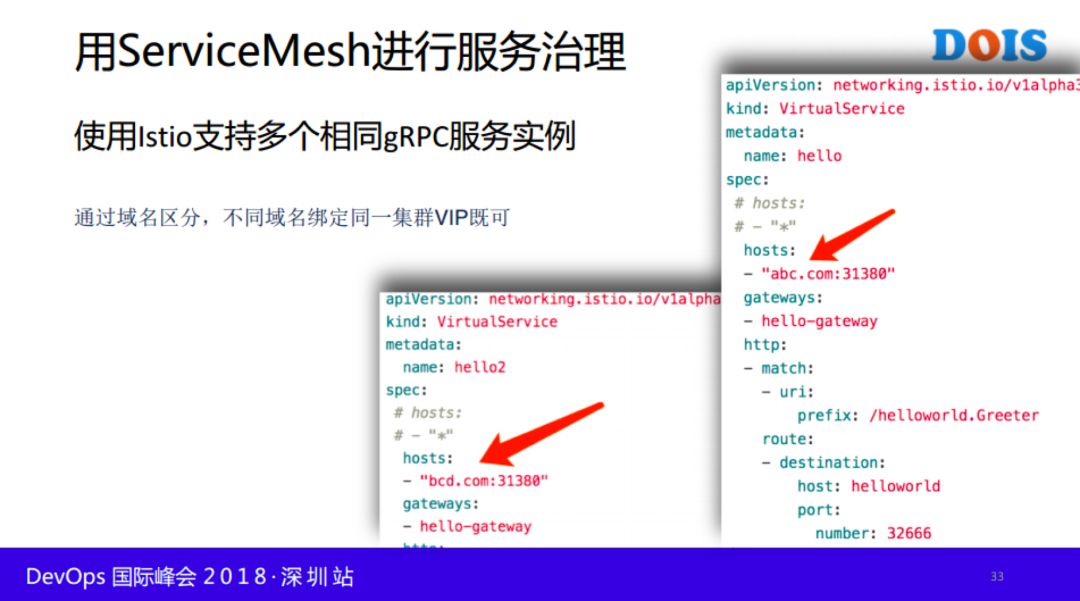
服务容器化或网格化,不是一蹴而就,所以在相当长的一段时间内,需要考虑物理机服务、容器化服务以及网格内部服务相互服务发现场景。下来罗列了个场景下服务发现方式:
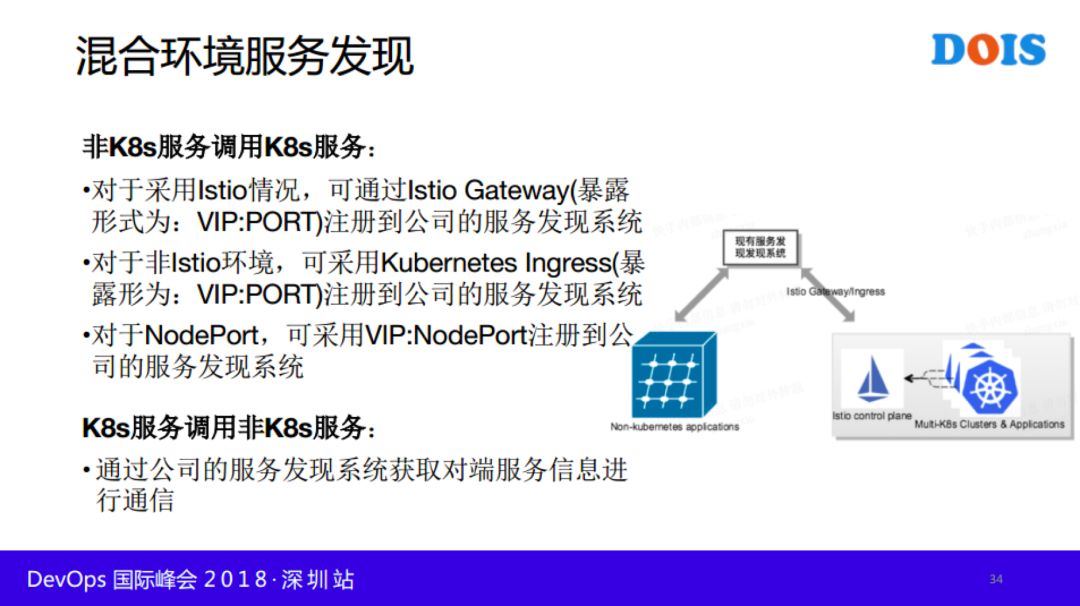
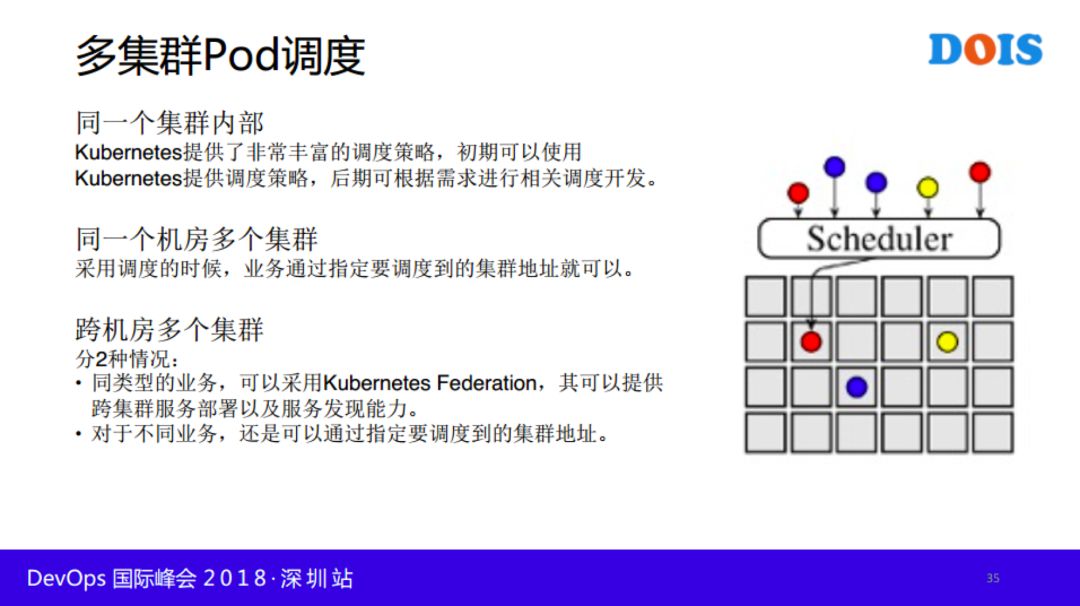
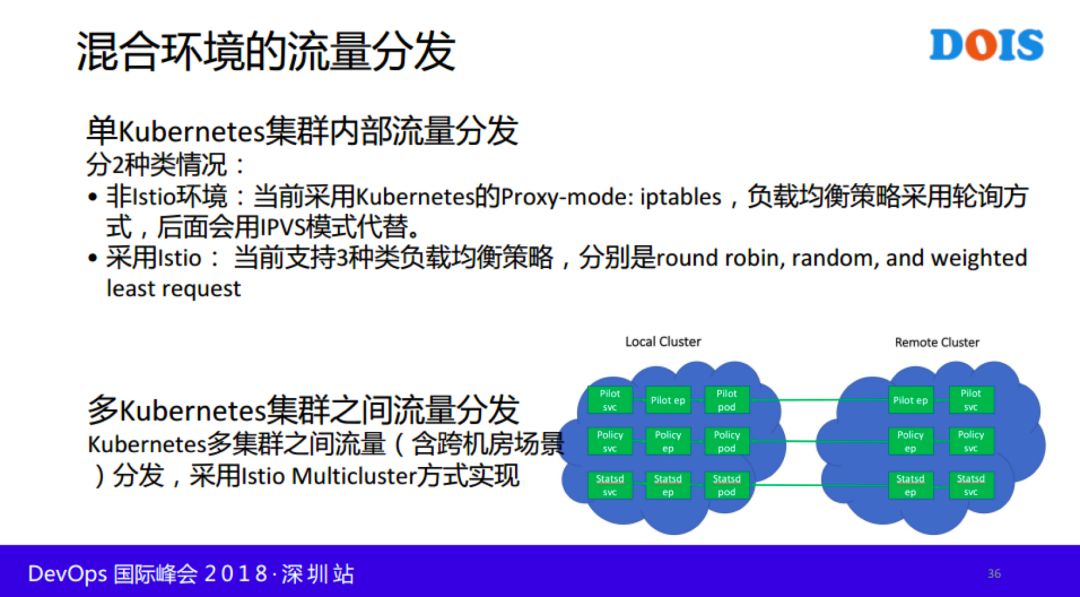
混合环境的流量分发相对来说比较复杂的,同样分为多种情况:Istio环境和非Istio场景。具体分发策略在PPT中有说明。由于时间关系,今天就讲这么多,谢谢大家。
以上为快手资深技术专家张夏在 DevOps 国际峰会 2018 · 深圳站的分享。
想了解更多企业级容器云落地实践分享?DevOps 国际峰会 2019 · 北京站,快手资深技术专家张夏将带来更多快手基于服务网格平台化的分享,敬请期待~

还有更多精益/敏捷、持续交付/自动化测试、技术运营、高可用架构与微服务技术专场
就在7月5日~6日
DevOps 国际峰会 2019 · 北京站
点击阅读原文,了解更多精彩
以上是关于快手基于 Kubernetes 与 Istio 的容器云落地实践的主要内容,如果未能解决你的问题,请参考以下文章
Istio实战-Istio 与 Kubernetes 行业主流?
基于Go/Grpc/kubernetes/Istio开发微服务的最佳实践尝试