详解HDFS读写流程
Posted akari的数据人生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解HDFS读写流程相关的知识,希望对你有一定的参考价值。
关于HDFS的 block、packet与chunk详解
block、packet与chunk
在DFSClient写HDFS的过程中,有三个需要搞清楚的单位:block、packet与chunk;
block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由dfs.block.size参数决定,默认是128M;注:这个参数由客户端配置决定;
packet是中等的一个单位,它是数据由DFSClient流向DataNode的粒度,以dfs.write.packet.size参数为参考值,默认是64K;注:这个参数为参考值,是指真正在进行数据传输时,会以它为基准进行调整,调整的原因是一个packet有特定的结构,调整的目标是这个packet的大小刚好包含结构中的所有成员,同时也保证写到DataNode后当前block的大小不超过设定值;
chunk是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;
注:事实上一个chunk还包含4B的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应;
HDFS写数据流程
我自己的一张图
1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
官方图解及API解释:
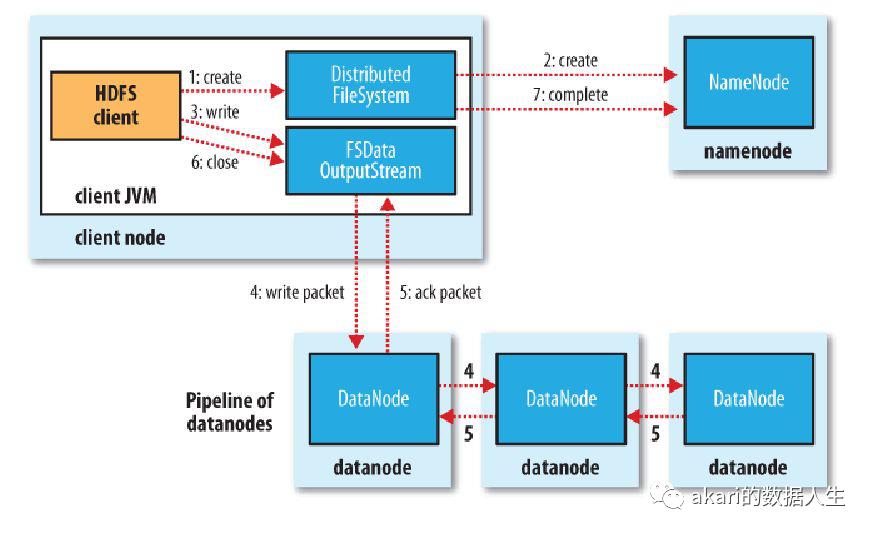
1. 客户端通过调用DistributedFileSystem的create方法创建新文件。
2. DistributedFileSystem通过RPC调用namenode去创建一个没有blocks关联的新文件,创建前, namenode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过, namenode就会记录下新文件,否则就会抛出IO异常。
3. 前两步结束后,会返回FSDataOutputStream的对象,与读文件的时候相似, FSDataOutputStream被封装成DFSOutputStream。DFSOutputStream可以协调namenode和 datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小的packet,然后排成队 列data quene(数据队列)。
4. DataStreamer会去处理接受data quene,它先询问namenode这个新的block最适合存储的在哪几个datanode里(比如重复数是3,那么就找到3个最适合的 datanode),把他们排成一个pipeline。DataStreamer把packet按队列输出到管道的第一个datanode中,第一个 datanode又把packet输出到第二个datanode中,以此类推。
5. DFSOutputStream还有一个对列叫ack quene,也是由packet组成,等待datanode的收到响应,当pipeline(管道)中的所有datanode都表示已经收到的时候,这时ack quene(确认队列)才会把对应的packet包移除掉。
l 如果在写的过程中某个datanode发生错误,会采取以下几步:
1) pipeline被关闭掉;
2) 为了防止防止丢包ack quene里的packet会同步到data quene里;
3) 把产生错误的datanode上当前在写但未完成的block删掉;
4) block剩下的部分被写到剩下的两个正常的datanode中;
5) namenode找到另外的datanode去创建这个块的复制。当然,这些操作对客户端来说是无感知的。
6. 客户端完成写数据后调用close方法关闭写入流。
7. DataStreamer把剩余得包都刷到pipeline里,然后等待ack信息,收到最后一个ack后,通知datanode把文件标视为已完成。
l 注意:客户端执行write操作后,写完的block才是可见的(注:和下面的一致性所对应),正在写的block对客户端是不可见的,只有 调用sync方法,客户端才确保该文件的写操作已经全部完成,当客户端调用close方法时,会默认调用sync方法。是否需要手动调用取决你根据程序需 要在数据健壮性和吞吐率之间的权衡
写过程中的三层buffer(缓存)
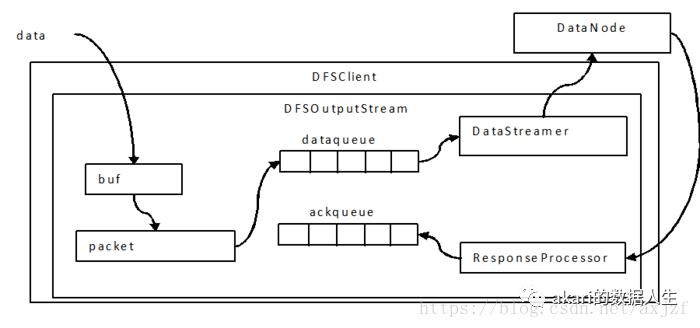
写过程中会以chunk、packet及packet queue三个粒度做三层缓存;
首先,当数据流入DFSOutputStream时,DFSOutputStream内会有一个chunk大小的buffer,当数据写满这个buffer(或遇到强制flush(一致性原则)),会计算checksum值,然后填塞进packet;
当一个chunk填塞进入packet后,仍然不会立即发送,而是累积到一个packet填满后,将这个packet放入dataqueue队列;
进入dataqueue队列的packet会被另一线程按序取出发送到datanode;
(注:生产者消费者模型,阻塞生产者的条件是dataqueue与ackqueue之和超过一个block的packet上限)
HDFS读数据流程
我自己的一张图:
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
官方图解与API解释:
1. 首先调用FileSystem对象的open方法,其实是一个DistributedFileSystem的实例。
2. DistributedFileSystem通过rpc获得文件的第一批block的locations,同一个block按照重复数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面。
3. 前两步会返回一个FSDataInputStream对象,该对象会被封装DFSInputStream对象,DFSInputStream可 以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode 并连接。
4. 数据从datanode源源不断的流向客户端。
5. 如果第一块的数据读完了,就会关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
6. 如果第一批block都读完了, DFSInputStream就会去namenode拿下一批block的locations,然后继续读,如果所有的块都读完,这时就会关闭掉所有的流。
7. 如果在读数据的时候, DFSInputStream和datanode的通讯发生异常,就会尝试正在读的block的排序第二近的datanode,并且会记录哪个 datanode发生错误,剩余的blocks读的时候就会直接跳过该datanode。 DFSInputStream也会检查block数据校验和,如果发现一个坏的block,就会先报告到namenode节点,然后 DFSInputStream在其他的datanode上读该block的镜像。
8. 该设计就是客户端直接连接datanode来检索数据并且namenode来负责为每一个block提供最优的datanode, namenode仅仅处理block location的请求,这些信息都加载在namenode的内存中,hdfs通过datanode集群可以承受大量客户端的并发访问。
如果对您有用请点个赞哦,您的赞就是对我最大的支持,谢谢 !
以上是关于详解HDFS读写流程的主要内容,如果未能解决你的问题,请参考以下文章