HDFS总结
Posted 请不要对我说ERROR
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS总结相关的知识,希望对你有一定的参考价值。
了解HDFS首先需要了解什么是dfs,dfs就是把文件分布的保存在计算机集群上,集群中基本上可分为两类节点,一类是master,一类是slave
1.HDFS的设计
HDFS是hadoop的分布式文件系统,他可以用来存储超大规模的数据,并运行于廉价的商业集群上,提供简单的文件模型,以及强大的跨平台性。
hdfs不适用于低延时的数据访问,无法高效的存储小文件,并不支持多用户写入和随机读写。
2.HDFS中的概念
2.1数据块
HDFS文件系统的存储抽象是数据块存储,
1)使用数据块抽象可以使文件的大小超越磁盘的大小,存储在集群的多个磁盘上
2)可以简化子系统的设计是文件元数据与数据分离存储
3)容易做数据备份
2.2 Namenode and DataNode
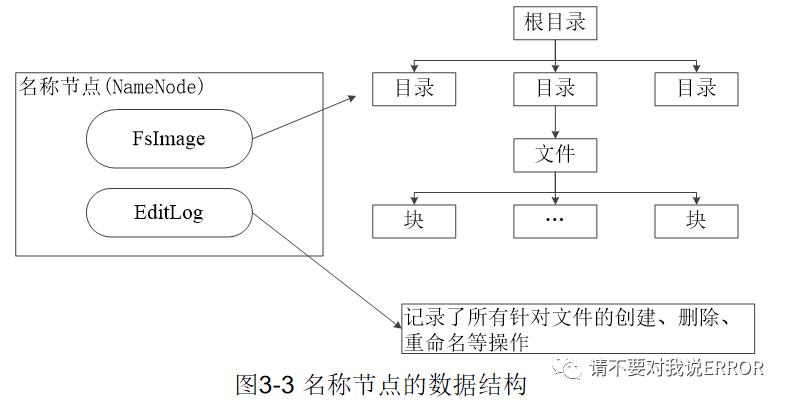
namenode节点负责保存dfs的的命名空间,包括FsImage与EditLog两个数据结构
FsImage 用于维护用来维护文件系统树中的所有文件及文件夹元数据
FsImage 不记录每个数据块存储的具体节点,而是又名称节点映射保存在内存,当数据节点加入hdfs,数据节点会把保存的数据块信息告诉名称节点。
EditLog记录文件的增删重命名等操作
名称节点的启动 :
加载FsImage到内存 -> 执行EditLog->合并fsimage,EditLog并建立新的
新的FsImage 和空白EditLog。
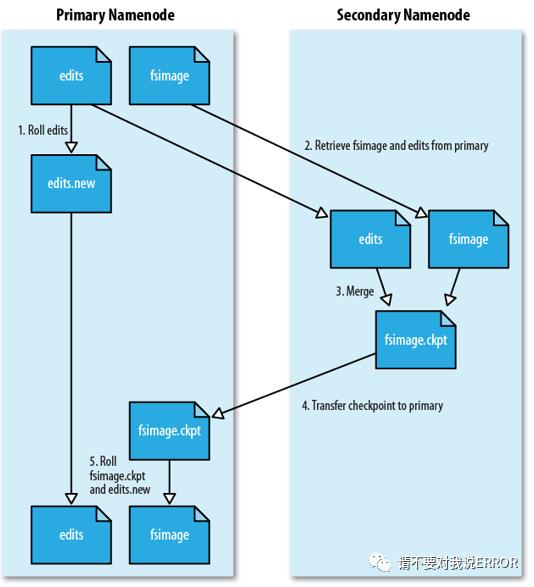
解决名称节点运行期间EditLog不断变大的问题:
一直写editlog同样会不断变大会使名称节点重新运行时速度降低,采用第二 名称节点解决
解决流程:
secondraynamenode定期与namenode通信使name停止写editlog,生成一个neweditlog -> secondraynamenode 获取 namenode上 fsimage和 editlog并进行合并 ->发送回namenode ->namenode用新的fsimage替换旧的并用newedit替换editlog。
dotanode:
根据客户端和namenode进行数据存取和检索
定期向namenode发送自己存储的块的列表
数据保存在自身os的文件系统中
3.hdfs体系结构
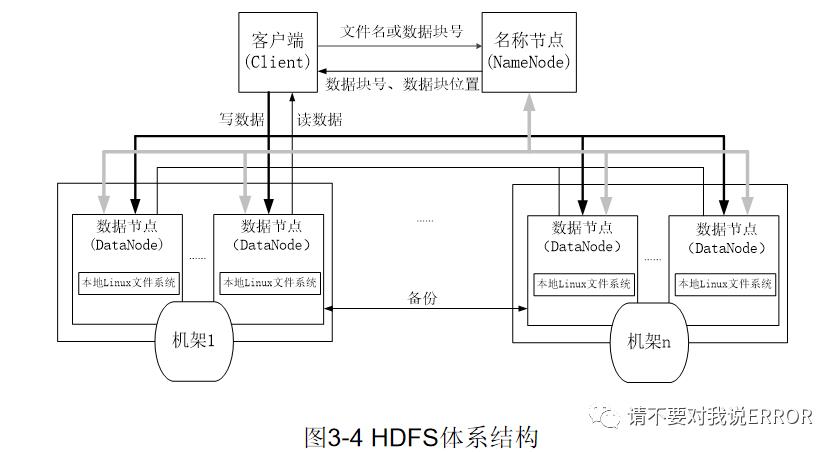
hdfs采用主从结构模型
namenode是中心服务器,负责管理文件系统命名空间及客户端对文件的访问
datanode一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作
3.1hdfs的命名空间管理
HDFS的命名空间包含目录、文件和块,采用传统的文件文集体系,可以像操作普通文件一样操作hdfs
3.2通信协议
client 和 namenode 采用 tcp/ip通信
namenode 和 datanode采用 数据节点访问协议通信
客户端和datanode采用rpc调用方式
3.3 client
hdfs client 是hdfs一个接口,隐藏hdfs的复杂性 实现对hdfs的简单操作
同时支持javaapi
1.0hdfs体系结构的局限性
(1)命名空间的限制:namenode内存大小决定文件系统大小。
(2)性能的瓶颈
吞吐量受限于单个名称节点的吞吐量:
(3)隔离问题
无法对不同应用程序就行隔离
123 后续的hdfs体系结构采用联邦 namenode解决
(4)集群的可用性
一个namenode出故障整个集群将不可用
后续采用 activate-standby
4HDFS存储原理
4.1 冗余存储
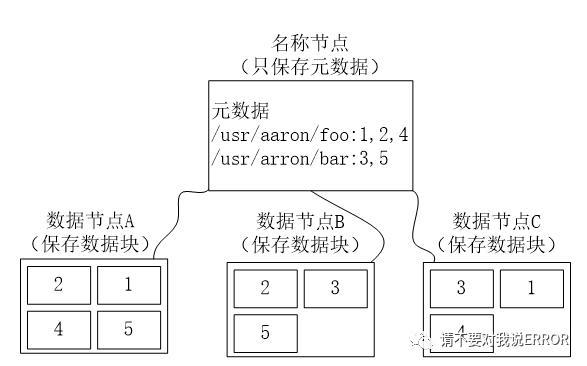
好处:
加快数据传输;容易检查错误;保障数据可靠
4.2数据存取策略
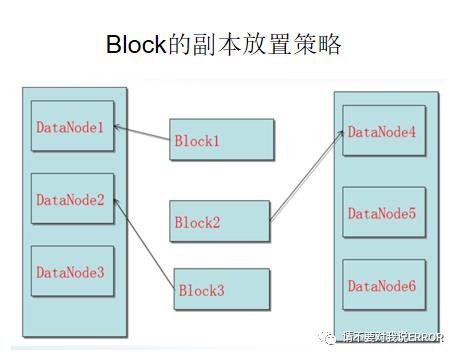
数据存放:
第一个副本存在上传文件的节点或者磁盘不满,cpu不忙的节点
第二个副本与第一个节点不同机架节点
第3个副本与第一节点相同机架的不同机器
数据读取:
client读取数据过程:
从namenode获取数据块副本列表 -> 调用api获取 client与数据节点机架id ->优先读取id相同的数据节点
4.3 数据错误与恢复
名称节点错误
secondraynamenode
数据节点出错
数据节点定期向名称节点发送心跳 -> namenode未收到心跳会把数据节点标记为宕机 ->当副本数小于冗余因子启动复制生成新的副本
数据出错
md5和sha1对数据进行校验
4.4数据读写过程
读:
写:
以上是关于HDFS总结的主要内容,如果未能解决你的问题,请参考以下文章