HDFS学习总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS学习总结相关的知识,希望对你有一定的参考价值。
最近在研究HDFS,主要是通过看<Hadoop: The Definitive Guide>一书的第四版,现在就书中的要点做下总结。
1、HDFS适合那些场景,不适合那些场景?
适合非常大的数据文件,流式数据访问和廉价的集群硬件;
不适合低延迟数据访问,许多小文件和多用户对同一文件的修改。
2、HDFS基本概念
Blocks:HDFS数据最小单元,默认大小为128MB,超过128MB的数据被存在多个Block中,可已存储在不同节点中,小于128MB的文件例如1MB存在1个block,占用空间为1MB。
Namenode:通常工作的只有1个,它通过本地文件系统中的namespace image和edit log 2个文件管理文件系统的命名空间,维护文件系统树和树里面的文件元数据和目录。因为Namenode宕机后,整个HDFS文件系统会不可用,
为了保持高可用性,通常在不同的物理机会有一个secondary namenode,会保留namespace image和edit log 2个文件的备份,一旦Namenode宕机,则secondary namenode会成为新的Namenode。
Datanodes:通常有多个,主要用于存储blocks。
Block Caching:一般Datanode从磁盘中读取blocks,但是对于经常使用的文件,其blocks会缓存到datanode的内存中。
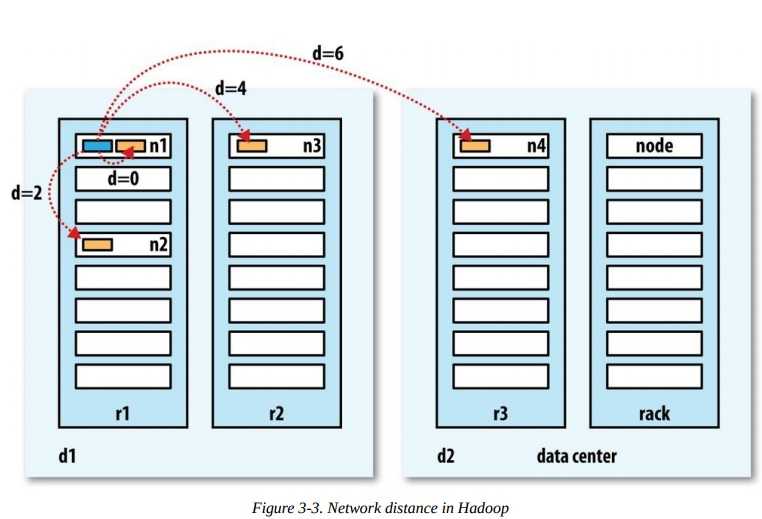
3、HDFS中网络距离计算规则
distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node)
distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack)
distance(/d1/r1/n1, /d1/r2/n3) = 4 (nodes on different racks in the same data center)
distance(/d1/r1/n1, /d2/r3/n4) = 6 (nodes in different data centers)
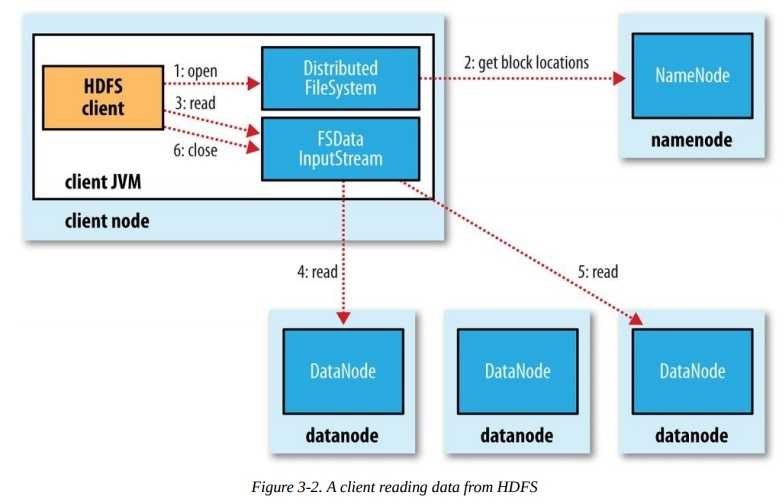
4、解剖HDFS文件读取和文件写入
读取:Client从namenode获取block信息,然后根据网络距离计算最优block位置按照顺序一个个先后读取block数据。
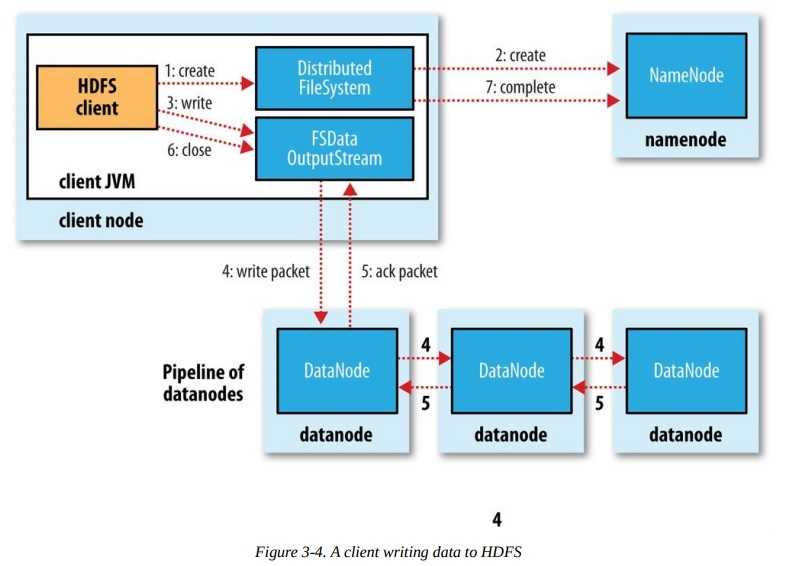
写入:Client从namenode获取创建的outputstream,然后负责写主block,主block负责写第一个备份block,第一个备份block负责写第二个备份block
第二个备份block写完毕后ACK到第一个备份block,第一个备份block然后ACK到主block,主block返回ACK给Client。
铸剑团队签名:
【总监】十二春秋之,[email protected];
【Master】戈稻不苍,[email protected];
【Java开发】雨鸶,[email protected];思齐骏惠,[email protected];小王子,[email protected];巡山小钻风,[email protected];
【VS开发】豆点,[email protected];
【系统测试】土镜问道,[email protected];尘子与自由,[email protected];
【大数据】沙漠绿洲,[email protected];张三省,[email protected];
【网络】夜孤星,[email protected];
【系统运营】三石头,[email protected];平凡怪咖,[email protected];
【容灾备份】秋天的雨,[email protected];
【安全】保密,你懂的。
原创作者:张三省
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
以上是关于HDFS学习总结的主要内容,如果未能解决你的问题,请参考以下文章