修改代码150万行!Apache Flink 1.9.0做了这些重大修改
Posted 大数据DT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了修改代码150万行!Apache Flink 1.9.0做了这些重大修改相关的知识,希望对你有一定的参考价值。
导读:8月22日,Apache Flink 1.9.0 正式发布。早在今年1月,阿里便宣布将内部过去几年打磨的大数据处理引擎Blink进行开源并向 Apache Flink 贡献代码。此次版本在结构上有重大变更,修改代码达150万行,接下来,我们一起梳理 Flink 1.9.0 中非常值得关注的重要功能与特性。

Flink 1.9.0是阿里内部版本 Blink 合并入 Flink 后的首次发版,修改代码150万行,此次发版不仅在结构上有重大变更,在功能特性上也更加强大与完善。本文将为大家介绍 Flink 1.9.0 有哪些重大变更与新增功能特性。
在此先简单回顾一下阿里巴巴Blink 开源的部分要点:
Blink 开源的内容主要是阿里巴巴基于开源 Flink 引擎,依托集团内部业务,在流计算和批处理上积累的大量新功能、性能优化、稳定性提升等核心代码。
Blink 以分支的形式开源,即开源后会成为 Apache Flink项目下的一个分支。
Blink 开源的目标不是希望成为另一个活跃的项目,而是将Flink 做的更好。通过开源的方式让大家了解所有 Blink 的实现细节,提高 Blink 功能merge进入Flink 的效率,与社区协作更高效。
半年的时间过去了,随着 Flink 1.9.0 版本的发布,在此我们可以骄傲的宣布:Blink 团队已经实现了之前的诺言!尽管不是所有功能都顺利 merge 回了社区,但是在我们和社区的共同努力下,Flink 正在朝着它最初的梦想大踏步的迈进。
先和大家分享几个 Flink 1.9.0 版本与之前个版本的对比数字:
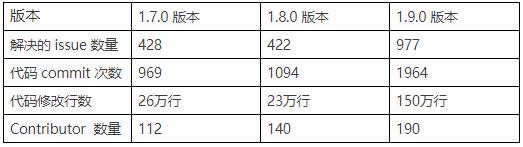
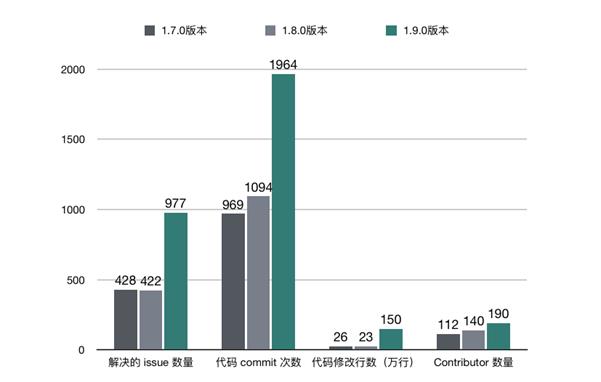
从解决的 issue 数量和代码 commit 数量来看,1.9.0 已经达到甚至超过了之前两个版本的总和。
从修改的代码行数来看,达到了惊人的150 万行。虽然受一些模块重构以及 Blink merge 等因素的影响,但不可否认的是,1.9.0 版本一定是 Flink 有史以来开发者们最活跃的版本。
从Contributor 数量来看,Flink 也已经吸引了越来越多的贡献者。我相信其中就有不少来自中国的用户和开发者,社区也响应号召开通了中文邮件列表。
那么,1.9.0 版本究竟由哪些变更而引发了如此大量的修改,以下将详细说明。
https://flink.apache.org/news/2019/08/22/release-1.9.0.html
01 架构升级
基本上,系统如果有非常大的变动,那一定是架构升级带来的。这次也不例外,Flink 在流批融合的方向上迈进了一大步。首先我们来看一下 Flink之前版本的架构图:
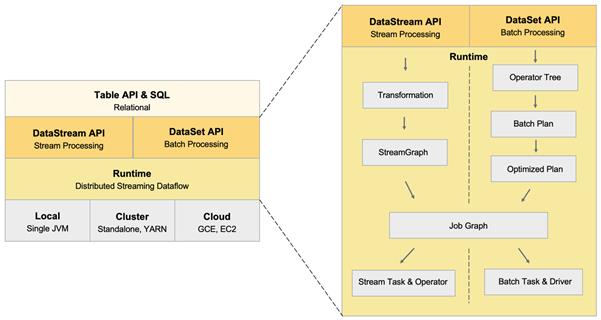
相信熟悉Flink 的读者们对左边的架构图一定不会感到陌生。简单来说,Flink 在其分布式流式执行引擎之上,有两套相对独立的 DataStream 和 DataSet API,分别来描述流计算和批处理的作业。在这两个 API之上,则提供了一个流批统一的API,即 Table API 和SQL。
用户可以使用相同的Table API 程序或者 SQL 来描述流批作业,只是在运行时需要告诉 Flink 引擎希望以流的形式运行还是以批的流式运行,此时 Table 层的优化器就会将程序优化成 DataStream 作业或者 DataSet 作业。
但是如果我们仔细查看 DataStream 和 DataSet 底层的实现细节,会发现这两个 API 共享的东西其实不多。它们有各自独立的翻译和优化的流程,而且在真正运行的时候,两者也使用了完全不同的 Task。这样的不一致对用户和开发者来讲可能存在问题。
从用户的角度来说,他们在编写作业的时候需要在两个 API 之间进行选择,而这两个 API 不仅语义不同,同时支持的 connector 种类也不同,难免会造成一些困扰。Table 尽管在 API 上已经进行了统一,但因为底层实现还是基于 DataStream 和 DataSet,也会受到刚才不一致的问题的影响。
从开发者角度来说,由于这两套流程相对独立,因此基本上很难做到代码的复用。我们在开发一些新功能的时候,往往需要将类似的功能开发两次,并且每种 API 的开发路径都比较长,基本都属于端到端的修改,这大大降低了我们的开发效率。如果两条独立的技术栈长期存在,不仅会造成人力的长期浪费,最终可能还会导致整个 Flink 的功能开发变慢。
在 Blink 一些先行探索的基础之上,我们和社区的开发人员进行了密切的讨论,最终基本敲定了 Flink 未来的技术架构路线。
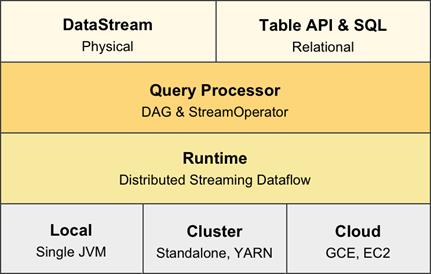
在 Flink 的未来版本中,我们将舍弃 DataSet API,用户的 API 主要会分为偏描述物理执行计划的 DataStream API 以及偏描述关系型计划的 Table & SQL。
DataStream API 提供给用户更多的是一种“所见即所得”的体验,由用户自行描述和编排算子的关系,引擎不会做过多的干涉和优化。而Table API & SQL 则继续保持现在的风格,提供关系表达式API,引擎会根据用户的意图来进行优化,并选择最优的执行计划。值得一提的是,以后这两个 API 都会各自同时提供流计算和批处理的功能。
这两个用户 API 之下,在实现层它们都会共享相同的技术栈,比如会用统一的 DAG 数据结构来描述作业,使用统一的 StreamOperator 来编写算子逻辑,包括使用统一的流式分布式执行引擎。
02 TableAPI & SQL
在开源 Blink 时,Blink 的Table 模块已经使用了 Flink 未来设想的新架构。因此 Flink 1.9 版本中,Table 模块顺理成章的成为了架构调整后第一个吃螃蟹的人。但是,为了尽量不影响之前版本用户的体验,我们还是需要找到一个方式让两种架构能够并存。
基于这个目的,社区的开发人员做了一系列的努力,包括将 Table 模块进行拆分(FLIP-32,FLIP 即 Flink Improvement Proposals,专门记录一些对Flink 做较大修改的提议),对 Java 和 Scala 的 API 进行依赖梳理,并且提出了 Planner 接口以支持多种不同的 Planner 实现。
Planner 将负责具体的优化和将 Table 作业翻译成执行图的工作,我们可以将原来的实现全部挪至 Flink Planner 中,然后把对接新架构的代码放在 Blink Planner里。
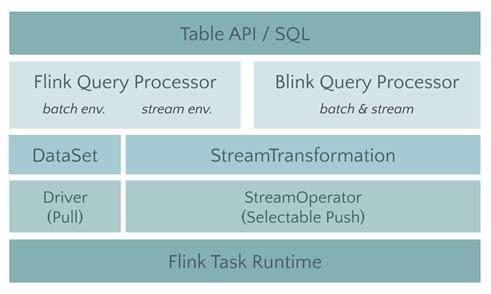
▲图中的 Query Processor 就是 Planner 的实现
这样的做法一举两得。不仅让 Table 模块在经过拆分后更加清晰,更重要的是不影响老版本用户的体验。
在 1.9 版本中,我们已经merge 了大部分当初从 Blink 开源出来的 SQL功能。这些都是近几年在阿里内部场景经过千锤百炼而沉淀出来的新功能和性能上的优化,相信能够促使Flink 更上一个台阶!
除了架构升级之外,Table 模块在 1.9 版本还做了几个相对比较大的重构和新功能,包括:
FLIP-37:重构 Table API 类型系统
FLIP-29:Table 增加面向多行多列操作的 API
FLINK-10232:初步的 SQL DDL 支持
FLIP-30:全新的统一的 Catalog API
FLIP-38:Table API 增加 Python 版本
有了这些新功能加持,再经过后续修复和完善,Flink Table API 和 SQL 在未来将会发挥越来越重要的作用。
03 批处理改进
Flink的批处理功能在 1.9 版本有了重大进步,在架构调整后,Flink 1.9 加入了好几项对批处理的功能改进。
首当其冲的是优化批处理的错误恢复代价:FLIP-1(Fine Grained Recovery from Task Failures),从这个 FLIP 的编号就可以看出,该优化其实很早就已经提出,1.9 版本终于有机会将 FLIP-1 中未完成的功能进行了收尾。
在新版本中,如果批处理作业有错误发生,那么 Flink 首先会去计算这个错误的影响范围,即 Failover Region。因为在批处理作业中,有些节点之间可以通过网络进行Pipeline 的数据传输,但其他一些节点可以通过 Blocking 的方式先把输出数据存下来,然后下游再去读取存储的数据的方式进行数据传输。
如果算子输出的数据已经完整的进行了保存,那么就没有必要把这个算子拉起重跑,这样一来就可以把错误恢复控制在一个相对较小的范围里。
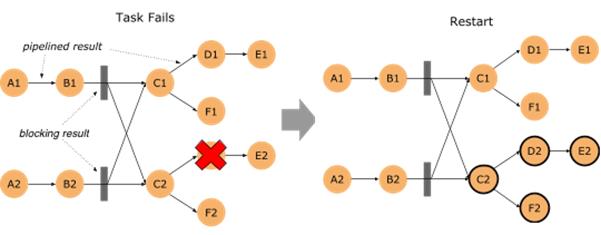
如果作业极端一点,在每一个需要Shuffle 的地方都进行数据落盘,那么就和 MapReduce 以及 Spark 的行为类似了。只是 Flink 支持更高级的用法,你可以自行控制每种 Shuffle 是使用网络来直连,还是通过文件落盘来进行。
有了基于文件的Shuffle 之后,大家很容易就会联想到,是不是可以把这个 Shuffle 的实现变成插件化。没错,社区也正在朝这个方向进行改进:FLIP-31(Pluggable Shuffle Service)。
比如,我们可以利用 Yarn 的 Auxliary Service 来作为一种 Shuffle 的实现,我们甚至可以去写一个分布式服务来帮助批处理任务进行Shuffle。
最近,Facebook 也分享了一些这方面的工作,而且在阿里内部,我们已经使用这样的架构,支持了单作业处理数百TB 量级的规模。Flink 具备了这样的插件机制后,可以轻松的对接这些更加高效灵活的实现,让Shuffle 这个批处理的老大难问题得到较好的解决。
04 流处理改进
流计算毕竟还是 Flink 发迹的主要领域,在 1.9 版本当然也不能忘了在这方面做一些改进。这个版本增加了一个非常实用的功能,即FLIP-43(State Processor API)。Flink 的 State 数据的访问,以及由 State 数据组成的 Savepoint 的访问一直是社区用户呼声比较高的一个功能。
在 1.9 之前的版本,Flink 开发了 Queryable State,不过这个功能的使用场景比较有限,使用效果也不太理想,因此用的人一直不多。这次的 State Processor API 则提供了更加灵活的访问手段,也能够让用户完成一些比较黑科技的功能:
用户可以使用这个 API 事先从其他外部系统读取数据,把它们转存为 Flink Savepoint 的格式,然后让 Flink 作业从这个 Savepoint 启动。这样一来,就能避免很多冷启动的问题。
使用 Flink 的批处理 API 直接分析State 的数据。State 数据一直以来对用户是个黑盒,这里面存储的数据是对是错,是否有异常,用户都无从而知。有了这个 API 之后,用户就可以像分析其他数据一样,来对 State 数据进行分析。
脏数据订正。假如有一条脏数据污染了你的 State,用户还可以使用这个 API 对这样的问题进行修复和订正。
状态迁移。当用户修改了作业逻辑,想复用大部分原来作业的 State,但又希望做一些微调。那么就可以使用这个 API 来完成相应的工作。
上面列举的都是流计算领域非常常见的需求和问题,都有机会通过这个灵活的 API 进行解决,因此我个人非常看好这个 API 的应用前景。
说到 Savepoint,这里也提一下社区完成的另外一个实用功能,即FLIP-34(Stop with Savepoint)。大家都知道 Flink 会周期性的进行 Checkpoint,并且维护了一个全局的状态快照。假如我们碰到这种场景:用户在两个Checkpoint 周期中间主动暂停了作业,然后过一会又进行重启。
这样,Flink 会自动读取上一次成功保存的全局状态快照,并开始计算上一次全局快照之后的数据。虽然这么做能保证状态数据的不多不少,但是输出到 Sink 的却已经有重复数据了。
有了这个功能之后,Flink 会在暂停作业的同时做一次全局快照,并存储到Savepoint。下次启动时,会从这个 Savepoint 启动作业,这样 Sink 就不会收到预期外的重复数据了。不过,这个做法并不能解决作业在运行过程中自动Failover而引起的输出到 Sink 数据重复问题。
05 Hive集成
Hive一直是 Hadoop 生态中一股不可忽视的重要力量。为了更好的推广 Flink 的批处理功能,和 Hive 的集成必不可少。在 1.9 版本的开发过程中,我们也很开心迎来了两位 Apache Hive PMC 来推进 Flink 和 Hive 的集成工作。
首先要解决的是使用 Flink 读取 Hive 数据的问题。通过 FLIP-30 提出的统一的 Catalog API 的帮助,目前 Flink 已经完整打通了对 Hive Meta Store 的访问。
同时,我们也增加了 Hive 的 Connector,目前已支持 CSV, Sequence File, Orc, Parquet 等格式。用户只需要配置 HMS 的访问方式,就可以使用 Flink 直接读取 Hive 的表进行操作。在此基础之上,Flink 还增加了对 Hive 自定义函数的兼容,像 UDF, UDTF和 UDAF,都可以直接运行在Flink SQL里。
在写的支持上,目前Flink 还支持的比较简单,暂时只能 INSERT INTO 一张新表。不过和 Hive 的兼容一直是社区工作中一个高优先级的事情,相信后续的版本会有持续的改善。
06 总结
Flink1.9.0 版本经过大半年的紧张开发,终于顺利发布。在这过程中,Flink 社区不仅迎来了相当多的中国开发者和用户,还迎来了海量的代码贡献,预示着一个良好的开端。

以上是关于修改代码150万行!Apache Flink 1.9.0做了这些重大修改的主要内容,如果未能解决你的问题,请参考以下文章
Flink 官宣 | Apache Flink 1.12.0 正式发布,流批一体真正统一运行!
官宣 | 千呼万唤,Apache Flink 1.11.0 正式发布啦!(内含福利)
flink运行报错 org.apache.flink.client.program.ProgramInvocationException: Could not retrieve the executi
mysql如何分批导出超150万行数据表,因为CSV文件用excel打开最多容纳104万行?
Apache Flink写入Clickhouse报错 code: 1002, ip:8123 failed to respond
Apache Flink写入Clickhouse报错 code: 1002, ip:8123 failed to respond