官宣 | 千呼万唤,Apache Flink 1.11.0 正式发布啦!(内含福利) Posted 2021-04-13 Flink 中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了官宣 | 千呼万唤,Apache Flink 1.11.0 正式发布啦!(内含福利)相关的知识,希望对你有一定的参考价值。
Apache Flink 社区很荣幸的宣布 Flink 1.11.0 版本正式发布!超过 200 名贡献者参与了 Flink 1.11.0 的开发,提交了超过 1300 个修复或优化。这些修改极大的提高了 Flink 的可用性,并且增强了各个 API 栈的功能。其中一些比较重要的修改包括:
核心引擎部分引入了非对齐的 Checkpoint 机制。这一机制是对 Flink 容错机制的一个重要改进,它可以提高严重反压作业的 Checkpoint 速度。
实现了一套新的 Source 接口
。通过统一流和批作业 Source 的运行机制,提供常用的内部实现如事件时间处理,watermark 生成和空闲并发检测,这套新的 Source 接口可以极大的降低实现新的 Source 时的开发复杂度。
Flink SQL 引入了对 CDC
(Change Data Capture,变动数据捕获)的支持,它使 Flink 可以方便的通过像 Debezium 这类工具来翻译和消费数据库的变动日志。Table API 和 SQL 也扩展了文件系统连接器对更多用户场景和格式的支持,从而可以支持将流式数据从 Kafka 写入 Hive 等场景。
PyFlink 优化了多个部分的性能
,包括对向量化的用户自定义函数(Python UDF)的支持。这些改动使 Flink Python 接口可以与常用的 Python 库(如 Pandas 和 NumPy)进行互操作,从而使 Flink 更适合数据处理与机器学习的场景。
Flink 1.11.0 的二进制发布包和源代码可以在 Flink 官网的下载页面获得,对应的 PyFlink 发布包可以在 PyPI 网站下载。详情可以参阅发布说明,发布功能更新与更新后的文档。
我们希望您下载试用这一版本后,可以通过 Flink 邮件列表和 JIRA 网站和我们分享您的反馈意见。
https://flink.apache.org/downloads.html
非对齐的 Checkpoints(Beta 版本)
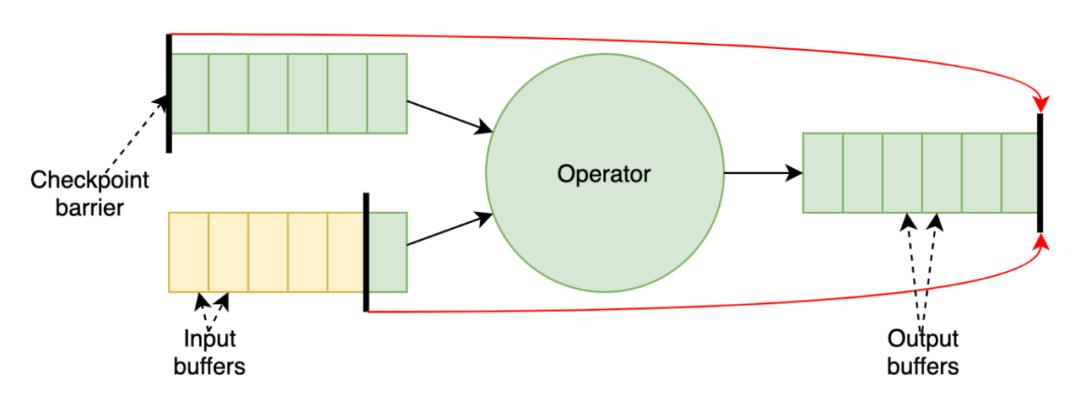
当 Flink 发起一次 Checkpoint 时, Checkpoint Barrier 会从整个拓扑的 Source 出发一直流动到 Sink。对于超过一个输入的算子,来自各个输入的 Barrier 首先需要 对齐,然后这个算子才能进行 state 的快照操作以及将 Barrier 发布给后续的算子。一般情况下对齐可以在几毫秒内完成,但是当反压时,对齐可能成为一个瓶颈:
Checkpoint Barrier 在有反压的输入通道中传播的速度非常慢(需要等待前面的数据处理完成),这将会阻塞对其它输入通道的数据处理并最终进一步反压上游的算子。
Checkpoint Barrier 传播慢还会导致 Checkpoint 时间过长甚至超时,在最坏的情况下,这可能导致整个作业进度无法更新。
为了提高 Checkpoint 在反压情况下的性能,Flink 社区在 1.11.0 版本中初步实现了非对齐的 Checkpoint 机制(FLIP-76)。与对齐的 Checkpoint(图1)相比,这种方式下算子不需要等待来自各个输入通道的 Barrier 对齐,相反,这种方式允许 Barrier 越过前面的待处理的数据(即在输出和输入 Buffer 中的数据)并且直接触发 Checkpoint 的同步阶段。这一过程如图2所示。
由于被越过的传播中的数据必须作为快照的一部分被持久化,非对齐的 Checkpoint 机制会增加 Checkpoint 的大小。但是,好的方面是它可以极大的减少 Checkpoint 需要的时间,因此即使在非稳定的环境中,用户也可以看到更多的作业进度。这是由于非对齐的 Checkpoint 可以减少 Recovery 的负载。关于非对齐的 Checkpoint 更详细的信息以及未来的开发计划,可以分别参考相关文档和 FLINK-14551。
和其它 Beta 版本的特性一样,我们非常期待和感谢您试用之后和社区分享您的感受。
注意:
开启这一特征需要通过 Chekpoint 选项配置 enableUnalignedCheckpoints 参数。需要注意的是,非对齐的 Checkpoint 只有在 CheckpointMode 被设置为 CheckpointMode.EXACTLY_ONCE 的时候才有效。
统一的 Watermark 生成器
目前 Flink 的 Watermark 生成(也叫做分配)依赖于两个接口:
AssignerWithPunctuatedWatermarks 与 AssignerWithPeriodicWatermarks,这两个接口与记录时间戳提取的关系也比较混乱,从而使 Flink 难以实现一些用户急需的功能,如支持空闲检测;此外,这还会导致代码重复且难以维护。
通过 FLIP-126, 现有的 watermark 生成接口被统一为一个单独的接口,即 WatermarkGenerator,并且它和 TimestampAssigner 独立。
这一修改使用户可以更好的控制 watermark 的发送逻辑,并且简化实现支持watermark 生成和时间戳提取的 Source 的难度(可以参考新的 Source 接口)。基于这一接口,Flink 1.11 中还提供了许多内置的 Watermark 生成策略(例如 forBoundedOutOfOrderness, forMonotonousTimestamps),并且用户可以使用自己的实现。
■ 支持 Watermark 空闲检测
WatermarkStrategy.withIdleness()方法允许用户在配置的时间内(即超时时间内)没有记录到达时将一个流标记为空闲,从而进一步支持 Flink 正确处理多个并发之间的事件时间倾斜的问题,并且避免了空闲的并发延迟整个系统的事件时间。通过将 Kafka 连接器迁移至新的接口(FLINK-17669),用户可以受益于针对单个并发的空闲检测。
注意:这一 FLIP 的修改目前不会影响现有程序,但是我们推荐用户后续尽量使用新的 Watermark 生成接口,避免后续版本禁用之前的 Watermark 生成器带来的影响。
新的 Source 接口(Beta)
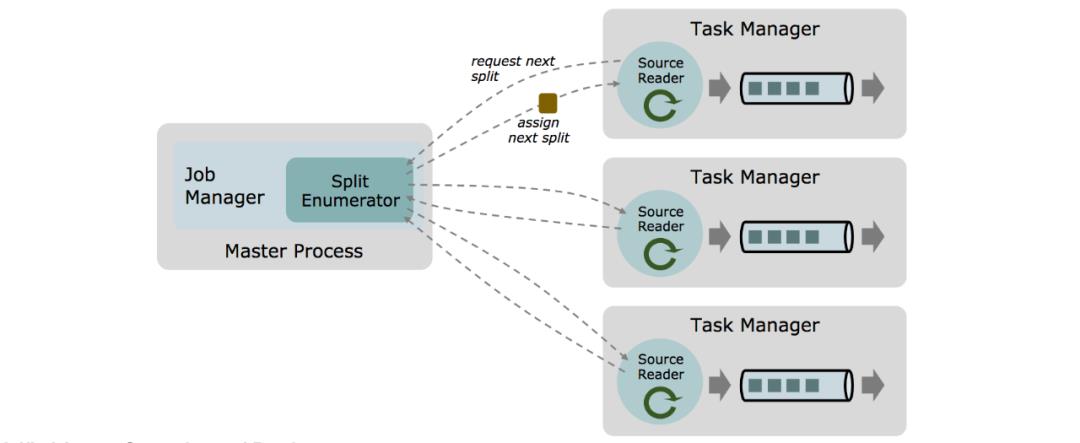
1.11 以编写一个生产可用的 Flink Source 连接器并不是一个简单的任务,它需要用户对 Flink 内部实现有一定的了解,并且需要在连接器中自行实现事件时间提取、Watermark 生成和空闲检测等功能。针对这一问题,Flink 1.11 引入了一套新的Source 接口 FLIP-27 来解决上述问题,并且同时解决了需要为批作业和流作业编写两套 Source 实现的问题。
通过将分区发现和实现消费每一个分区的数据分成不同的组件(即 SplitEnumerator 和 SourceReader),新的 Source 接口允许将不同的分区发现策略和分区消费的具体实现任意组合。
例如,现有的 Kafka 连接器提供了多种不同的分区发现策略,这些策略的实现和其实代码的实现耦合在一起。如果迁移到新的接口,Kafka Source 将可以使用相同的分区消费的实现(即 SourceReader),并且针对不同的分区发现策略编写单独的 SplitEnumerator 的实现。
■ 流批统一
使用新版 Source 接口的 Source 连接器将可以同时用于有限数据(批)作业和无限数据(流)作业。这两种场景仅有一个很小的区别:在有限数据的情况下,分区发现策略将返回一个固定大小的分区并且每一个分区的数据都是有限的;在无限数据的情况下,要么每个分区的数据量是无限的,要么分区发现策略可以不断的产生新的分区。
■ 内置的 Watermark 和事务时间处理
在新版 Source 接口中,TimestampAssigner 和 WatermarkGenerator 将透明的作为分区消费具体实现(SourceReader)的一部分,因此用户不需要实现任何时间戳提取和 Watermark 生成的代码。
注意:现有的 Source 连接器尚未基于新的 Source 接口重新实现,这将在后续版本中逐渐完成。如果想要基于新的 Source 接口实现自己的 Source,可以参考 Data Source 文档和 Source 开发的一些建议。
Application 部署模式
在1.11之前,Flink 的作业有两种部署模式,其中 Session 模式是将作业提交到一个长期运行的 Flink Session 集群,Job 模式是为每个作业启动一个专门的 Flink 作业集群。这两种模式下用户作业的 main 方法都是客户端执行的,但是这种方式存在一定的问题:如果客户端是更大程序的一部分的话,生成 JobGraph 容易成为系统的瓶颈;其次,这种方式也不能很好的适应像 Docker 和 K8s 这样的容器环境。
Flink 1.11 引入了一种新的部署模式,即 Application 模式(FLIP-85)。这种模式下用户程序的 main 方法将在集群中而不是客户端运行。这样,作业提交就会变得非常简单:用户将程序逻辑和依赖打包进一人可执行的 jar 包里,集群的入口程序(ApplicationClusterEntryPoint)负责调用其中的 main 方法来生成 JobGraph。
Flink 1.11 已经可以支持基于 K8s 的 Application 模式(FLINK-10934)。
其它功能修改
■ 统一 JM 的内存配置(FLIP-116)
在1.10中,Flink 统一了 TM 端的内存管理和配置,相应的在1.11中,Flink 进一步对JM 端的内存配置进行了修改,使它的选项和配置方式与 FLIP-49 中引入的 TM 端的配置方式保持一致。这一修改影响所有的部署类型,包括 standalone,Yarn,Mesos 和新引入的 K8s。
注意:复用之前的 Flink 配置将会得到不同的 JVM 参数,从而可能影响性能甚至导致异常。如果想要更新到 1.11 的话,请一定要参考迁移文档。
■ Web UI 功能增强
在1.11中,社区对 Flink Web UI 进行了一系列的优化。首要的修改是优化了 TM 和 JM 的日志展示(FLIP-103),其次,Flink Web UI 还引入了打印所有线程列表的工具(FLINK-14816)。在后续的版本中,Web UI 还将进一步优化,包括更好的反压检测,更灵活和可配置的异常展示以及对 Task 出错历史的展示。
■ 统一 Docker 镜像
1.11 将所有 Docker 相关的资源都统一整理到了 apache/flink-docker项目中,并且扩展了入口脚本从而允许用户在不同模式下使用默认的 docker 镜像,避免了许多情况下用户自己创建镜像的麻烦。关于如何在不同环境和部署模式下使用和定制 Flink 官方 Docker 镜像,请参考详细文档。
Table API/SQL:支持 CDC(Change Data Capture)
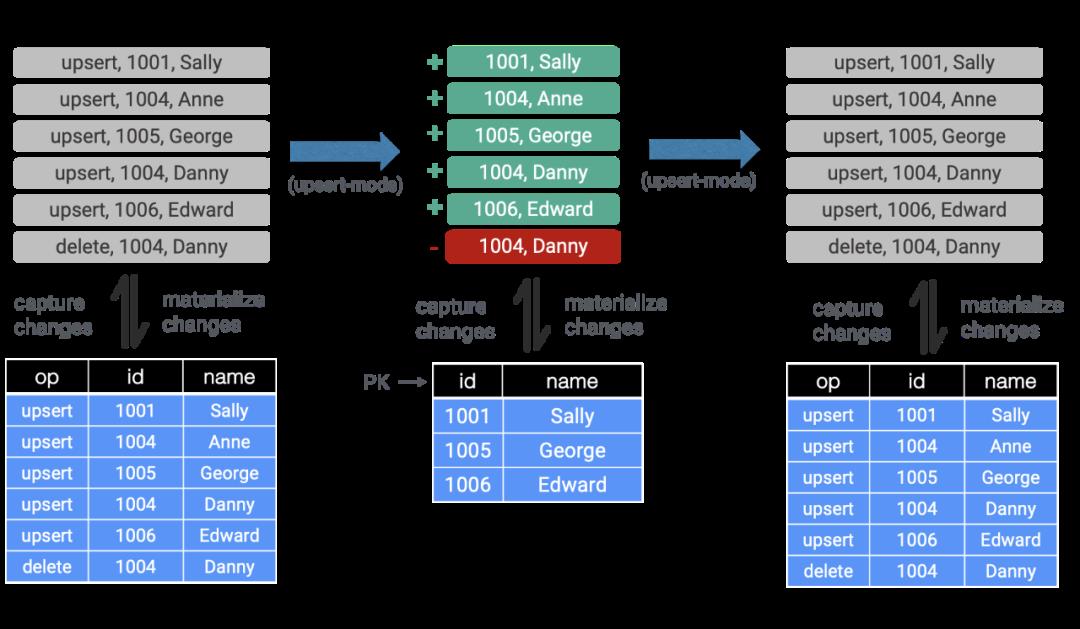
CDC 是数据库中一种常用的模式,它捕获数据库提交的修改并且将这些修改广播给其它的下游消费者。CDC 可以用于像同步多个数据存储和避免双写导致的问题等场景。长期以来 Flink 的用户都希望能够将 CDC 数据通过 Table API/SQL 导入到作业中,而 Flink 1.11 实现了这一点。
为了能够在 Table API / SQL 中使用 CDC,Flink 1.11 更新了 Table Source 与 Sink 的接口来支持 changelog 模式(参考新的 Table Source 与 Sink 接口)并且支持了 Debezium 与 Canal 格式(FLIP-105)。这一改动使动态 Table Source 不再只支持 append-only 的操作,而且可以导入外部的修改日志(插入事件)将它们翻译为对应的修改操作(插入,修改和删除)并将这些操作与操作的类型发送到后续的流中。
为了消费 CDC 数据,用户需要在使用 SQL DDL 创建表时指指定“format=debezium-json“或者“format=canal-json”:
CREATE TABLE my_table ( ... ) WITH ( 'connector'='...', -- e.g. 'kafka' 'format'='debezium-json', 'debezium-json.schema-include'='true' -- default: false (Debezium can be configured to include or exclude the message schema) 'debezium-json.ignore-parse-errors'='true' -- default: false );
Flink 1.11 仅支持 Kafka 作为修改日志的数据源以及 JSON 编码格式的修改日志;后续 Flink 将进一步支持 Avro(Debezium)和 Protobuf(Canal)格式。Flink 还计划在未来支持 UDF
mysql
注意:
目前有一个已知的 BUG(FLINK-18461)会导致使用修改日志的 Source 无法写入到 Upsert Sink 中(例如,MySQL,HBase,ElasticSearch)。这个问题会在下一个版本(即 1.11.1)中修复。
Table API/SQL:支持 JDBC Catalog 和 Postgres Catalog
Flink 1.11 支持了一种通用的 JDBC Catalog 接口(FLIP-93),这一接口允许 Table API/SQL 的用户自动的从通过 JDBC 连接的关系数据库中导出表结构。这一功能避免了之前用户需要手动复制表结构以及进行类型映射的麻烦,并且允许 Flink 在编译时而不是运行时对表结构进行检查。
首先在1.11中实现的是 Postgres Catalog。
Table API/SQL:支持 Avro,ORC 和 Parquet 格式的文件系统连接器
为了提高用户使用 Flink 进行端到端的流式 ETL 的体验,Flink 1.11 在 Table API/SQL 中引入了新的文件系统连接器。它基于 Flink 自己的文件系统抽象和 StreamingFileSink 来实现,从而保证和 DataStream API 有相同的能力和一致的行为。
这也意味着 Table API/SQL 的用户可以使用 StreamingFileSink 现在已经支持的文件格式,例如 (Avro) Parquet,以及在这1.11中新增加的文件格式,例如 Avro 和 ORC。
CREATE TABLE my_table ( column_name1 INT, column_name2 STRING, ... part_name1 INT, part_name2 STRING ) PARTITIONED BY (part_name1, part_name2) WITH ( 'connector' = 'filesystem', 'path' = 'file:///path/to/file, 'format' = '...', -- supported formats: Avro, ORC, Parquet, CSV, JSON ... );
新的全能的文件系统连接器可以透明的支持流作业和批作业,提供 Exactly-once 语义并且提供了完整的分区的支持,从而相对于之前的 Connector 极大的扩展了可以支持的场景。例如,用户可以容易的实现将流式数据从 Kafka 写入 Hive 的场景。
后续的文件系统连接器的优化可以参考 FLINK-17778。
Table API/SQL:支持 Python UDF
在1.11之前 Table API/SQL 的用户只能通过 Java 或 Scala 来实现 UDF。在1.11中,Flink 扩展了 Python 语言的应用范围,除了 PyFlink 外,Flink 1.11 还在 SQL DDL 语法(FLIP-106)和 SQL Client(FLIP-114)中支持了 Python UDF。用户还可以在系统 Catalog 中通过 SQL DDL 或者 Java Catalog API 来注册 Python UDF,这样这些 UDF 可以在作业中共享。
其它的 Table API/SQL 优化
■ Hive Connect 兼容 Hive DDL 和 DML(FLIP-123)
从1.11开始,用户可以在 Table API/SQL 和 SQL Client 中使用 Hive 语法(HiveQL)来编写 SQL 语句。为了支持这一特性,Flink 引入了一种新的 SQL 方言,用户可以动态的为每一条语句选择使用Flink(default)或Hive(hive)方法。对于所支持的 DDL 和 DML 的完整列表,请参考 Hive 方言的文档。
■ Flink SQL 语法的扩展和优化
Flink 1.11 引入了主键约束的概念,从而可以在 Flink SQL DDL 的运行时优化中使用(FLIP-87)。
视图对象已经在 SQL DDL 中完整支持,可以通过 CREATE/ALTER/DROP VIEW 等语句使用(FLIP-71)。
用户可以在 DQL 和 DML 中使用动态表属性动态指定或覆盖 Table 的选项(FLIP-113)。
为了简化 connector 参数的配置,提高异常处理的能力,Table API/SQL 修改了一些配置项的名称(FLIP-122)。这一改动不会破坏兼容性,用户仍然可以使用老的名称。
■ 新的 Table Source 和 Sink 接口(FLIP-95)
Flink 1.11 引入了新的 Table Source 和 Sink 接口(即 DynamicTableSource 和 DynamicTableSink),这一接口可以统一批作业和流作业,在使用 Blink Planner 时提供更高效的数据处理并且可以支持修改日志的处理(参考支持修改日志)。新的接口简化了用户实现新的自定义的连接器和修改现有连接器的复杂度。一个基于支持修改日志语义的数据解析格式来实现定制表扫描的Source的案例请参考这一文档。
注意:尽管这一修改不会破坏兼容性,但是我们推荐 Table API/SQL 的用户尽快将现有的Source和Sink升级到新的接口上。
■ 重构 Table Env 接口(FLIP-84)
1.11之前 TableEnvironment 和 Table 上相似的接口的行为并不完全相同,这导致了接口的不一致并使用户感到困惑。为了解决这一问题并使基于 Table API/SQL 的编写程序更加流畅,Flink 1.11 引入了新的方法来统一这些不一致的行为,例如执行触发的时机(即executeSql()),结果展示(即 print(),collecto())并且为后续版本的重要功能(如多语句执行)打下了基础。
注意:在 FLIP-84 中被标记为过期的方法不会被立刻删掉,但是我们建议用户采用新的方法。对于新的方法和过期方法的完整列表,可以查看 FLIP-84 的总结部分。
■ 新的类型推断和 Table API UDF(FLIP-65)
在 Flink 1.9 中,社区开始在 Table API 中支持一种新的类型系统来提高与标准 SQL 的一致性(FLIP-37)。在1.11中这一工作接近完成,通过支持在 Table API UDF 中使用新的类型系统(目前支持 scalar 函数与 table 函数,计划下一版本也支持 aggregate 函数)。
PyFlink:支持 Pandas UDF
在1.11之前,PyFlink 中的 Python UDF 仅支持标准的 Python 标量类型。这带来了一些限制:
在 JVM 和 Python 进程之间传递数据会导致较大序列化、反序列化开销。
难以集成常用的高性能 Python 数值计算框架,例如 Pandas 和 NumPy。
为了克服这些限制,社区引入了对基于 Pandas 的(标量)向量 Python UDF 的支持(FLIP-97)。由于可以通过利用 Apache Arrow 来最小化序列化/反序列化的开销,向量 UDF 的性能一般会非常好;此外,将 pandas.Series 作为输入输出的类型可以充分复用 Pandas 和 NumPy 库。这些特点使 Pandas UDF 特别适合并行机器学习和其它大规模、分布式的数据科学的计算作业(例如特征提取或分布式模式服务)。
@udf(input_types=[DataTypes.BIGINT(),DataTypes.BIGINT()],result_type=DataTypes.BIGINT(),udf_type="pandas") defadd(i,j): returni+j
为了使 UDF 变为 Pandas UDF,需要在 udf 的装饰器中添加额外的参数 udf_type=”pandas”,如文档所示。
PyFlink 的其它优化
■ 支持转换器 fromPandas/toPandas(FLIP-120)
Arrow 还被用来优化 PyFlink Table 和 pandas.DataFrame 之间的转换,从而使用户可以在不同的处理引擎之间无缝切换,而不需要编写特殊的连接器进行中转。使用 fromPandas()和toPandas() 方法的安例,可以参考相关文档。
■ 支持用户自定义的 Table Function(User-defined Table Function,UDTF)(FLINK-14500)
从1.11开始,用户可以在 PyFlink 定义和注册自定义的 UDTF。与 Python UDF 类似,UDTF 可以接受0个,一个或多个标量值作为参数,但是可以返回任意多行数据作为输出而不是只能返回单个值。
■ 基于 Cython 对 UDF 的性能进行优化(FLIP-121) Cython 是一个 Python 语言预编译的超集,它经常被用来提高大规模数据计算函数的性能,因为它可以将代码执行速度优化到机器指令级别,并且可以很好的与常用的基于 C 语言实现的库配合,例如 NumPy。从 Flink 1.11 开始,用户可以构造包括 Cython支持的 PyFlink[60]并且可以通过 Cython 来优化 Python UDF。这种优化可以极大的提升代码的性能(与 1.10 的 Python UDF 相比最高能有 30 倍的提升)。 ■ Python UDF 支持用户自定义的 Metrics(FLIP-112)
为了使用户可以更容易的监控和调试 Python UDF 的执行,PyFlink 现在支持收集和输出 Metric 的值到外部系统中,并且支持自定义域和变量。用户可以在 UDF 的 open 方法中通过调用 function_context.get_metric_group() 来访问一个 Metric 系统,如文档所示。
[FLINK-17339]
从1.11开始,Blink Planner 将变为 Table API/SQL 的默认 Planner。实际上,在1.10中 SQL Client 的默认 Planner 已经变为 Blink Planner。老的 Planner 仍然将会支持,但是后续不会再有大的变更。
[FLINK-5763]
Savepoints 将所有的状态写入到单个目录下(包括元数据和程序状态)。这使得用户可以容易的看出每个 Savepoint 的 State 包含哪些文件,并且允许用户直接通过移动目录来实现 Savepoint 的重定位。
[FLINK-16408]
为了减少 JVM 元数据空间的压力,Flink 1.11 中对于单个 TaskExecutor 只要上面还有某个作业的 Slot,该作业的 ClassLoader 就会被复用。这一改动会改变 Flink 错误恢复的行为,因为 static 字段不会被重新初始化。
[F
LINK-11086] Flink 现在可以支持 Hadoop 3.0.0 以上的版本。注意 Flink 项目并未提供任何更新的“flink-shaded-hadoop-*”的 jar 包,而是需要用户自己将相应的 Hadoop 依赖加入 HADOOP_CLASSPATH 环境变量(推荐的方式)或者将 Hadoop 依赖加入到 lib/目录下。
[FLINK-16963]
所有 Flink 内置的 Metric Report 现在被修改为 Flink 的插件。如果要使用它们,不应该放置到 lib/目录下(会导致类冲突),而是要放置到 plugins/目录下。
[FLINK-12639]
社区正在对 Flink 文档进行重构,从1.11开始,您可能会注意到文档的导航和内容组织发生了一些变化。
如果你想要升级到1.11的话,请详细阅读详细发布说明。与之前所有1.x版本相比,1.11可以保证所有标记为@Public的接口的兼容。
7月6日,首期 Flink 极客训练营经过半月的 精心打磨 ,
一天时间里2000名额秒没,然而还有非常多的同学来问:
“我才刚看到,名额就没了
“我太想参加了,还能补报吗?
确实,全 Apache Flink PMC 及 Committer 阵容手把手实操,还有超多精美福利周边,小松鼠都想报!
1.11 新版发布隐藏福利,
极客训练营
最后的1000个名额
,抢不到的同学只能预约下期啦,不用再问小松鼠,问也是等!下!期!
详情了解:
报名截止: 2020 年 7 月 12 日 18:00
报名方式:
后台回复关键字
「
训练营
」即可抢报
酷炫周边抢先看
关注 Flink 中文社区,获取更多技术干货
以上是关于官宣 | 千呼万唤,Apache Flink 1.11.0 正式发布啦!(内含福利)的主要内容,如果未能解决你的问题,请参考以下文章
官宣|Apache Flink 1.13.0 正式发布,流处理应用更加简单高效!
Flink 官宣 | Apache Flink 1.12.0 正式发布,流批一体真正统一运行!
官宣|Apache Flink 1.14.0 发布公告
官宣|Apache Flink 1.14.0 发布公告
官宣|Apache Flink 1.14.0 发布公告
官宣|Apache Flink 1.13.0 正式发布,流处理应用更加简单高效!
 ”
”
 ”
”
