微博基于Flink的机器学习实践
Posted 架构师社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微博基于Flink的机器学习实践相关的知识,希望对你有一定的参考价值。
分享嘉宾:于茜 微博 高级算法工程师
编辑整理:王洪达
内容来源:Flink Forward
导读:微博作为国内比较主流的社交媒体平台,目前拥有2.22亿日活用户和5.16亿月活用户。如何为用户实时推荐优质内容,背后离不开微博的大规模机器学习平台。本文由微博机器学习研发中心高级算法工程师于茜老师分享,主要内容包含以下四部分:
关于微博
微博机器学习平台 ( WML ) 总览
Flink在WML中的应用
使用Flink的下一步计划

微博2008年上线,是目前国内比较主流的社交媒体平台,拥有2.22亿日活用户和5.16亿月活用户,为用户提供在线创作、分享和发现优质内容的服务;目前微博的大规模机器学习平台可以支持千亿参数和百万QPS。
接下来介绍一下微博机器学习平台,即WML的总览;机器学习平台 ( WML ) 为CTR、多媒体等各类机器学习和深度学习算法提供从样本处理、模型训练、服务部署到模型预估的一站式服务。
1. 总览
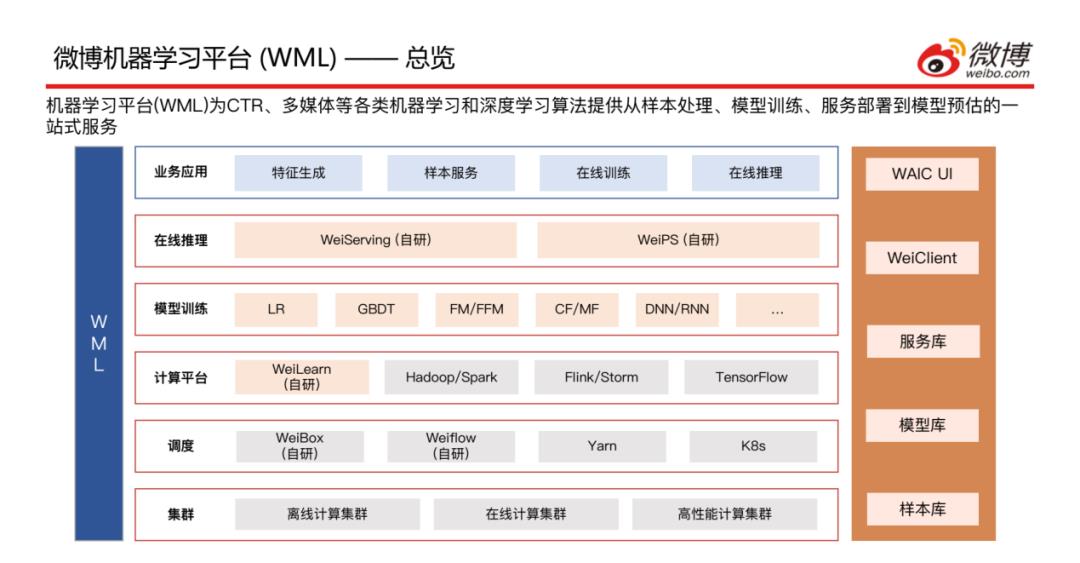
上方是WML的一个整体架构图,共分为六层,从下至上依次介绍:
集群层:包含离线计算集群、在线计算集群和高性能计算集群;
调度层:包含自研的WeiBox ( 提供使用通用的接口将任务提交到不同集群的能力 )、Weiflow ( 提供将任务间的依赖关系处理好、组成DAG工作流的能力 ),以及常见的调度引擎Yarn和K8s;
计算平台层:包含自研的WeiLearn ( 提供给用户在该平台做业务开发的能力 ),以及Hadoop/Spark离线计算平台、Flink/Storm在线计算平台和Tensorflow机器学习平台;
模型训练层:目前支持LR、GBDT、FM/FFM、CF/MF、DNN/RNN等主流的算法;
在线推理层:包含自研的WeiServing和WeiPS;
业务应用层:主要应用场景是特征生成、样本服务、在线训练和在线推理;
右边是自定义的一些概念,样本库、模型库、服务库以及两个任务提交方式WeiClient ( CLI方式提交 )、WAIC UI ( 界面操作 )。
2. 开发模式
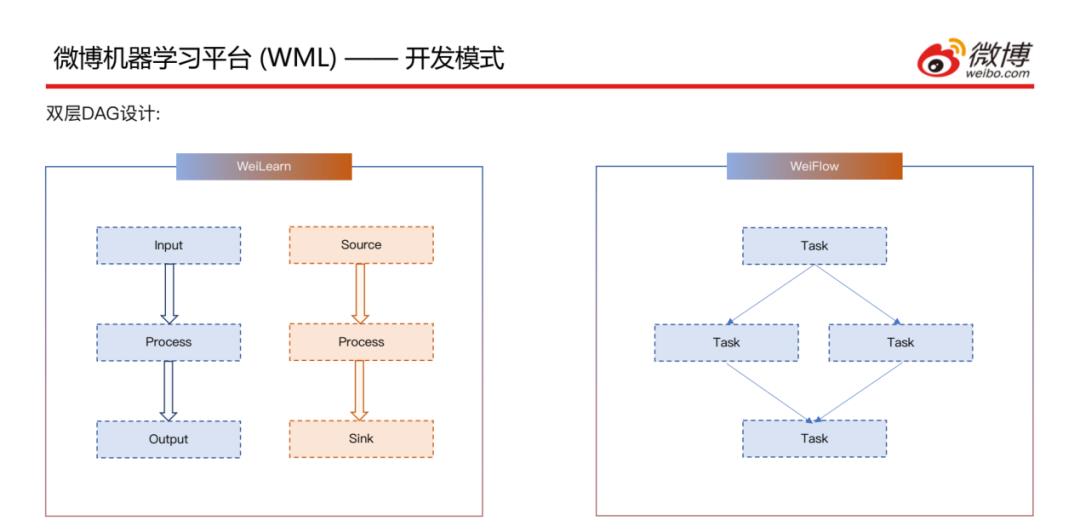
接下来介绍一下开发模式,有两层DAG的设计:
内层,WeiLearn层里面可以重写离线的Input、Process和Output方法以及实时的Source、Process和Sink方法,用户自己开发一个UDF来实现自己的业务逻辑;内层的每一个DAG都会组成一个Task。
外层,即第二层DAG层,WeiFlow层里面将WeiLearn中产生的Task的依赖关系组成一个集群内或者跨集群的WorkFlow,然后运行计算。
3. CTR模型
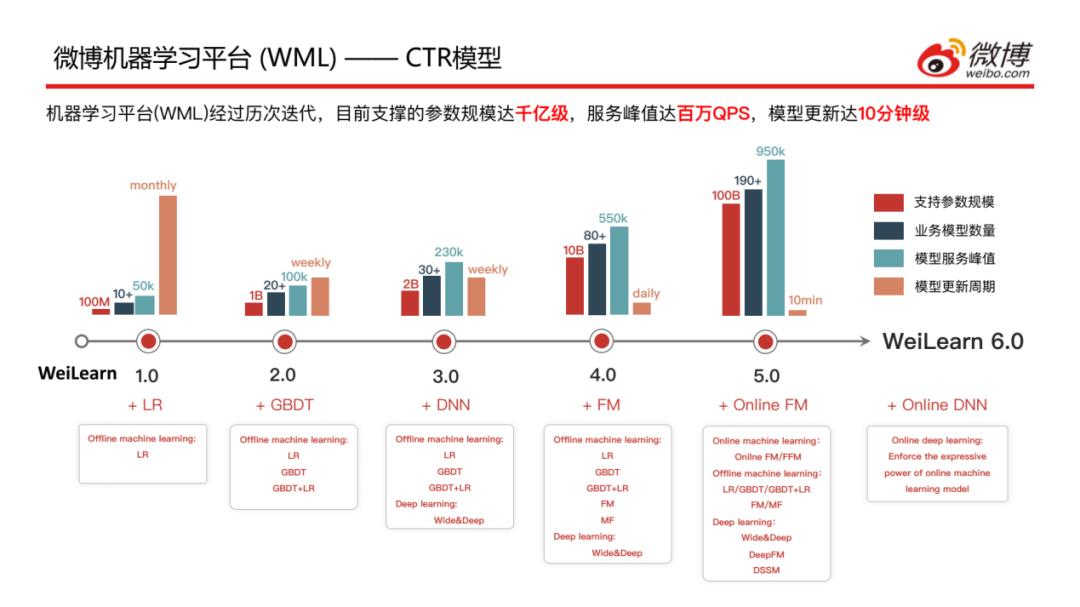
介绍一下CTR模型在微博迭代的情况,经过几年的研究和探索,目前支撑的参数规模达千亿级,服务峰值达百万QPS,模型更新的周期大概在10分钟左右;现在是Weilearn6.0版本,可以看到WeiLearn在不断完善更新自己的算法:
1.0版本仅支持LR离线学习
2.0版本支持LR/GBDT/LR+GBDT离线学习
3.0版本支持LR/GBDT/LR+GBDT离线学习以及Wide&Deep的深度学习
4.0版本支持LR/GBDTLR+GBDT/FM/MF离线学习以及Wide&Deep的深度学习
5.0版本支持Online FM/FFM在线学习,LR/GBDT/LR+GBDT/FM/MF离线学习以及Wide&Deep/DeepFM/DSSM的深度学习
6.0版本更新了Online DNN模型,加强在线机器学习模型的表达能力
下面介绍Flink在微博机器学习平台WML中的架构
1. 概览
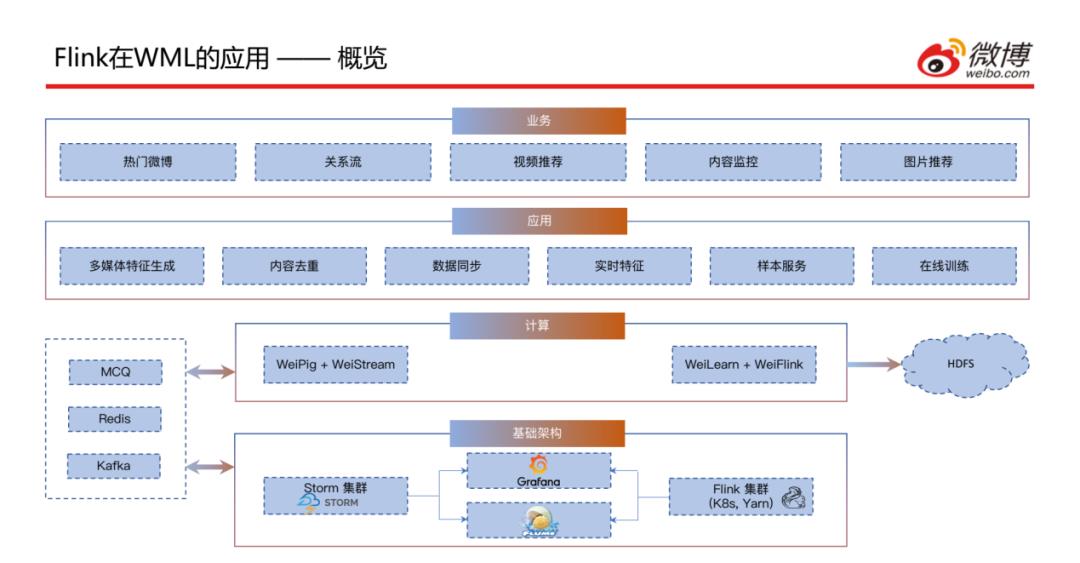
上图为实时计算平台的整体情况,接下来详细介绍一下各模块:
基础架构层:包含Storm集群、Flink集群、Flume以及用于监控系统运行的Grafana。
计算层:主要是对Pig和Flink的进一步封装,包含WeiPig + WeiStream和WeiLearn + WeiFlink;左侧为实时数据源,包含实时消息队列、Redis、Kafka;一些历史数据会存到右侧的HDFS中。
应用层:目前这套平台主要应用于多媒体特征生成、内容去重、数据同步、实时特征生成、样本服务以及在线训练。
业务层:支撑了目前微博主要的几个业务,包含热门微博、关系流、视频推荐、内容监控和图片推荐。
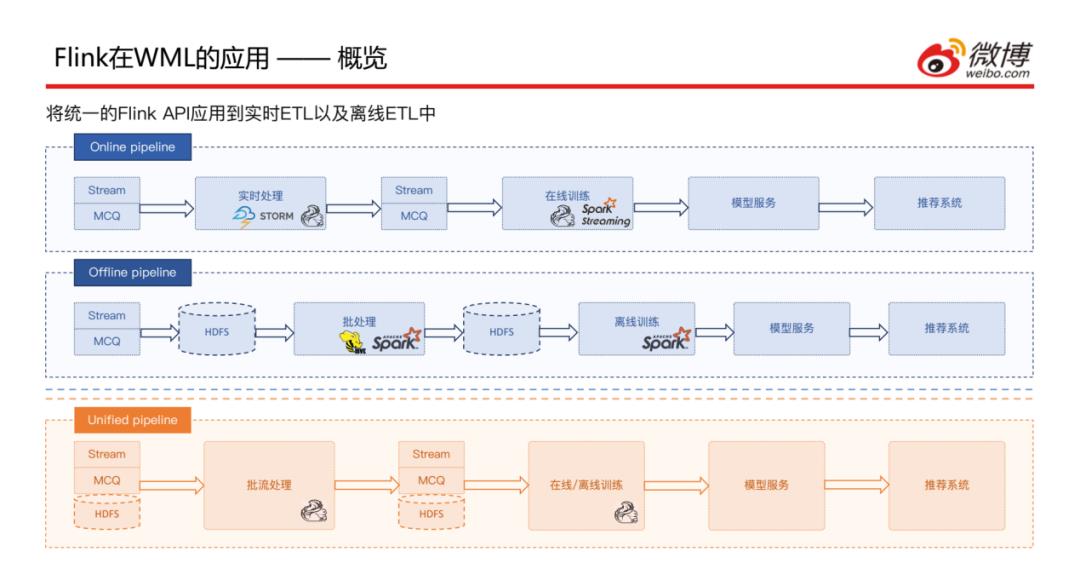
接下来看一下Flink在ETL的Pipeline中的概览:之前是有两个Pipeline,一个为在线的,以前是使用Storm进行的处理,目前正在往Flink迁移,两套现在处于并行状态,处理流程是从消息队列中获取数据进行处理,然后给到在线训练模块 ( Flink和Spark Streaming并行 ),最后提供模型服务给推荐系统调用;一个为离线的,和在线类似,首先写入到HDFS交给Hive或Spark进行处理,再次落到HDFS中交给离线训练使用,最后提供模型服务给推荐系统调用。因为有两类ETL的Pipeline,使用不同的框架,需要维护两套代码,维护成本较高。
目前做的就是将两套融合成一套,进行批流统一的处理,此处可能会用到FlinkSQL,然后将ETL后的数据输出到实时消息队列或者HDFS中,交给在线和离线模型训练,最后提供模型服务给推荐系统调用。
2. 样本服务
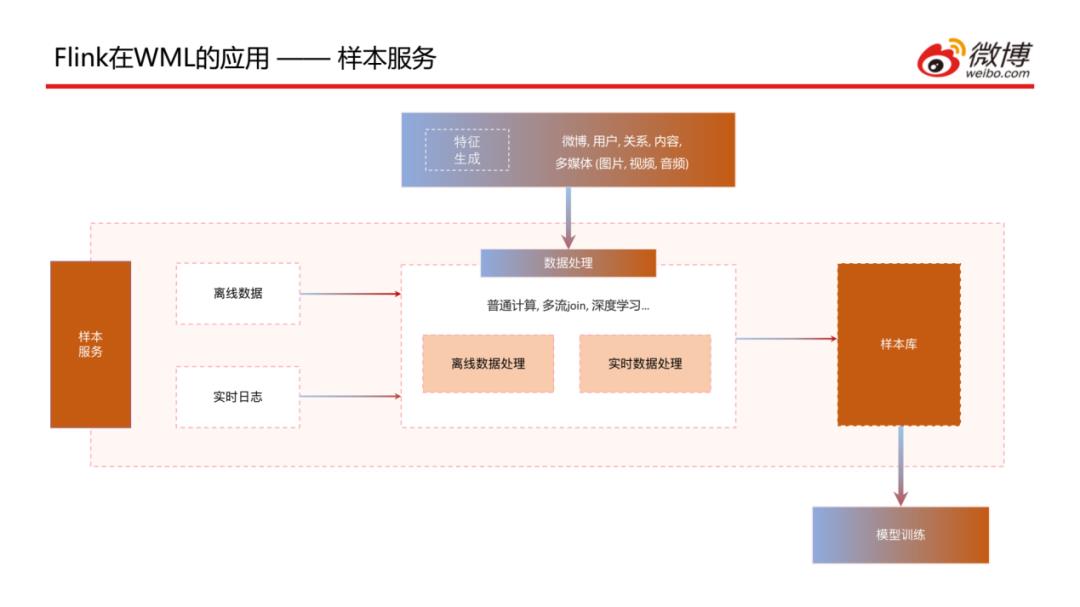
介绍一下样本生成服务,上图为该服务的整体架构图,包含样本数据的处理和计算等,除了一些生成的离线和实时数据外,还需要一些已经生成好的特征的引用,通过普通计算、多流Join、深度学习等处理方式生成样本,最后存储到样本库中供模型训练来调用。
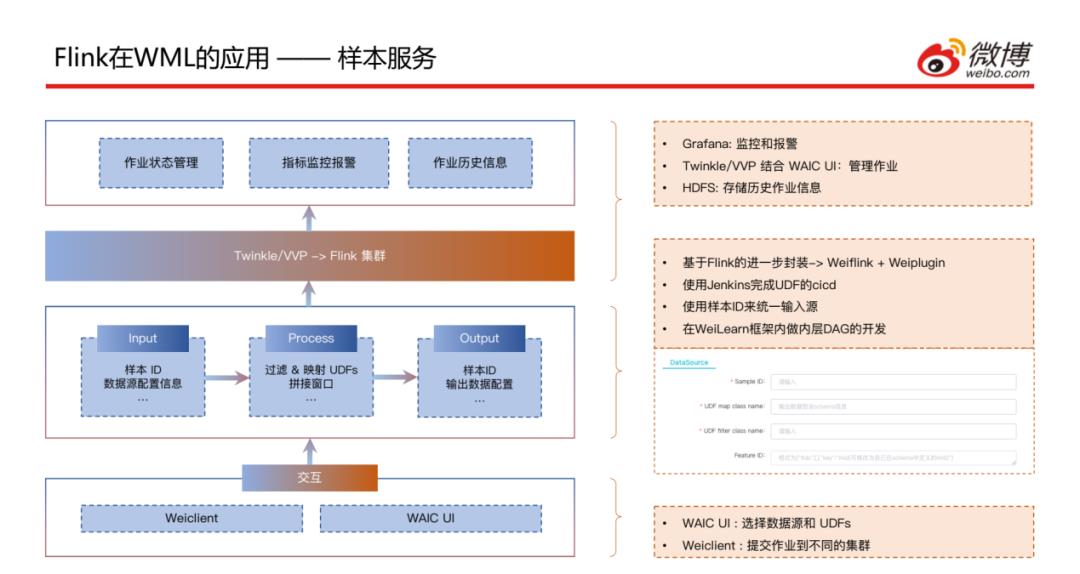
这个是样本服务任务提交的方式,可以通过之前提到的WeiClient命令行方式提交,也可以通过WAIC UI方式指定样本ID以及UDF的class name和要拼接的特征ID,通过一种统一的方式将作业提交到集群上;之后是通过Twinkle或VVP的方式提交到Flink集群,然后会对作业状态进行管理,通过Grafana进行监控和报警,将历史作业信息存储到HDFS中。
3. 多流Join
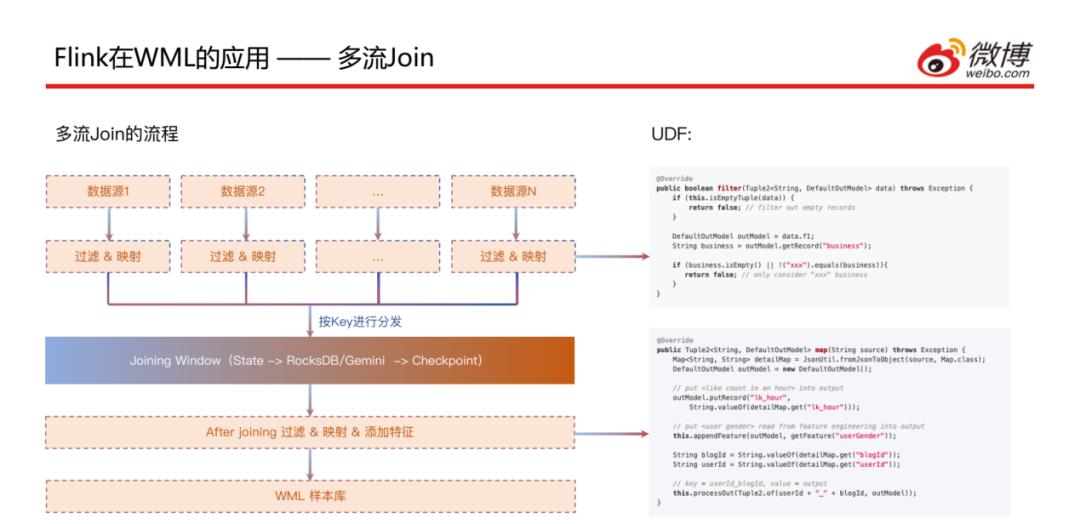
这是微博目前的一个主流场景,多数据流Join场景 ( 大部分是大于等于3 ):有N个数据源,通过过滤和映射的处理后按照Key进行分发,在Joining Window中进行join后 ( 此处后面会详细讲 ),会再进行一次过滤和映射以及添加特征,最后输出到样本库中。
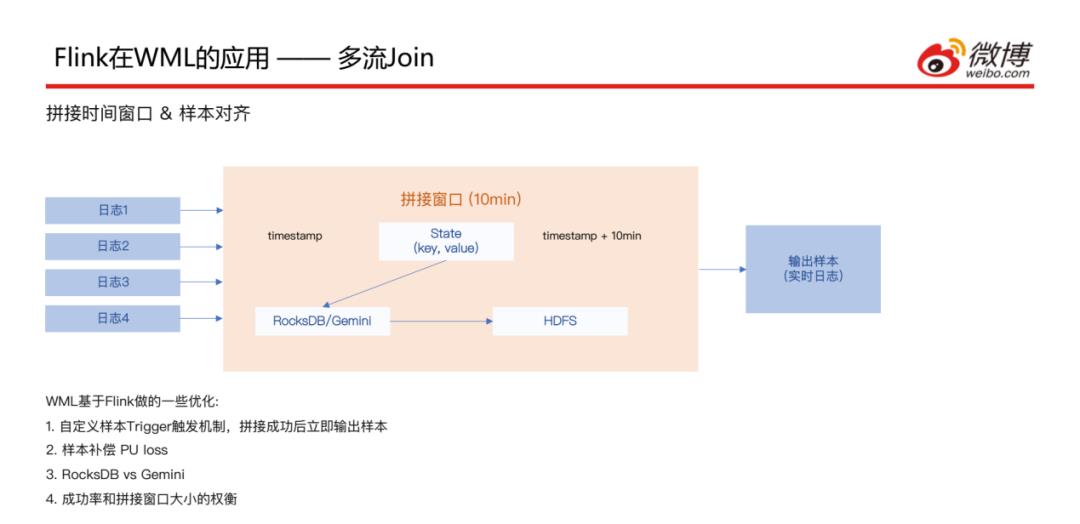
接下来看一下刚刚讲到的拼接窗口的实现方式,这是和业务比较相关的,对于CTR场景来说日志有很多种 ( 多个行为日志 ),但是到达的时间并不完全一致,比如点击这种行为日志可能会比曝光日志到的晚一些;这样就会需要一个时间窗口,以10分钟为例,如果某种日志先到了,就会将对应的key和value存储到State中,状态存储这块是基于RocksDB和HDFS做的;经过这个十分钟窗口之后,拼接好的样本数据会输到实时流中;此处基于Flink做了一些优化:
因为窗口是10分钟的,但是如果10分钟内日志数据已经全部到达,就不同等到10分钟窗口结束后再输出去;所以自定义了样本trigger触发机制,样本拼接成功后就可以立即输出,这样可以减少一些时延
样本补偿 PU loss;此处是基于Twitter在2019年发的一篇论文的实现方式,就是拿到正样本之后,首先对正样本做一个梯度下降的处理,另外可能之前有False Negative的样本已经发送出去了,那就需要之前的样本进行补偿,所以需要对该样本的负样本做一个反向的梯度下降
另外在RocksDB做状态存储这部分,引用了Gemini与RocksDB作对比,Gemini的IO性能更好一些
拼接窗口时长的控制是和业务场景比较相关的,日志到达的时间和具体的业务场景是有关系的,所以需要权衡时间窗口设置多长时间才能满足拼接成功率的预期,这块需要大量的离线计算和A/B Test来共同决定。
4. 多媒体特征生成
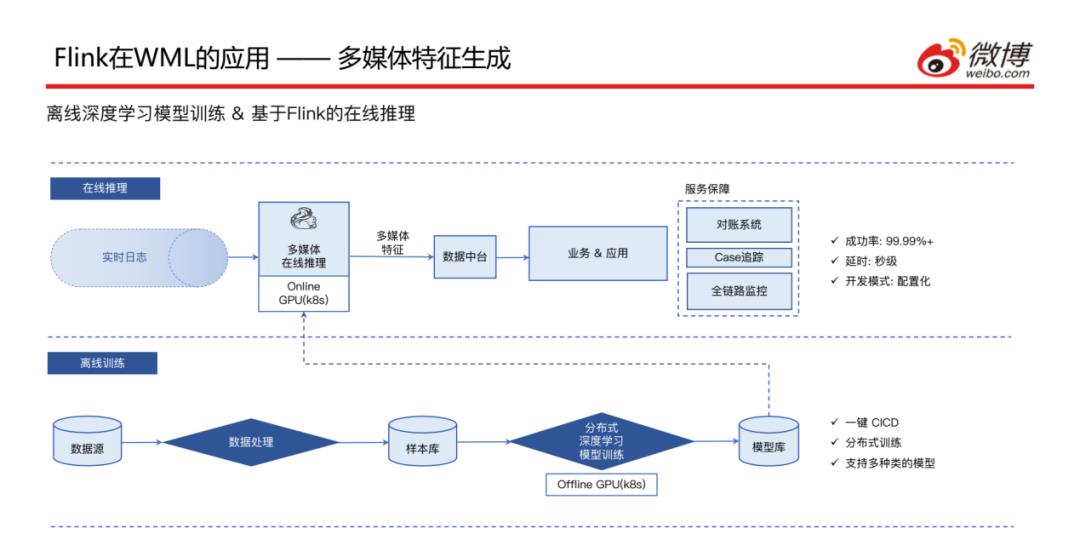
介绍一下Flink在多媒体特征生成场景的应用,此处主要是依赖离线计算的深度学习模型,因此整体的模型训练走的是离线的Pipeline,将数据在离线的GPU集群进行分布式的模型训练,然后将模型部署到GPU上面供在线推理的时候调用;在线推理模块接收到图片流、文本流和视频流这些实时数据之后,首先会通过RPC调用GPU上的模型,然后将多媒体特征结果写入到数据中台,由业务方去读取结果来使用,因为这块是一个实时的任务作业,服务稳定性需要一定的保障 ( 4个9的成功率、秒级延迟、配置化开发模式 ),下面会对服务保障做详细介绍。
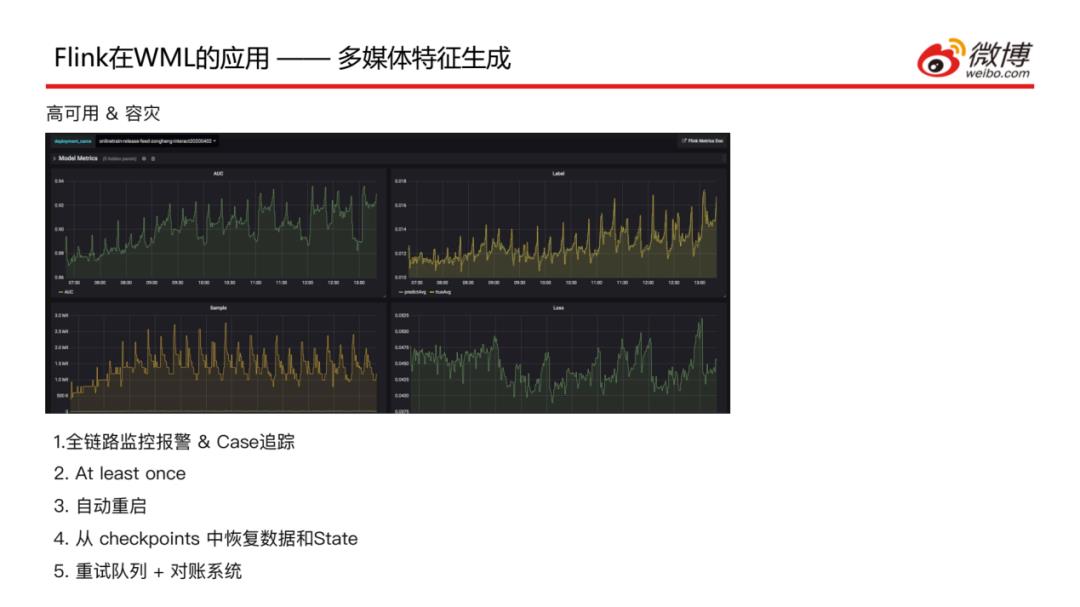
针对实时任务的服务保障做了如下的工作:
全链路监控报警&Case追踪,针对模型服务到RPC的情况、模型关键指标以及样本情况整体是有一个全流程的监控
设置消息机制是At least once,每条消息至少要被处理一次,这样可以保障每条数据结果都能写到特征工程中
任何一个部分出现问题都会实现自动重启
重启时可以从checkpoints中恢复数据和State,可以避免一些重复计算,也是为了减少一些延时
所有实时任务都会起一个重试的任务,这样在主流程中写入失败,会再次写入到重试队列中再进行一次重试的写入,这样保障数据会被计算两次;如果最终还是写入失败,就会记录到对账离线系统中,这样可以看到哪些数据是写入失败的,可以手动恢复一下。
最后分享一下使用Fllink的下一步计划:
1. 实时数仓
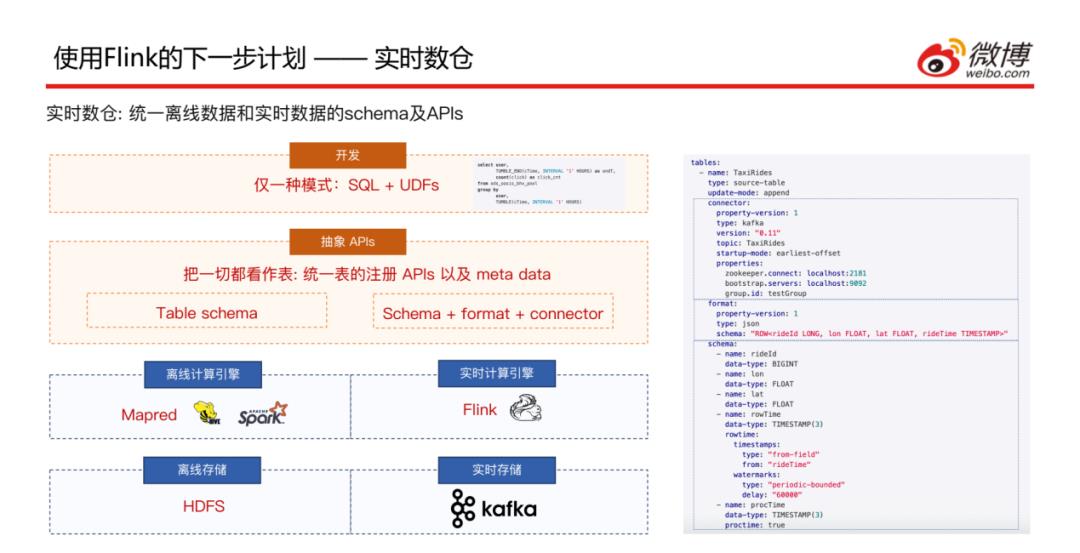
目前已经通过Flink SQL的方式实现了开发,但是实时和离线表的注册还有元数据存储是有一定差异的,希望可以抽象出一层API用统一的方式来进行实时和离线表的注册以及元数据的存储。
2. 基于Flink的DL
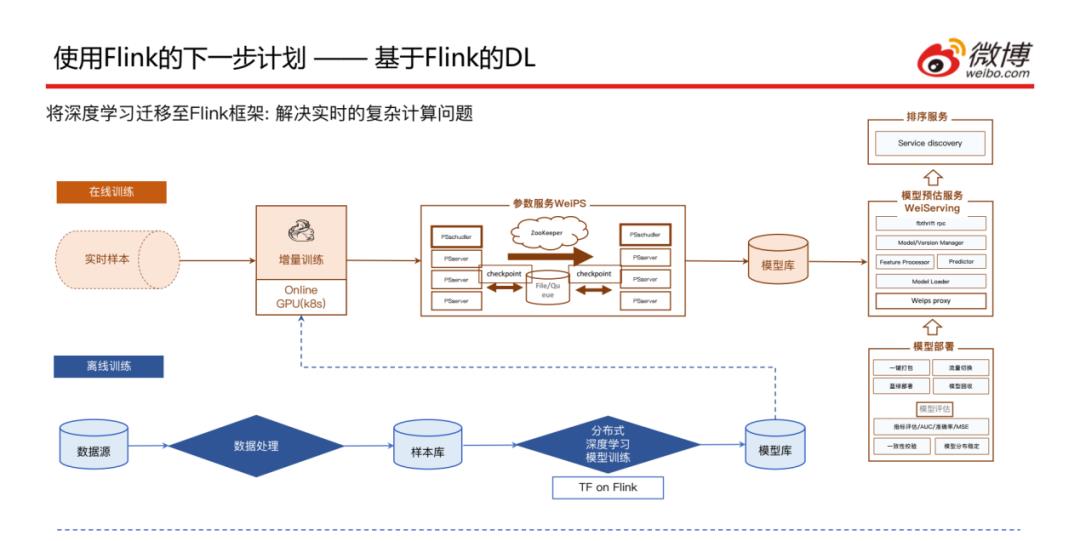
我们希望可以将离线的深度学习完全迁移到在线深度学习来做,这样的话就需要用到TensorFlow on Flink,这样就可以保证不管是模型训练还是在线推理都可以使用同样一套框架去完成,这样就需要把离线训练的全量模型也可以通过实时样本进行增量训练的一些校正,后面的步骤和之前基本上是保持一致的,这样就可以将离线深度学习的这条Pipeline优化一些。
本次的分享就到这里,谢谢大家。
嘉宾介绍:
于茜,微博机器学习研发中心高级算法工程师。多年来致力于使用 Flink 构建实时数据处理和在线机器学习框架,有丰富的社交媒体应用推荐系统的开发经验。
特别推荐一个分享架构+算法的优质内容,还没关注的小伙伴,可以长按关注一下:


长按订阅更多精彩▼
如有收获,点个在看,诚挚感谢
以上是关于微博基于Flink的机器学习实践的主要内容,如果未能解决你的问题,请参考以下文章