Flink 实时计算在微博的应用
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 实时计算在微博的应用相关的知识,希望对你有一定的参考价值。
简介: 微博通过将 Flink 实时流计算框架跟业务场景相结合,在平台化、服务化方面做了很大的工作,在开发效率、稳定性方面也做了很多优化。我们通过模块化设计和平台化开发,提高开发效率。
微博机器学习研发中心数据计算负责人,高级系统工程师曹富强为大家带来 Flink 实时计算在微博的应用介绍。内容包括:1、微博介绍
2、数据计算平台介绍
3、Flink 在数据计算平台的典型应用
一、微博介绍
本次给大家带来的分享是 Flink 实时计算在微博的应用。微博是中国领先的社交媒体平台,目前的日活跃用户是 2.41 亿,月活跃用户是 5.5 亿,其中移动用户占比超过了 94%。

二、数据计算平台介绍
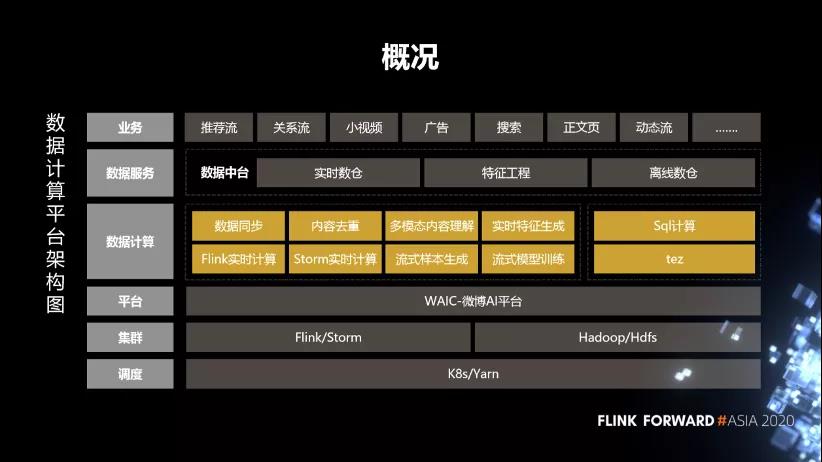
1. 数据计算平台概况
下图为数据计算平台的架构图。
- 首先是调度,这块基于 K8s 和 Yarn 分别部署了实时数据处理的 Flink、Storm,以及用于离线处理的 SQL 服务。
- 在集群之上,我们部署了微博的 AI 平台,通过这个平台去对作业、数据、资源、样本等进行管理。
- 在平台之上我们构建了一些服务,通过服务化的方式去支持各个业务方。
1.实时计算这边的服务主要包括数据同步、内容去重、多模态内容理解、实时特征生成、实时样本拼接、流式模型训练,这些是跟业务关系比较紧密的服务。另外,还支持 Flink 实时计算和 Storm 实时计算,这些是比较通用的基础计算框架。
2.离线这部分,结合 Hive 的 SQL,SparkSQL 构建一个 SQL 计算服务,目前已经支持了微博内部绝大多数的业务方。 - 数据的输出是采用数仓、特征工程这些数据中台的组建,对外提供数据输出。整体上来说,目前我们在线跑的实时计算的作业将近 1000 多个,离线作业超过了 5000 多个,每天处理的数据量超过了 3 PB。
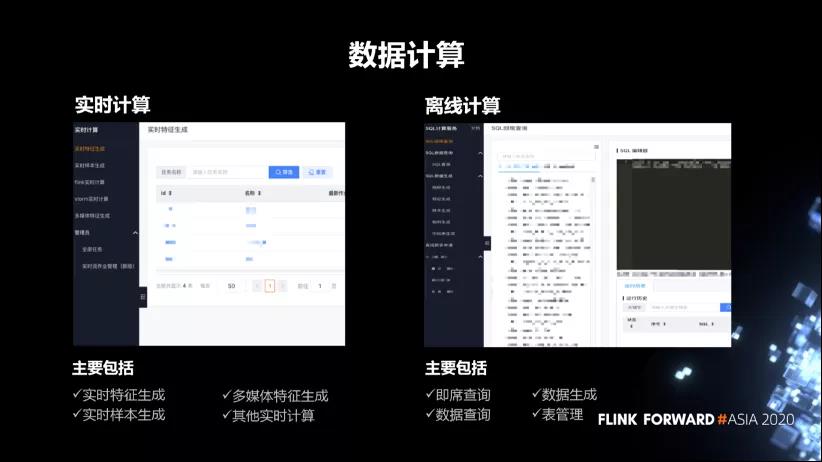
2. 数据计算
下面两张图是数据计算,其中一个是实时计算,另外一个是离线计算。
- 实时计算主要包括实时的特征生成,多媒体特征生成和实时样本生成,这些跟业务关系比较紧密。另外,也提供一些基础的 flink 实时计算和 storm 实时计算。
- 离线计算主要包括 SQL 计算。主要包括 SQL 的即席查询、数据生成、数据查询和表管理。表管理主要就是数仓的管理,包括表的元数据的管理,表的使用权限,还有表的上下游的血缘关系。
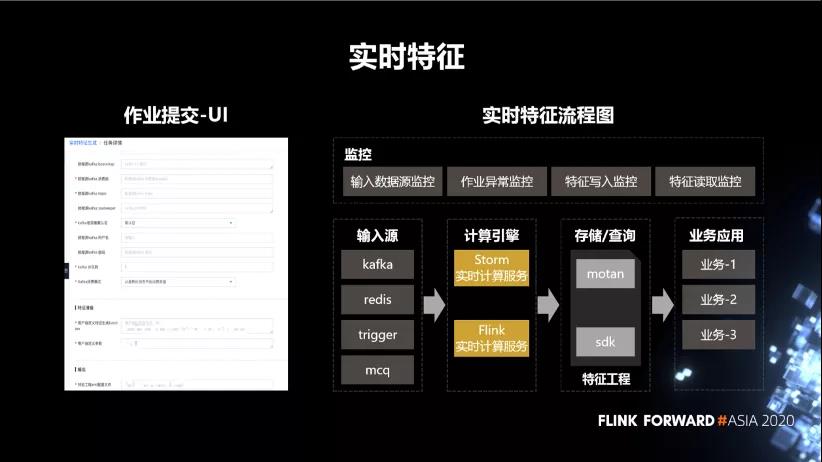
3. 实时特征
如下图所示,我们基于 Flink 和 Storm 构建了一个实时特征生成的服务。整体上来说,它会分为作业详情、输入源特征生成、输出和资源配置。用户按照我们事先定义好的接口去开发特征生成的 UDF 就可以。其他的像输入、特征写入,都是平台自动提供的,用户只需要在页面上配置就好。另外,平台会提供输入数据源的监控、作业的异常监控、特征写入监控、特征读取监控等,这些都是自动生成的。
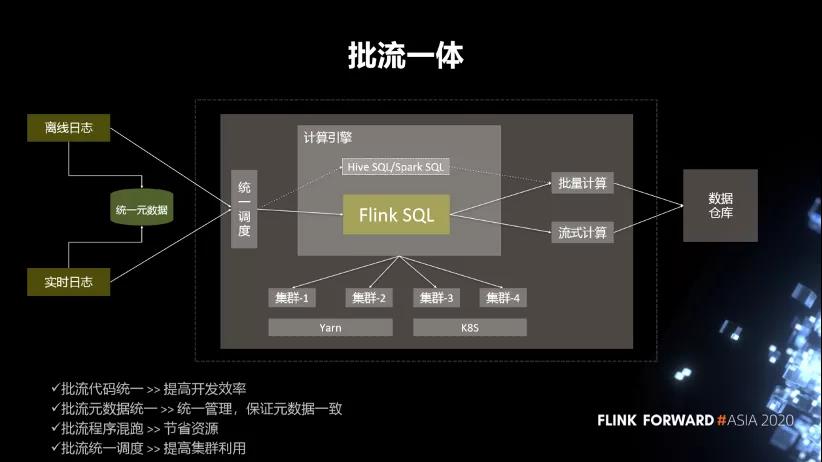
4. 流批一体
下面介绍我们基于 FlinkSQL 构建的批流一体。首先,我们会统一元数据,将实时日志跟离线日志通过元数据管理平台去统一。统一之后,用户在提交作业的时候,我们会有一个统一的调度层。调度这一块,是根据作业的类型,作业的特点,目前集群的负载的情况,将作业调度到不同的集群上去。
目前调度层支持的计算引擎主要就是 HiveSQL,SparkSQL 跟 FlinkSQL。Hive 和 Spark 的 SQL 主要用于批量计算,FlinkSQL 是做批流混跑。整个结果会输出到数据仓库中,提供给业务方使用。批流一体这块大概有 4 个关键点:
- 第一,批流代码统一,提高开发效率。
- 第二,批流元数据统一。统一管理,保证元数据一致。
- 第三,批流程序混跑,节省资源。
- 第四,批流统一调度,提高集群利用率。
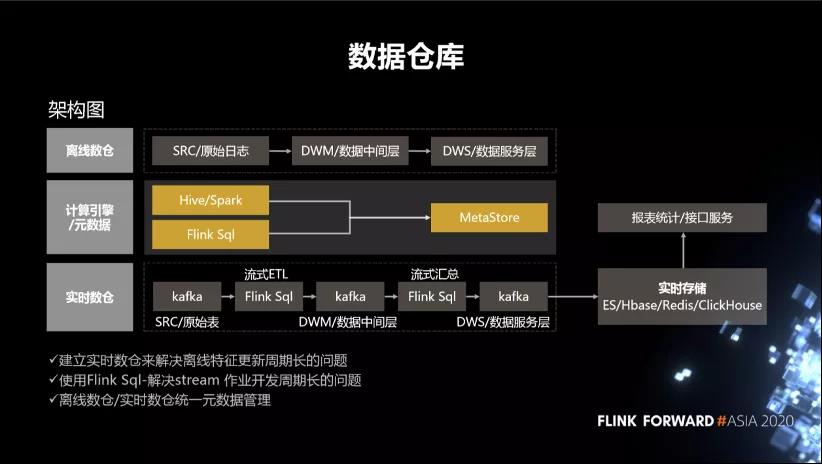
5. 数据仓库
- 针对离线仓库,我们把数据分成了三层,一个是原始日志,另外一个是中间层,还有一个是数据服务层。中间是元数据的统一,下边是实时数仓。
- 针对实时数仓,我们通过 FlinkSQL 对这些原始日志做流式的一个 ETL,再通过一个流式汇总将最终的数据结果写到数据的服务层,同时也会把它存储到各种实时存储,比如 ES、Hbase、Redis、ClickHouse 中去。我们可以通过实时存储对外提供数据的查询。还提供数据进一步数据计算的能力。也就是说,建立实时数仓主要是去解决离线特征生成的周期长的问题。另外就是使用 FlinkSQL 去解决 streaming 作业开发周期比较长的问题。其中的一个关键点还是离线数仓跟实时数仓的元数据的管理。
三、Flink 在数据计算平台的典型应用
1. 流式机器学习
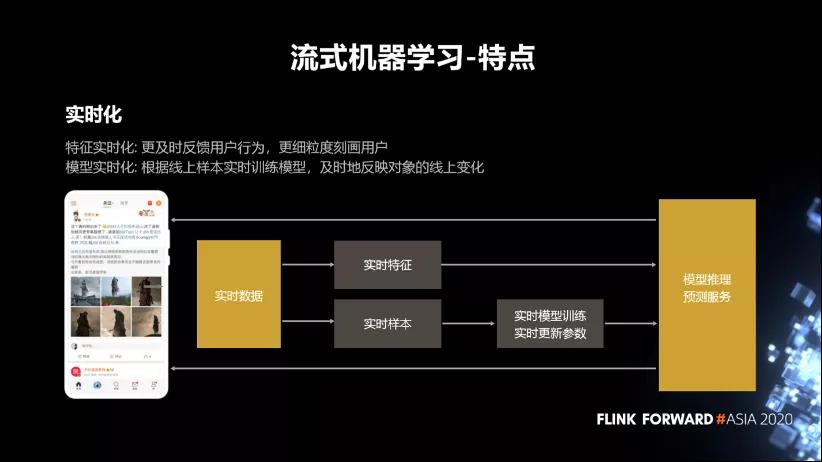
首先介绍流式机器学习的几个特点,最大的特点就是实时化。这块分为特征的实时化和模型的实时化。
- 特征实时化主要是为了更及时的去反馈用户行为,更细粒度的去刻画用户。
- 模型实时化是要根据线上样本实时训练模型,及时反映对象的线上变化情况。
■ 微博流式机器学习的特点:
- 样本的规模大,目前的实时样本能达到百万级别的 qps。
- 模型的规模大。模型训练参数这块,整个框架会支持千亿级别的训练规模。
- 对作业的稳定性要求比较高。
- 样本的实时性要求高。
- 模型的实时性高。
- 平台业务需求多。
■ 流式机器学习有几个比较难的问题:
- 一个就是全链路,端到端的链路是比较长的。比如说,一个流式机器学习的流程会从日志收集开始,到特征生成,再到样本生成,然后到模型训练,最终到服务上线,整个流程非常长。任何一个环节有问题,都会影响到最终的用户体验。所以我们针对每一个环节都部署了一套比较完善的全链路的监控系统,并且有比较丰富的监控指标。
- 另外一个是它的数据规模大,包括海量的用户日志,样本规模和模型规模。我们调研了常用的实时计算框架,最终选择了 Flink 去解决这个问题。

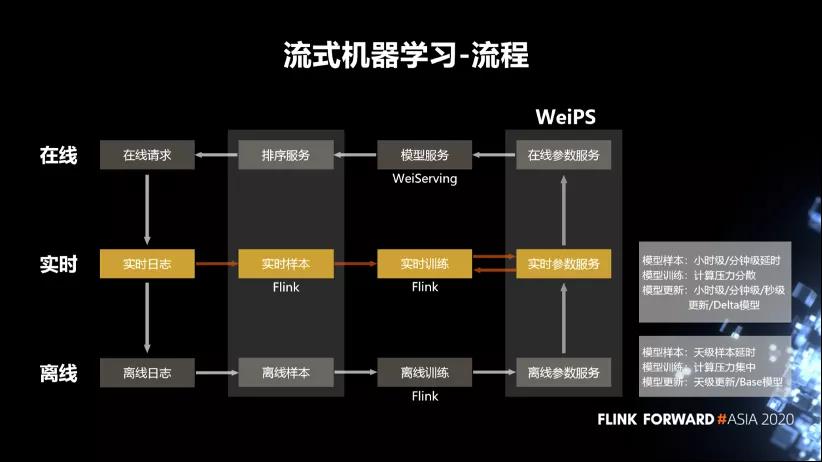
■ 流失机器学习流程:
- 首先是离线训练,我们拿到离线日志,去离线的生成样本之后,通过Flink去读取样本,然后去做离线训练。训练完成之后把这些训练的结果参数保存在离线的参数服务器中。这个结果会作为模型服务的 Base 模型,用于实时的冷启动。
- 然后是实时的流式机器学习的流程。我们会去拉取实时的日志,比如说微博的发布内容,互动日志等。拉取这些日志之后,使用 Flink 去生成它的样本,然后做实时的训练。训练完成之后会把训练的参数保存在一个实时的参数服务器中,然后会定期的从实时的参数服务器同步到实时的参数服务器中。
- 最后是模型服务这一块,它会从参数服务中拉取到模型对应的那些参数,去推荐用户特征,或者说物料的特征。通过模型对用户和物料相关的特征、行为打分,然后排序服务会调取打分的结果,加上一些推荐的策略,去选出它认为最适合用户的这一条物料,并反馈给用户。用户在客户端产生一些互动行为之后,又发出新的在线请求,产生新的日志。所以整个流式学习的流程是一个闭环的流程。
另外,
- 离线的样本的延时和模型的更新是天级或者小时级,而流式则达到了小时级或者分钟级;
- 离线模型训练的计算压力是比较集中的,而实时的计算压力比较分散。
■ 样本
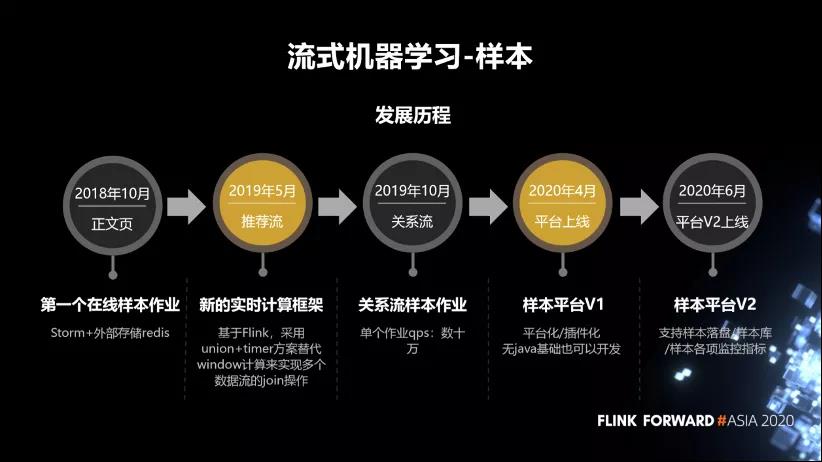
这里简单介绍一下我们流式机器学习样本的发展历程。2018 年 10 月,我们上线了第一个流式样本作业,是通过 Storm 和外部存储 Redis 去做的。2019 年 5 月,我们使用新的实时计算框架 Flink,采用 union+timer 方案替代 window 计算来实现多个数据流的 join 操作。2019 年 10月,上线了一个xx样本作业,单个作业的 qps 达到了几十万。在今年 4 月份,把样本生成流程平台化。到今年 6 月份,平台化做了一个迭代,支持样本的落盘,包括样本库,还有样本的各种监控指标的完善。
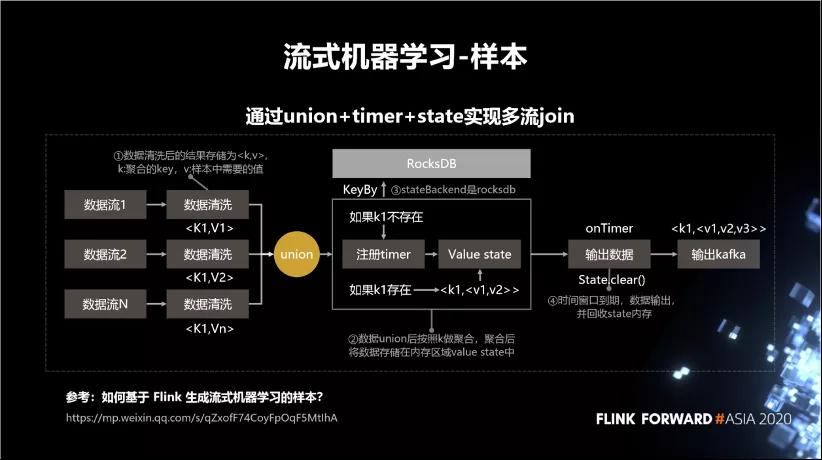
流式机器学习所谓的样本生成,其实就是多个数据流按照相同的 key 做一个拼接。比如说,我们有三个数据流,数据清洗后的结果存储为 , k 是聚合的 key,v 是样本中需要的值。数据 union 后做 KeyBy 聚合,聚合后将数据存储在内存区域 value state 中。如下图所示:
- 如果 k1 不存在,则注册 timer,再存到 state 中。
- 如果 k1 存在,就从 state 中把它给拿出来,更新之后再存进去。到最后它的 timer 到期之后,就会将这条数据输出,并且从 state 中清除掉。
■ 样本平台
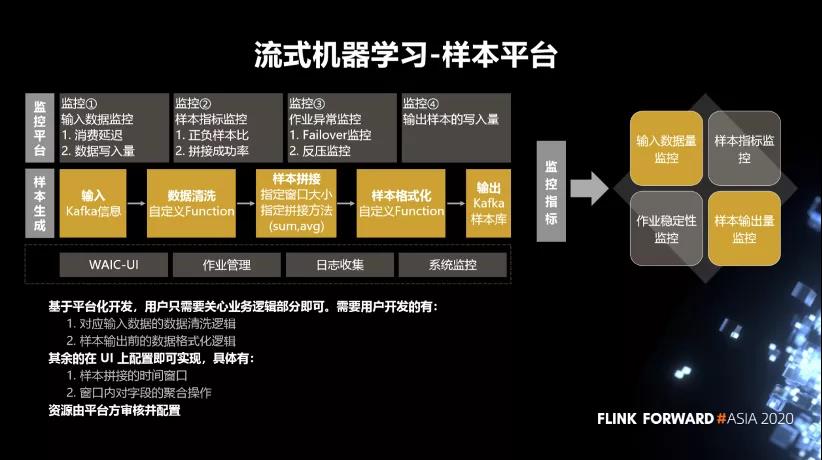
我们把整个样本拼接的过程做了一个平台化的操作,分成了 5 个模块,包括输入、数据清洗、样本拼接、样本的格式化和输出。基于平台化开发,用户只需要关心业务逻辑部分即可。需要用户开发的有:
- 对应输入数据的数据清洗逻辑。
- 样本输出前的数据格式化逻辑。
其余的在UI上配置即可实现,具体有:
- 样本拼接的时间窗口。
- 窗口内对字段的聚合操作。
资源由平台方审核并配置。另外,整个平台提供基础的一些监控,包括输入数据的监控、样本指标的监控、作业异常监控、样本输出量的监控。
■ 流式机器学习项目的样本 UI
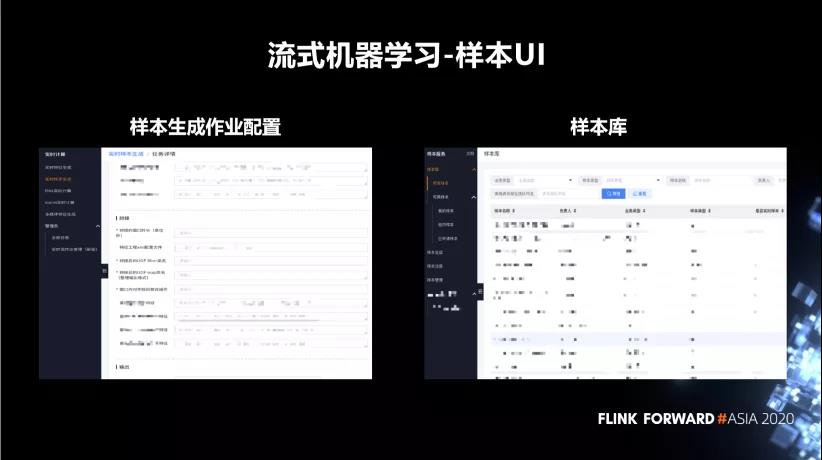
下图为流式机器学习项目的样本。左边是样本生成的作业配置,右边是样本库。样本库主要是做样本的管理展示,包括样本的说明权限,样本的共享情况等等。
■ 流失机器学习的应用
最后介绍一下流式机器学习应用的效果。目前我们支持实时样本拼接,QPS 达到百万级别。支持流式模型训练,可以同时支持几百个模型训练,模型实时性支持小时级/分钟级 模型更新。流式学习全流程容灾,支持全链路自动监控。近期在做的一个事情是流式的深度学习,增加实时模型的表达能力。还有强化学习这一块,探索一些新的应用场景。

2. 多模态内容理解
■ 简介
多模态就是使用机器学习的一些方法去实现或者理解多元模态信息的能力或者技术。微博的这块主要包括图片、视频、音频、文本。
- 图片这块包括,物体识别打标签、OCR、人脸、明星、颜值、智能裁剪。
- 视频这块包括版权检测、logo 识别。
- 音频这块有,语音转文本、音频的标签。
- 文本主要包括文本的分词、文本的时效性、文本的分类标签。
举个例子,我们一开始做视频分类的时候只用到了视频抽帧后的那些帧,也就是图片。后来第二次优化的时候,加入了音频相关的东西,还有视频对应的博文相关的东西,相当于把音频、图片、文本,多模态的融合考虑,更精准的去生成这个视频的分类标签。

■ 平台
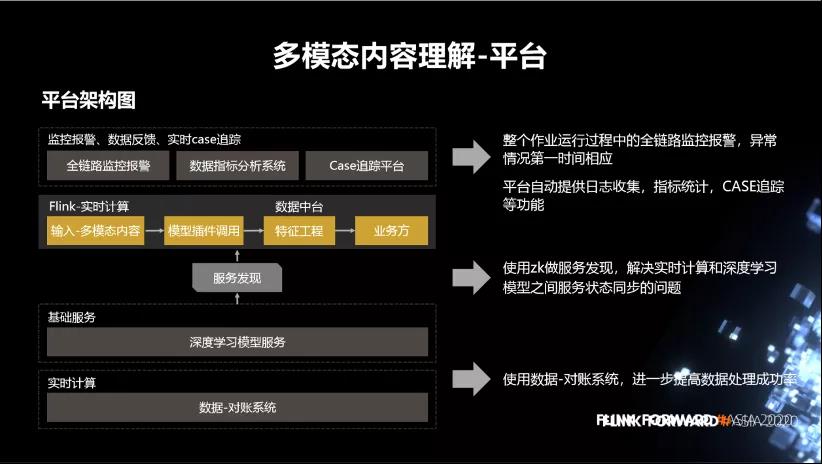
下图为多模态内容理解的平台架构。中间这部分是 Flink 实时计算,实时的接收图片流、视频流、发博流这些数据,然后通过模型插件调用下边的基础服务,深度学习模型服务。调用服务之后,会返回内容特征。然后我们把特征存储到特征工程,通过数据中台对外提供给各个业务方。整个作业运行过程中全链路监控报警,异常情况第一时间响应。平台自动提供日志收集,指标统计,CASE 追踪等功能。中间这一块使用 zk 做服务发现,解决实时计算和深度学习模型之间服务状态同步的问题。另外,除了状态同步,也会有一些负载均衡的策略。最下边就是使用数据-对账系统,进一步提高数据处理成功率。
■ UI
多模态内容理解的 UI,主要包括作业信息、输入源信息、模型信息、输出信息、资源配置。这块通过配置化的开发,去提高开发效率。然后会自动生成模型调用的一些监控指标,包括模型调用的成功率和耗时。当作业提交之后,会自动生成一个用于指标统计的作业。

3. 内容去重服务
■ 背景
在推荐场景下,如果给用户一直推重复的内容,是很影响用户体验的。基于这个考虑,结合 Flink 实时流计算平台、分布式向量检索系统和深度学习模型服务构建的一套内容去重服务平台,具有低延迟、高稳定性、高召回率的特点。目前支持多个业务方,稳定性达到 99.9+%。

■ 架构
下图为内容去重服务的架构图。最下边是多媒体的模型训练。这块做离线的训练。比如说我们会拿到一些样本数据,然后去做样本处理,样本处理完之后把样本存到样本库中去。当我需要做模型训练的时候,我从样本库中去拉取样本,然后做模型训练,训练好的结果会保存到模型库中去。
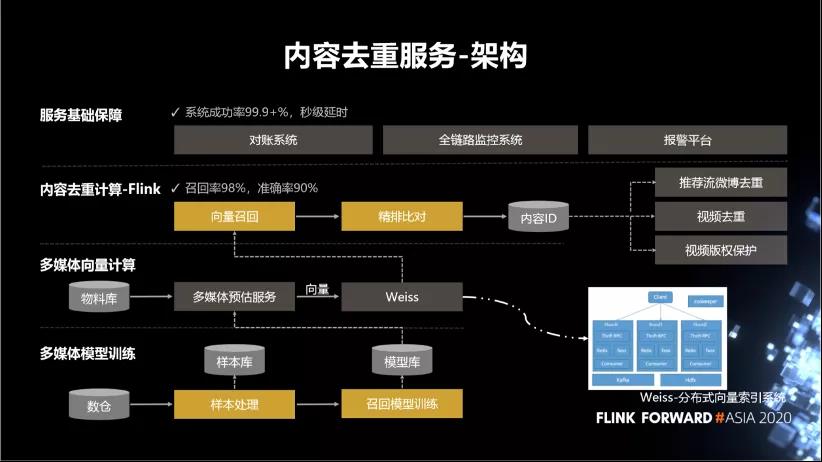
内容去重这里主要用到的模型是向量生成模型。包括图片的向量、文本的向量、视频的向量。
当我们把训练好的模型验证没有问题之后,会把这个模型保存到模型库中。模型库保存了模型的一些基础信息,包括模型的运行环境、版本。然后需要把模型部署上线,部署的过程需要从模型库中拉取模型,同时需要知道这个模型的运行的一些技术环境。
模型部署好之后,我们会通过 Flink 实时的从物料库中读取物料,然后调用多媒体预估服务去生成这些物料对应的向量。然后会把这些向量保存在 Weiss 库中,它是微博自研的一个向量召回检索系统。存到 Weiss 库中之后会对这条物料做向量召回的过程,召回跟这条物料相似的一批物料。在精排比对这块,会从所有的召回结果中加上一定的策略,选出最相似的那一条。然后把最相似的这一条跟当前物料聚合到一起,形成一个内容 ID。最后业务去用的时候,也是通过物料对应的内容 ID 做去重。
■ 应用
内容去重的应用场景,主要业务场景有三个:
- 第一,支持视频版权 - 盗版视频识别 - 稳定性 99.99%,盗版识别率 99.99%。
- 第二,支持全站微博视频去重 - 推荐场景应用 - 稳定性 99.99%,处理延迟秒级。
- 第三,推荐流物料去重 - 稳定性 99%,处理延迟秒级,准确率达到 90%

■ 最后
我们通过将 Flink 实时流计算框架跟业务场景相结合,在平台化、服务化方面做了很大的工作,在开发效率、稳定性方面也做了很多优化。我们通过模块化设计和平台化开发,提高开发效率。目前实时数据计算平台自带全链路监控,数据指标统计和 debug case 追踪(日志回看)系统。另外,基于 FlinkSQL 在批流一体这块目前也有一定的应用。这些都是 Flink 给我们带来的一些新的变化,我们会持续不断的探索 Flink 在微博中更大的应用空间。
本文为阿里云原创内容,未经允许不得转载。
以上是关于Flink 实时计算在微博的应用的主要内容,如果未能解决你的问题,请参考以下文章