干货丨从Paxos到Fast Paxos达Zookeeper分析
Posted 中兴开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货丨从Paxos到Fast Paxos达Zookeeper分析相关的知识,希望对你有一定的参考价值。
导读
张沛,一个“不安分”的程序员,开源社区爱好者,这篇文章系统分析了ZK的算法基础,让使用ZK作为分布式服务协调者的开发人员不再只是使用者,理解之后你会发现:其实这个算法很美。
一 Paxos 算法
1.1 基本定义
算法中的参与者主要分为三个角色,同时每个参与者又可兼领多个角色:

算法保重一致性的基本语义:

有上面的三个语义可演化为四个约束:

1.2 基本算法(basic paxos)
算法(决议的提出与批准)主要分为两个阶段:
1. prepare阶段:
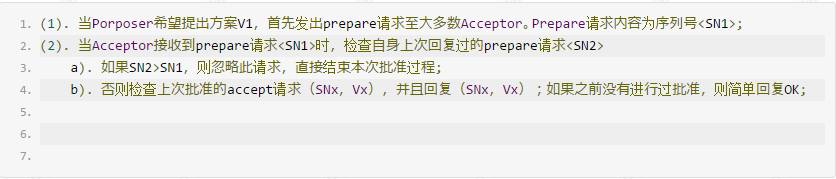
2. accept批准阶段:
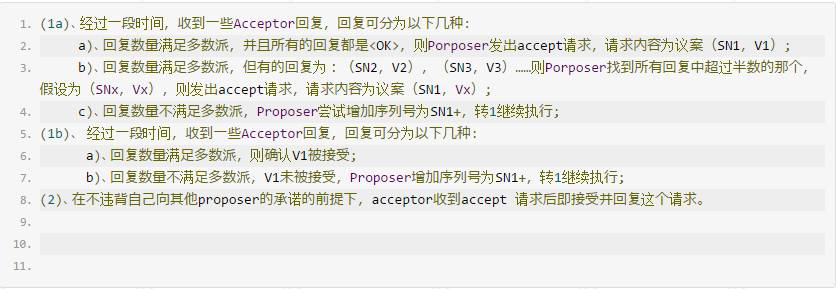
二 Fast Paxos
Lamport在40多页的论文中不仅提出了Fast Paxos算法,并且还从工程实践的角度重新描述了Paxos,使其更贴近应用场景。从一般的Client/Server来考虑,Client其实承担了Proposer和Learner的作用,而Server则扮演Acceptor的角色,因此下面重新描述了Paxos算法中的几个角色:

就是Client的提案由Coordinator进行,Coordinator存在多个,但只能通过其中被选定Leader进行;提案由Leader交由Server进行表决,之后Client作为Learner学习决议的结果。
这种方式更多地考虑了Client/Server这种通用架构,更清楚地注意到了Client既作为Proposer又作为Learner这一事实。同样要注意到的是,如果Leader宕机了,为了保证算法的正确性需要一个Leader的选举算法,但与之前一样,Lamport并不关心这个Leader选举算法,他认为可以简单地通过随机或超时机制实现。
另外在Classic Paxos中,从每次Proposer提案到决议被学习,需要三个通信步骤:

从直观上来说,Proposer其实更“知道”提交那个Value,如果能让Proposer直接提交value到Acceptor,则可以把通信步骤减少到2个。Fast Paxos便是基于此而产生。
2.1、Make Paxos Faster
我们再回顾下Classic Paxos的几个阶段:

很明显,在Phase2a.1中,如果Leader可以自由决定一个Value,则可以让Proposer提交这个Value,自己则退出通信过程。只要之后的过程运行正常,Leader始终不参与通信,一直有Proposer直接提交Value到Acceptor,从而把Classic Paxos的三阶段通信减少为两阶段,这便是Fast Paxos的由来。因此,我们形式化下Fast Paxos的几个阶段:
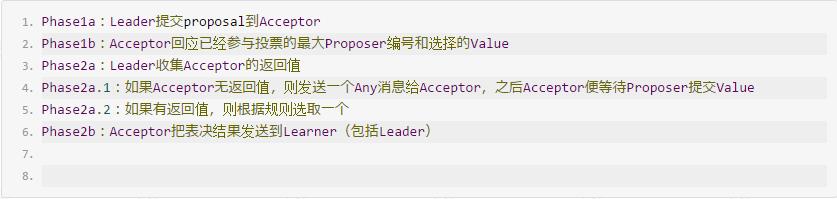
算法主要变化在Phase2a阶段,即:

先不考虑实现,从形式上消息仅需在

之间传递即可,也即仅需2个通信步骤。下面我们详细说明算法过程:
2.2、 一些定义
• Quorum
在Classic Paxos中一直通过多数派(Majority)来保证算法的正确性,对多数派再进一步抽象化,称为“Quorum”,要求任意两个Quorum之间有交集(从而间接表达了majority的含义)
• Round
在Classic Paxos中,Proposer每次提案都用一个全序的编号表示,如果执行顺利,该编号的Proposal在经历Phase1,Phase2后最终会执行成功。
在Fast Paxos称这个带编号的Proposal的执行过程为“Round”
• i-Quorum
在Classic Paxos执行过程中,一般不会明确区分每次Round执行的Quorum,虽然也可以为每个Round指定一个Quorum。在Fast Paxos中会通过i-Quorum明确指定Round i需要的Quorum
• Classic Round
执行Classic Paxos的Round称为Classic Round
• Fast Round
如果Leader发送了Any消息,则认为后续通信是一个Fast Round;若Leader未发送Any消息,还是跟之前一样通信,则后续行为仍然是Classic Round。
根据Lamport描述,Classic Round和Fast Round可通过Round Number进行加以区分。
2.3、 Any消息
在正常情况下,Leader若可以自由决定一个Value,应该发生一条Phase2a消息,其中包含了选择的Value,但此时却发送了一条无Value的Any消息。Acceptor在接收到Any消息后可做一些开始Fast Round的初始化工作,等待Proposer提交真正的Value。Any消息的意思是Acceptor可以做任意的处理。
因此,一个Fast Round包括两个阶段:由Any消息开始的阶段和由Proposer提交Value的结束阶段,而Leader只是起到一个初始化过程的作用,如果没有错误发生,Leader将退出之后的通信中过程。
下面是Classic Paxos交互图:
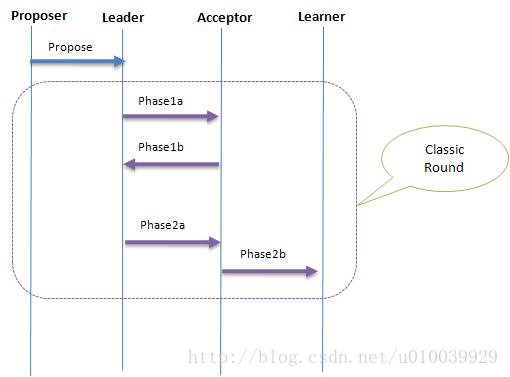
下面是Fast Paxos的交互图:
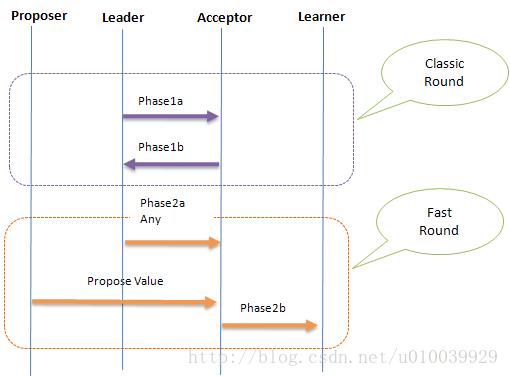
2.4、 冲突
在经典 Paxos中,Acceptor投票的value都是Leader选择好的,所以不存在同一Round中投票多个Value的场景,从而保证了一致性。但在Fast Round中因为允许多个Proposer同时提交不同的Value到Acceptor,这将导致在Fast Round中没有任何value被作为最终决议,这也称为“冲突”(Collision)。
Proposer提交的Round是全序的,不同的Proposer提交的Round肯定不一样,同一Proposer不可能在同一Round中提交不同的Value,那为什么还会有同一Fast Round中有多个Value的情况?原因在于Fast Round与Round区别,当Fast Round开始后,会被分配一个唯一的Round Number,之后无论多少个Proposer提交Value都是基于这个Round Number,而不管Proposer提交的Round是否全序。比如,Fast Round Number为100,Proposer1提交了(101,5),Proposer2提交了(102,10),但对Fast Round来说存在(100,5,10)两个Value。
因为冲突的存在,会导致Phase2a.2的选择非常困难,原因是:
在经典 Paxos中,如果Acceptor返回多个Value,只要排序,选择最高的编号对应的Value即可,因为经典 Paxos中的Value都是有Leader选择后在Phase2a中发送的,因此最高编号的Value肯定只有一个。但在Fast Paxos中,最高编号的Value会发现多个,比如(100,5,10)。假如当前Leader正在执行第i个Classic Round(i-Quorum为Q) ,得到Acceptor反馈的最高编号为k,有两个value:v、w,说明Fast Round k存在两个k-Quorum,Rv,Rw。
O4(v):下面定义在Round k中v或w被选择的条件:
如果v在Round k中被选择,那么存在一个k-Quorum R,使得对任意的Acceptor a∈Q∩R,都对v作出投票。
这个问题也可表述为:R中的所有Acceptor都对v作出投票,并且Q∩R≠φ,因为如果Q∩R=φ,则Round i将无法得知投票结果
因此如果保证下面两个条件:

则v、w不可能同时被选择
2.5、 确定Quorum
根据上面描述,为了防止一次Fast Round选择多个Value,Quorum需要满足下面两个条件:

不妨设总Acceptor数为N,Classic Round运行的最大失败Acceptor数为F,Fast Round允许的失败数为E,即N-F构成Classic Round的一个Quorum,N-E构成Fast Round的一个Quorum。
上面两个条件等价于:

设Qc,Qf分别为Classic和Fast Round的Quorum大小,经过整理可得两个下限结果:

证明请参考:一致性算法中的节点下限
2.6、 冲突Recovery
作为优化,Acceptor在投票Value时也应该发送到Leader,这样Leader就很容易能发现冲突。Leader如果在Round i发现冲突,可以很容易地开始Roun i+1,从Phase1a开始重新执行Classic Paxos过程,但这个其实可以进一步优化,我们首先考虑下面这个事实:
如果Leader重启了Round i+1,并且收到了i-Quorum个Acceptor发送的Phase1b消息,则该消息明确了两件事情:

假如Acceptor a也参与了Round i的投票,则a的Phase1b消息同样明确了上述两件事情,并且会把对应的Round,Value在Phase2b中发送给Leader(当然还有Learner),一旦Acceptor a执行了Phase2b,则也同时表明a将不会再对小于i+1的Round进行投票。
也就是说,Round i的Phase2b与Round i+1的Phase1b有同样的含义,也暗含着如果Leader收到了Round i的Phase2b,则可直接开始Round i+1的Phase2a。经过整理,产生了两种解决冲突(Recovery)的方法:
基于协调者的Recovery
如果Leader在Round i 中收到了(i+1)-Quorum个Acceptor的Phase2b消息,并且发现冲突,则根据O4(v)选取一个value,直接执行Round i+1的Phase2a;否则,从Phase1a开始重新执行Round i+1
基于非协调的Recovery
作为基于协调Recovery的扩展,非协调要求Acceptor把Phase2b消息同时发送给其他Quorum Acceptor,由每个Acceptor直接执行Round i+1的Phase2a,但这要求i-Quorum与(i+1)-Quorum必须相同,并且遵循相同选择value的规则。
这种方式的好处是Acceptor直接执行Round i+1的Phase2a,无需经过Leader,节省了一个通信步骤,缺点是Acceptor同时也作为Proposer,搞的过于复杂。
2.7、 Fast Paxos Progress
至此,再完整地总结下Fast Paxos的Progress:

2.8、 总结
Fast Paxos基本是本着乐观锁的思路:如果存在冲突,则进行补偿。其中Leader起到一个初始化Progress和解决冲突的作用,如果Progress一直执行良好,则Leader将始终不参与一致性过程。因此Fast Paxos理论上只需要2个通信步骤,而Classic Paxos需要3个,但Fast Paxos在解决冲突时有至少需要1个通信步骤,在高并发的场景下,冲突的概率会非常高,冲突解决的成本也会很大。另外,Fast Paxos把Client深度引入算法中,致使其架构远没Classic Paxos那么清晰,也没Classic Paxos容易扩展。
还有一点要注意的是,Fast Quorum的大小比Classic的要大,一般Fast Quorum至少需要4个节点(3E+1),而Classic Paxos需要3个(2F+1)(请参考:一致性算法中的节点下限)。
总之,在我看来Fast Paxos是一个理论上可行,但实际中很难操作的算法,实际中用的比较多的还是Classic Paxos的各种简化形式
Paxos算法在出现竞争的情况下,其收敛速度很慢,甚至可能出现活锁的情况,例如当有三个及三个以上的proposer在发送prepare请求后,很难有一个proposer收到半数以上的回复而不断地执行第一阶段的协议。因此,为了避免竞争,加快收敛的速度,在算法中引入了一个Leader这个角色,在正常情况下同时应该最多只能有一个参与者扮演Leader角色,而其它的参与者则扮演Acceptor的角色,同时所有的人又都扮演Learner的角色。
在这种优化算法中,只有Leader可以提出议案,从而避免了竞争使得算法能够快速地收敛而趋于一致,此时的paxos算法在本质上就退变为两阶段提交协议。但在异常情况下,系统可能会出现多Leader的情况,但这并不会破坏算法对一致性的保证,此时多个Leader都可以提出自己的提案,优化的算法就退化成了原始的paxos算法。
一个Leader的工作流程主要有分为三个阶段:
(1)、学习阶段 向其它的参与者学习自己不知道的数据(决议);
(2)、同步阶段 让绝大多数参与者保持数据(决议)的一致性;
(3)、服务阶段 为客户端服务,提议案;
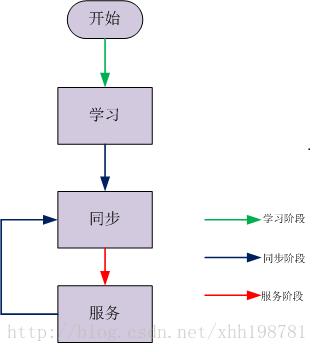
学习阶段
当一个参与者成为了Leader之后,它应该需要知道绝大多数的paxos实例,因此就会马上启动一个主动学习的过程。假设当前的新Leader早就知道了1-134、138和139的paxos实例,那么它会执行135-137和大于139的paxos实例的第一阶段。如果只检测到135和140的paxos实例有确定的值,那它最后就会知道1-135以及138-140的paxos实例。
同步阶段
此时的Leader已经知道了1-135、138-140的paxos实例,那么它就会重新执行1-135的paxos实例,以保证绝大多数参与者在1-135的paxos实例上是保持一致的。至于139-140的paxos实例,它并不马上执行138-140的paxos实例,而是等到在服务阶段填充了136、137的paxos实例之后再执行。这里之所以要填充间隔,是为了避免以后的Leader总是要学习这些间隔中的paxos实例,而这些paxos实例又没有对应的确定值。
服务阶段
Leader将用户的请求转化为对应的paxos实例,当然,它可以并发的执行多个paxos实例,当这个Leader出现异常之后,就很有可能造成paxos实例出现间断。
三 Zookeeper
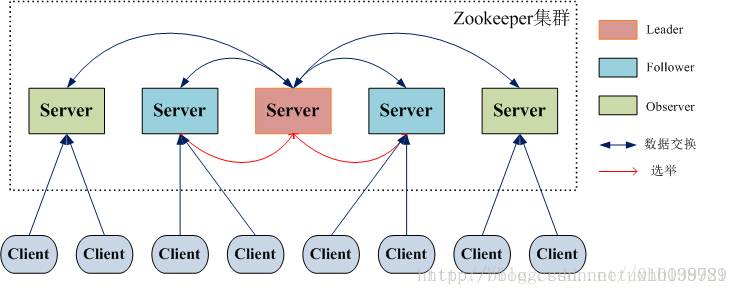
3.1 整体架构
在Zookeeper集群中,主要分为三者角色,而每一个节点同时只能扮演一种角色,这三种角色分别是:
(1). Leader 接受所有Follower的提案请求并统一协调发起提案的投票,负责与所有的Follower进行内部的数据交换(同步);
(2). Follower 直接为客户端服务并参与提案的投票,同时与Leader进行数据交换(同步);
(3). Observer 直接为客户端服务但并不参与提案的投票,同时也与Leader进行数据交换(同步);
3.2 QuorumPeer的基本设计
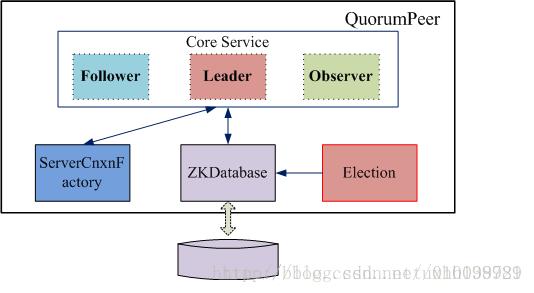
Zookeeper对于每个节点QuorumPeer的设计相当的灵活,QuorumPeer主要包括四个组件:客户端请求接收器(ServerCnxnFactory)、数据引擎(ZKDatabase)、选举器(Election)、核心功能组件(Leader/Follower/Observer)。其中:
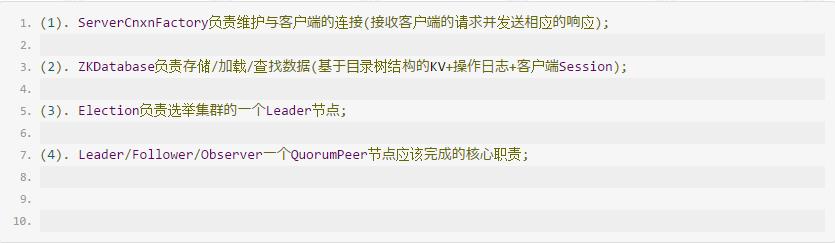
3.3 QuorumPeer工作流程
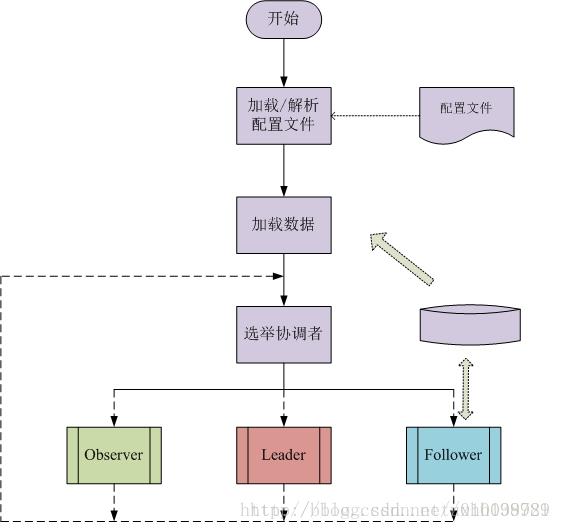
3.3.1 Leader职责
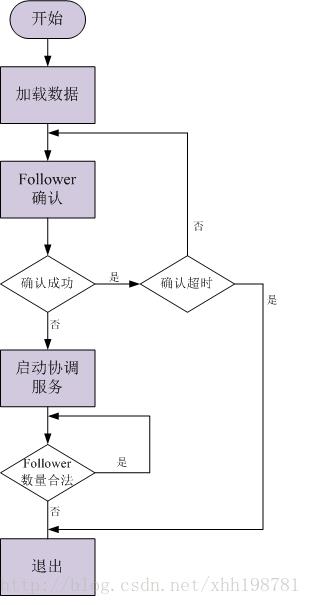
4.4 选举算法
4.4.1 LeaderElection选举算法
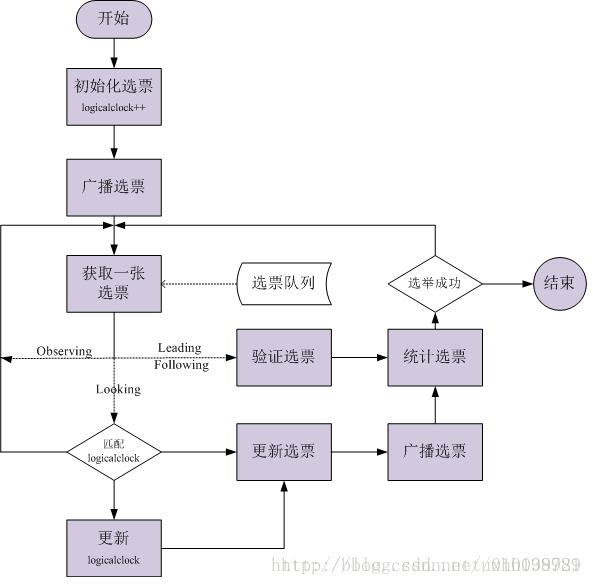
选举线程由当前Server发起选举的线程担任,他主要的功能对投票结果进行统计,并选出推荐的Server。选举线程首先向所有Server发起一次询问(包括自己),被询问方,根据自己当前的状态作相应的回复,选举线程收到回复后,验证是否是自己发起的询问(验证xid 是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader 相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中,当向所有Server
都询问完以后,对统计结果进行筛选并进行统计,计算出当次询问后获胜的是哪一个Server,并将当前zxid最大的Server 设置为当前Server要推荐的Server(有可能是自己,也有可以是其它的Server,根据投票结果而定,但是每一个Server在第一次投票时都会投自己),如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server。根据获胜的Server相关信息设置自己的状态。每一个Server都重复以上流程直到选举出Leader。
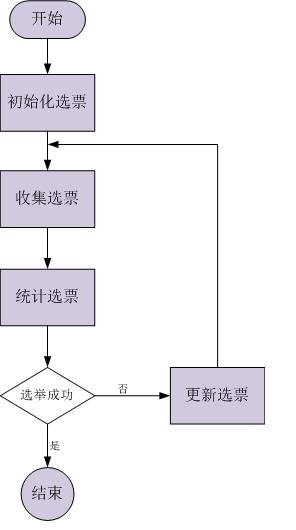
初始化选票(第一张选票): 每个quorum节点一开始都投给自己;
收集选票: 使用UDP协议尽量收集所有quorum节点当前的选票(单线程/同步方式),超时设置200ms;
统计选票:

选举成功: 某一个quorum节点的票数超过半数;
更新选票: 在本轮选举失败的情况下,当前quorum节点会从收集的选票中选取合适的选票(zxid、myid均最大)作为自己下一轮选举的投票;
异常问题的处理
1). 选举过程中,Server的加入
当一个Server启动时它都会发起一次选举,此时由选举线程发起相关流程,那么每个 Serve r都会获得当前zxi d最大的哪个Serve r是谁,如果当次最大的Serve r没有获得n/2+1 个票数,那么下一次投票时,他将向zxid最大的Server投票,重复以上流程,最后一定能选举出一个Leader。
2). 选举过程中,Server的退出
只要保证n/2+1个Server存活就没有任何问题,如果少于n/2+1个Server 存活就没办法选出Leader。
3). 选举过程中,Leader死亡
当选举出Leader以后,此时每个Server应该是什么状态(FLLOWING)都已经确定,此时由于Leader已经死亡我们就不管它,其它的Fllower按正常的流程继续下去,当完成这个流程以后,所有的Fllower都会向Leader发送Ping消息,如果无法ping通,就改变自己的状为(FLLOWING ==> LOOKING),发起新的一轮选举。
4). 选举完成以后,Leader死亡
处理过程同上。
5). 双主问题
Leader的选举是保证只产生一个公认的Leader的,而且Follower重新选举与旧Leader恢复并退出基本上是同时发生的,当Follower无法ping同Leader时就认为Leader已经出问题开始重新选举,Leader收到Follower的ping没有达到半数以上则要退出Leader重新选举。
4.4.2 FastLeaderElection选举算法
FastLeaderElection是标准的fast paxos的实现,它首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决 epoch 和 zxid 的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息。
FastLeaderElection算法通过异步的通信方式来收集其它节点的选票,同时在分析选票时又根据投票者的当前状态来作不同的处理,以加快Leader的选举进程。
每个Server都一个接收线程池和一个发送线程池, 在没有发起选举时,这两个线程池处于阻塞状态,直到有消息到来时才解除阻塞并处理消息,同时每个Serve r都有一个选举线程(可以发起选举的线程担任)。
1). 主动发起选举端(选举线程)的处理
首先自己的 logicalclock加1,然后生成notification消息,并将消息放入发送队列中, 系统中配置有几个Server就生成几条消息,保证每个Server都能收到此消息,如果当前Server 的状态是LOOKING就一直循环检查接收队列是否有消息,如果有消息,根据消息中对方的状态进行相应的处理。
2).主动发送消息端(发送线程池)的处理
将要发送的消息由Notification消息转换成ToSend消息,然后发送对方,并等待对方的回复。
3). 被动接收消息端(接收线程池)的处理
将收到的消息转换成Notification消息放入接收队列中,如果对方Server的epoch小于logicalclock则向其发送一个消息(让其更新epoch);如果对方Server处于Looking状态,自己则处于Following或Leading状态,则也发送一个消息(当前Leader已产生,让其尽快收敛)。
4.4.3 AuthFastLeaderElection选举算法
AuthFastLeaderElection算法同FastLeaderElection算法基本一致,只是在消息中加入了认证信息,该算法在最新的Zookeeper中也建议弃用。
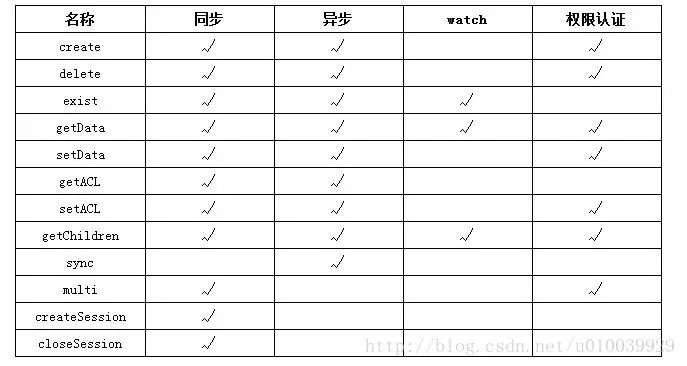
5.5 Zookeeper的API
5.6 Zookeeper中的请求处理流程
5.6.1 Follower节点处理用户的读写请求
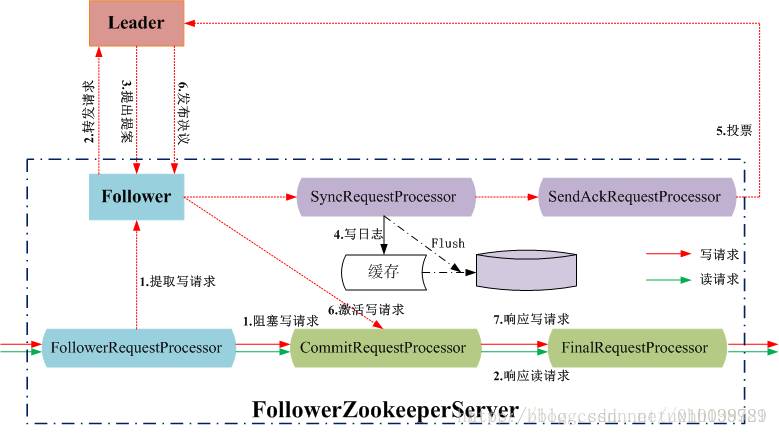
5.6.2 Leader节点处理写请求
值得注意的是, Follower/Leader上的读操作时并行的,读写操作是串行的,当CommitRequestProcessor处理一个写请求时,会阻塞之后所有的读写请求。
以上是关于干货丨从Paxos到Fast Paxos达Zookeeper分析的主要内容,如果未能解决你的问题,请参考以下文章