共识机制演绎: paxos, 从入门到raft
Posted Unitimes
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了共识机制演绎: paxos, 从入门到raft相关的知识,希望对你有一定的参考价值。
unitimes.media
全球视角,独到见解
“几经挣扎过后,我们终于想出了一种全新的共识算法。”

在paxos已经实现工业化的十个年头,我们依旧鲜见关于paxos的开源代码。其原因不仅仅是因为paxos的理论异常晦涩,其实践之路也异常艰难。
当来自Google Chubby的Mike Burrows将Paxos称赞为世上唯一一致性算法时,也毫不隐讳“Chubby作为Paxos实现曾经遭遇到很多坑”。而Google在其论文《Paxos Made Live》1更是直言:“Paxos从理论到现实世界的实现之间有巨大的鸿沟,在真正实现一个Paxos的时候,往往需要对Paxos的经典理论做一些扩展,这往往会导致真正的Paxos实现其实都是基于一个未被完全证明的协议。”
2013年,两位来自斯坦福的教授发表了题为《寻找一种易于理解的算法(In Search of an Understandable Consensus Algorithm)》2的论文,文章开宗明义:

“Paxos难懂不说,还不好实现。搞工程不好搞,教书也教不懂。几经挣扎过后,我们终于想出了一种全新的共识算法。”
那就是raft。
相比起paxos,raft强化了两个概念。第一,是领导者的概念。raft算法主要以领导者的意志为核心展开共识过程。这一思想极大地简化了共识节点沟通的流程,同时也保证了算法的高效性。第二,是可读性的概念。
在raft算法中,每个节点共有三种状态:追随者(Follower)、候选者(Candidate)和领导者(Leader)。在系统的初始,每一个节点都处于追随者的状态,简单地说,此时的节点只能被动地接收信息,没有提出决策的能力。此外,每一个节点都有一个随机的计时器(在150ms~300ms之间)。前面提到过,raft强调领导者的概念,这意味着在正常的情况下,节点里面必然会出现一个领导者不断地推进大多数追随者达成共识,并执行命令。
那么如何界定领导者存在呢?由此,我们规定每一位在位的领导者不管在多事之秋,还是闲暇的季节都要定期向它的追随者们发送心跳(HeartBeat)以证明自己还活着——这些心跳会不断地重置追随者的计时器,而一旦追随者的计时器发生超时,意味着这时节点里面可能没有领导者。因此,处于追随者状态的节点就会转换成为候选者,先给自己投一票,紧接着向其它节点拉票,请求它们推举自己成为领导者。
不管在paxos还是raft中,投票的最终结果都要遵从“少数服从多数”。这一约定避免了即使在由偶数个节点组成的网络中,有多个候选者势均力敌时,网络中也不会同时出现多个领导者。我们再来考虑另外一种情况:如果网络发生了故障,节点被迫分成了互不联系的小团体(即网络分区),情况会是怎样。
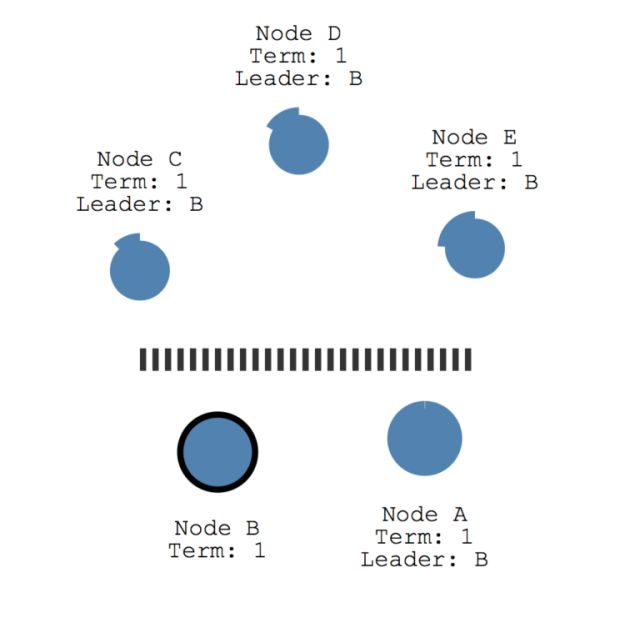
图1 网络分区
(其中,节点A,B能够联系;节点C,D,E能够联系)
来源:http://thesecretlivesofdata.com/raft/
此时,如果节点A投票推举节点B为领导者,节点D和E推举节点C为领导者,那么系统内将同时存在有B和C两位领导者。但是,依据“少数服从多数”的原则,节点C获得了大多数票(包括它自己的)。由此,节点C才是名副其实的领导者。无论在网络分区过程中节点A,B之间达成了什么共识,在网络恢复正常后,其状态依旧要进行回滚并与节点C,D,E保持一致。
这就是领导者选举(Leader Election)的简要过程。
那么领导者与追随者间的共识如何达成呢?
当领导者接收到来自客户端的请求时,它会把这条请求写进自己的日志条目中,比如“张三,今天想吃葡萄”,并把请求发给追随者们,让大家都把这件事情记上。如果大多数追随者都完成了记录,领导者也会收到相应的反馈。此时,它会认为这条记录“被提交了(committed)”。此后,这条记录将被执行(允许张三吃葡萄),执行结果将由领导者反馈给客户端。
但是,这里面也有一个问题,如果追随者的记录跟领导者的记录发生冲突,该怎样处理呢?举个例子,在上文中领导者记录了“张三,今天想吃葡萄”。事实上,在领导者的日志中还记载着张三前天、昨天分别吃了草莓和香蕉,但在另一追随者的记录中,张三却已经连续吃了三天葡萄。此时,我们规定,一切以领导者的日志条目为准。也就是说,领导者的日志将会覆盖掉冲突的追随者的日志。
为了使得追随者的日志与自己保持一致,领导者需要找到追随者与它的日志一致的地方,然后删除掉追随者在该位置之后的所有条目,并将自己在该位置之后的条目发送给追随者。至于如何找到这个一致的临界点,文中提出:领导者会给追随者一个位置编号,这个编号通常是自己下一个日志条目的编号,比如11号。如果追随者的日志与领导者不一致,它将反馈给领导者。这时,领导者会把编号逐步递减,比如10号,再发送给追随者,直到找到日志一致的位置。当然,我们还可以让追随者直接以某种方式告知领导者冲突的大致位置,以加快编号递减的速度。通过这种机制,领导者便能够保证大多数追随者的状态总是与自身一致的。
在上述过程中,节点的数量是不变的。然而,在实际应用中,可能会出于服务器升级替换等种种原因导致网络的节点数量发生变化。为此,raft提出了集群成员的管理方法。
我们假设,网络中原有3个节点,此时需要再加上2个节点。这时可能导致网络内同时出现两个领导者(想象一下,假设旧配置的3个节点A,B,C的领导者为节点A,此时节点A收到了更改旧配置为新配置的信息,那就意味着新配置的节点A,D,E中也会诞生一个领导者)。为此,作者提出了“联合一致(joint consensus)“的方式来保证顺利升级。所谓“联合一致”,就是通过使用一个过渡状态,来完成共识从“旧配置(Cold)—>过渡状态(Cold,new)—>新配置(Cnew)”的转换。
首先,领导者收到从Cold切换到Cnew配置的请求,此时它将创建配置日志Cold,new,并且这条日志需要在Cold和Cnew两边同时获得大多数节点的支持。一旦Cold,new日志达到“被提交了”状态,那么无论是Cold还是Cnew都无法单独形成多数派,由此避免产生两个领导者的窘境。
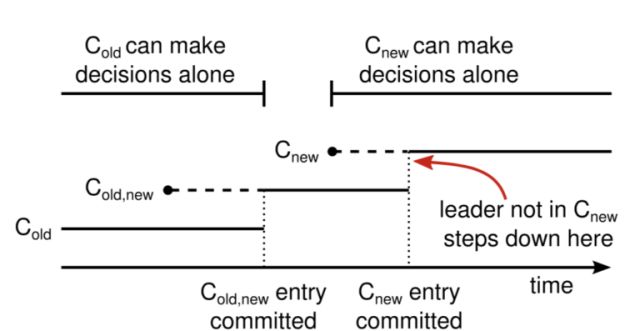
图2 新旧配置共识转移过程
紧接着,领导者将创建配置日志Cnew,并广播到所有节点。当Cnew配置日志达到“被提交了”状态后,则Cnew顺利成为了多数派,新旧配置转换顺利完成。
最后,我们简要谈谈raft日志的管理问题。
我们都知道,随着时间的增长,服务器内存储的日志会越来越多,这些文件将占据大量的内存,由此造成空间浪费。在raft中,每个服务器每隔一段时间将独立地创建快照。当然,快照的内容只包含已经处于“被提交了”状态的日志。如图3所示,在日志条目1~5中,服务器最终完成了“x <—0,y<—9”的状态转换。为此,在记录下这一状态以后,服务器就可以把日志条目1~5以及在条目5之前的快照删除了。
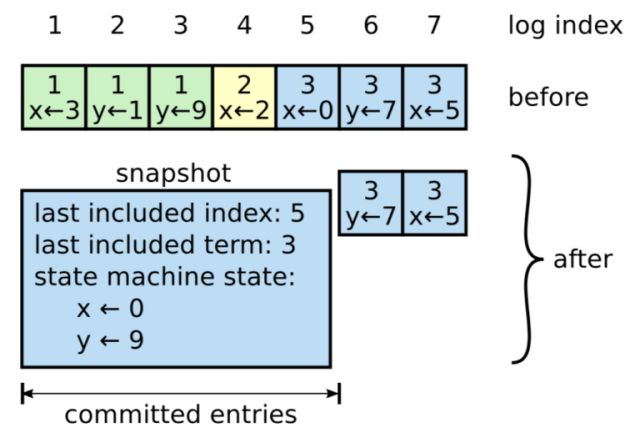
图3 服务器在日志条目5进行快照
至此,raft算法的介绍就到此完成了。如果想要了解更多有关raft算法的工程实现,可以浏览https://raft.github.io。
raft算法尽管在工程实现以及可读性上大获成功,但也受限于其无法进行拜占庭容错的缺陷。下一节,我们将接着拜占庭将军问题,谈谈paxos算法的拜占庭化。
参考文献
[1] T.Chandra, R.Griesemer, J.Redstone. Paxos Made Live: An Engineering Perspective[J]// Proceedings of Annual Acm Symposium on Principles of Distributed Computing,2007:398-407
[2] Diego Ongaro, John Ousterhout. In Search of an Understandable Consensus Algorithm (Extended Version)[EB/OL]//https://raft.github.io/raft.pdf, 2013
国际金融科技新媒体和社区平台
UNITIMES
网址 : unitimes.media
新浪微博:@Unitimes
以上是关于共识机制演绎: paxos, 从入门到raft的主要内容,如果未能解决你的问题,请参考以下文章