分布式共识算法-Raft算法
Posted Lord Lean Notes
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式共识算法-Raft算法相关的知识,希望对你有一定的参考价值。
raft引入了几个新颖的特性:强领导、领导人选举、成员变更。
raft使用更强的领导形式。例如,日志条目仅从引导者流向其他服务器。这简化了复制日志的管理,并使raft更易于理解。
raft使用随机定时器来选举领导人,这只是为任何共识算法所需的心跳增加了少量机制,同时简单而快速的解决冲突。
成员资格更改
确保在所有非拜占庭条件下(包括网络延迟、分区、数据包丢失、重复和重新排序)的安全性(从不返回错误的结果)
只要大多数服务器处于运行状态,并且可以互相通信,就是完全可用的。例如:五台服务器可以容忍两台服务器的故障。如果出现故障,会在稳定存储状态下恢复,然后重新加入集群。
不依赖于时间来确保日志的一致性,但是在错误的时钟和极端的消息延迟在最坏的情况下会导致可用性问题。
一个命令可以在大多数集群响应了一轮远程调用之后立即完成,少数慢速服务器不影响整个系统性能。
Paxos怎么了?
图1:这是raft算法中涉及到的状态、角色和属性
raft集群可以在包含5台服务器时,容许2台服务器的故障。在任何时候,每个服务器都属于三种状态之一:追随者、候选人、领导者。在正常运行中,只有一个领导者,其他所有服务器都是追随者。追随者是被动的:其不会自己发出请求,只是回应领导者和候选人的请求。领导者处理所有的客户请求(如果一个客户联系了一个追随者,追随者会将其重定向到领导者)第三种状态,候选人,被用来选举一个新的领导者。图2显示了状态的转换。
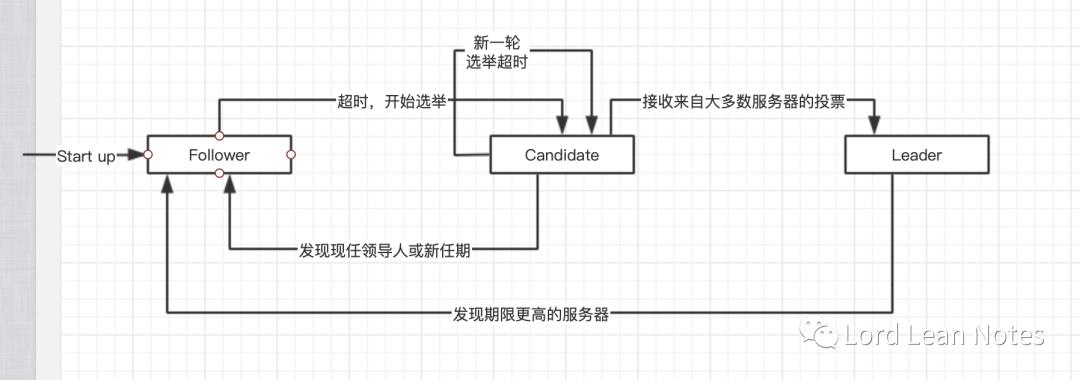
图2:服务器状态的转换
raft将时间划分为任意长度,每一项任期用连续的整数编号,每个任期都以一次选举开始,在这次选举中会有一个或多个候选人试图成为领导者。当一个赢得了选举,就会成为剩余任期的领导者。在某些情况下,选举会导致分裂投票。这种情况下任期会很快结束,新的任期会很快开始,raft会确保在新的任期内只有一个领导者。图3显示了每个时间段任期的状态。
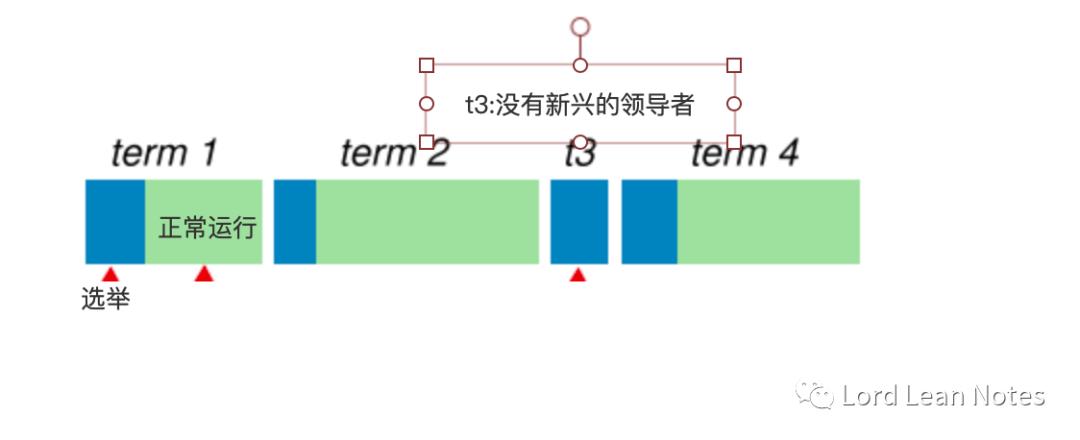
图3:时间段任期的状态
不同的服务器可能会在不同的时间观察任期的转换,任期在raft中充当逻辑时钟,其允许服务器检测过时的信息。每个服务器都会存储当前任期的编号,并随着时间的推移来增加,当前任期会在服务器通信时进行交换。如果一个服务器的当前任期比另一个服务器的当前任期小,就更新为最大的任期。如果一个候选人或者领导者发现其任期已经过期,会恢复到追随者的状态。如果服务器接收到了一个带有过期编号的请求,会拒绝该请求。
raft使用心跳机制来触发领袖选举。当服务器启动时,它们作为追随者开始。只要服务器接收到来自领导者或候选人的有效RPC,它就会保持在跟随者状态。领导者定期发送心跳到跟随者,以维护其权威。如果跟随者在称为选举超时的一段时间内没有收到任何通信。追随者就会假定没有可存活的领导人,并开始选举新的领导人。
追随者会递增自己的任期成为候选人,然后发布投票请求到其他的服务器。直到其赢得选举、另一个服务器确定了自己的领导地位或者在一段时间内没有选出领导者,才会退出候选人的状态。
候选人在同一任期内获得大多数服务器的投票后将会赢得选举。在给定的任期内,每个服务器会按先到先得的原则投票给最多一名候选人,多数票规则可以确保最多只有一名候选人成为某一任期的领导者。然后会向所有的服务器发送心跳信息,建立自己的权威,并阻止新的选举。
在等待投票时,候选人可能收到另一台声称是领导者的rpc请求,领导者的任期至少要与候选人的任期一样,候选人才会承认其是合法的,并且退回追随者的状态。如果小于候选人的任期,那么则拒绝该请求。
如果出现多名候选人的情况,即选票可能被分割。每个候选人会超时,并且开启一次新的选举。(注:如果没有额外措施,是有可能出现无限的分裂投票)
当选出领导者后,便开始服务于客户端的请求,每个客户端请求都包含一个由复制状态机执行的命令。领导者将该命令作为一个新的一条记录写入到日志中,然后同步复制到其他服务器。当记录已安全复制到其他服务器时,就将该记录应用到领导者的状态机,并将执行结果返回给客户机。如果追随者崩溃或网络缓慢,领导者将无限重试,直至追随着最终存储所有记录。图4显示了raft的日志格式。
图4raft的日志格式
日志中是以key-value的形式进行存储,里面存储着领导者接收记录时的任期编号,任期编号用来检测日志之间的不一致,以此来确保raft的一些属性(可以查看图1中正确的属性)。整数索引用来标识在日志中的位置。
领导者决定何时将日志记录写入日志中,这样的记录被称为commit-ted。Raft保证提交的记录是持久的,并最终会被所有的服务器所记录。如果创建记录的领导者在大多数服务器上同步了该记录,则会提交一个日志记录(包括领导者日志中所有的记录,包括之前领导者创建的记录)。
Raft的日志机制保证了在不同服务器上日志之间的高度一致,其一是在给定的任期中使用给定的日志索引最多创建一个条目,并且在日志中不会发生修改。其二是会通过一个RPC请求来执行日志记录的一致性检查,领导者会在请求中加入新记录的上一条记录的索引和任期。如果追随者者中找不到相同索引和任期的记录,则将新的记录合并到自己的日志中。如果一致则追加到追随者的日志中。Raft协议正是这样来保证图1中的日志匹配属性在任何属性都是真实正确的。
在正常操作期间,领导者和追随者的日志保持高度一致,然而领导者的崩溃会导致日志不一致的情况出现。比如下图:
在上图中出现了追随者缺少领导者上的记录、追随者上有的记录领导者中没有或者两种情况都存在,而且日志中缺失的记录可能是跨越多个任期的,Raft通过下面的方式来解决追随者的冲突记录。
在Raft中,领导者通过强制追随者的日志同步自己的日志来处理不一致性。领导者中会为每个跟随者维护一个nextIndex,当领导者第一次掌权时,会初始化这个值,并将其值初始化为其日志最后一个索引的下一个索引的值。如果追随者和领导者的日志不一致,则会遍历的方式来和追随者的nextIndex来进行比对,若不相等,领导者的nextIndex则-1,然后往复循环,直到nextIndex相等为止。随之将追随者相同日志记录之后的记录删除并将领导者的日志记录同步过去。一旦日志同步成功,跟随者和领导者的日志会在任期内保持一致。
有了这种机制,领导者可以不采取任何恢复行动来保证日志的一致性。并且Raft可以接受、复制和应用新的日志记录,在正常情况下,一个新的记录可以通过一次rpc请求来完成复制,并且不会应某个追随者的缓慢而导致性能缓慢。
以上是关于分布式共识算法-Raft算法的主要内容,如果未能解决你的问题,请参考以下文章