基于深度多任务学习的自然语言处理技术
Posted 数据大家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于深度多任务学习的自然语言处理技术相关的知识,希望对你有一定的参考价值。
引言
统计自然语言处理系统依赖于标注数据,对一些较为复杂的任务,如句法、语义分析等,由于存在标注难度及代价较高、标注一致性差等问题,使得大规模的标注数据往往不易获取。然而与其它人工智能问题不同,自然语言处理往往存在多种语言、多种标注规范以及多种任务的标注数据,深度多任务学习框架可以充分地利用这些数据有效提升自然语言处理的分析精度。本文以多语言多标注规范依存句法树库融合为例,介绍深度多任务学习在自然语言处理中的应用,并希望对其它类似的问题产生一定的借鉴作用。
1. 多任务学习
机器学习方法为解决自然语言处理所面临的歧义性、动态性和非规范性问题提供了一种可行的解决方案。其中,有监督学习(Supervised Learning)的方法利用人工标注的训练数据进行学习,在大多数自然语言处理任务中取得了令人满意的结果。同时,也应注意到,对于自然语言处理中一些较为复杂的任务,如句法、语义分析等,由于存在标注难度及代价较高、标注一致性差等问题,使得大规模的标注数据往往不易获取,这也为有监督学习带来了困难。
针对这个难题,人们沿着不同的研究路线进行了探索,如从未标注数据中进行无监督学习(Unsupervised Learning),融合有标注和未标注数据的半监督学习(Semi-supervised Learning)等。近年来兴起的多任务学习(Multi-task Learning)技术为解决自然语言处理任务标注数据不足,提高自然语言处理系统的准确率提供了一种新的解决方案。
多任务学习是一种归纳迁移机制,基本目标是提高泛化性能。多任务学习通过相关任务训练信号中的领域特定信息来提高泛化能力,利用共享表示采用并行训练的方法学习多个任务。多任务学习的基本假设是多个任务之间具有相关性,因此能够利用这种相关性互相促进。
2. 自然语言处理的特点
目前,多任务学习常被应用于图像、视觉等领域。然而,与这些领域不同,自然语言处理具有一定的特殊性。首先,自然语言处理包括词法、句法、语义分析等多种任务,这些任务表面上看各不相同,但是之间同样存在紧密的内在联系,在一个任务上的良好表现对于其在相关任务上的泛化能力有很大的促进作用,因此我们可以很自然的将多任务学习应用于这些任务,以提升各个任务的分析精度。
其次,由于自然语言所具有的复杂性,很多具体任务的数据标注规范并不统一。例如,中文分词任务中不同数据集的标注粒度不尽相同。然而,尽管标注规范存在差异,这些数据所蕴含的语言知识却有较强的共性,存在互补的可能,所以还可以将不同标注规范的数据看做不同的任务,应用多任务学习提升它们各自的分析精度。
最后,世界上存在多种语言,虽然各种语言的词汇甚至语法结构等都不尽相同,但是既然语言都是表达人类思想的工具,它们之间也存在一定的共性。因此我们可以将不同语言看作不同的任务,利用多任务学习机制,使它们互相帮助以提高各自的分析精度。
3. 深度多任务学习
一直以来,由于传统自然语言处理技术所采用的离散形式的符号化特征表示以及浅层学习模型所带来的限制,很难使用统一且有效的方法进行多任务、多标注规范以及多语言的学习。人们往往针对不同的处理对象,提出不同的学习方法,如我们之前所提出的分词、词性标注、句法分析联合模型以及多句法分析树库融合模型等,虽然一定程度上也能利用多个任务或多种类型的数据资源提高系统的准确率,但是这些方法很难被推广到更多的自然语言处理任务中。
近年来,随着深度学习技术的发展,研究者们开始普遍认识到其对于自然语言处理的重要性。所谓深度学习,一般是指建立在含有多层非线性变换的神经网络结构之上,对数据的表示进行抽象和学习的一系列机器学习算法。深度学习强大的表示能力,为多任务学习带来了新的技术思路,两者的结合便产生了深度多任务学习的新方法。在深度多任务学习中,共享表示层可以使得几个有共性的任务更好的结合相关性信息,任务特定层则可以单独建模任务特定的信息,实现共享信息和任务特定信息的统一。
本文以多语言多标注规范依存句法树库融合为例,介绍深度多任务学习在自然语言处理中的应用,希望对其它类似的问题产生一定的借鉴作用。
4. 多语言多标注规范依存句法树库融合[1]
依存句法树库的标注(也包括其它自然语言处理任务)不仅对专家知识的要求较高,而且对于语法较为自由的语言(如中文)而言,标注的一致性较低。这也在很大程度上限制了很多语言上句法树库的规模。另一方面,依存句法的标注规范近10年来也在不断地演变,从早期只反映句法关系的依存结构到近几年逐渐成为主流的偏语义的依存结构,从而导致很多语言中存在不同标注规范的依存树库,这类树库通常称为异构树库(Heterogeneous Treebanks)。
树库融合的挑战主要在于多种树库之间在句法结构上的差异,这种差异在不同类型的源树库上又有所不同。对于多语言树库,其不一致性主要是由不同语言之间类型学(typology)特征的不同所导致的,如德语、英语之间的动宾结构差异(图1)。对于单语异构树库,不一致性则主要体现在标注规范的差异。对于依存句法分析而言,则具体反映在核心结点的选择以及依存关系的定义。比如在CoNLL依存体系中,往往是以功能词(functional words)作为核心结点,同时依存关系的定义也是以句法为主,语义粒度较粗;而在Stanford依存体系以及通用依存体系中,则主要以内容词(content words)作为核心结点,其依存关系集粒度较细,深入到了语义层面。
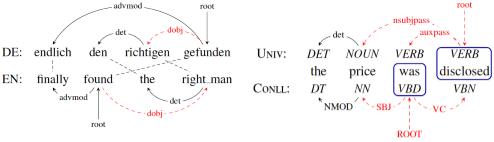
图1: 多语依存结构(左图)以及单语异构依存结构(右图)
尽管不同树库之间存在不一致性,但也有相当一部分结构是一致的。我们期望从这些一致的结构中充分萃取知识,而尽量规避那些不一致性所带来的影响。我们采用的深度多任务学习框架,将每种树库下的学习过程视作一个单独的任务,并通过分布表示层面上的参数共享来控制不同任务之间的信息交互。
我们采用基于转移的依存句法分析方法,其中最关键的因素是对于每个转移状态的表示。每个转移状态通常可以表示为由一个栈(S)、一个缓存(B)以及当前已经生成的依存弧集合(A)所构成的三元组。传统的依存句法分析模型通过人工定义的大量特征模板从该三元组中抽取特征,一般为指定位置(如:栈顶,缓存顶等)的某种属性(如:词,词性等)或者组合。这种依赖“特征工程”的方式表达能力有限,对转移状态的表达并不充分。
我们采用基于长短时记忆网络(LSTM)的依存句法分析模型,并使用基于字的双向LSTM对词表示进行建模。采用该结构的原因如下:
· 与传统的模型相比,该模型使用LSTM以及递归神经网络对当前转移状态的各个组成部分(栈、缓存、历史转移序列,以及当前依存子树集合)进行全局的编码,充分利用了历史转移信息。
· 通过对词、栈、缓存、转移序列等部分细粒度地建模,使得在多任务学习框架中能够更加灵活地控制参数共享。图2展示了模型的具体结构。
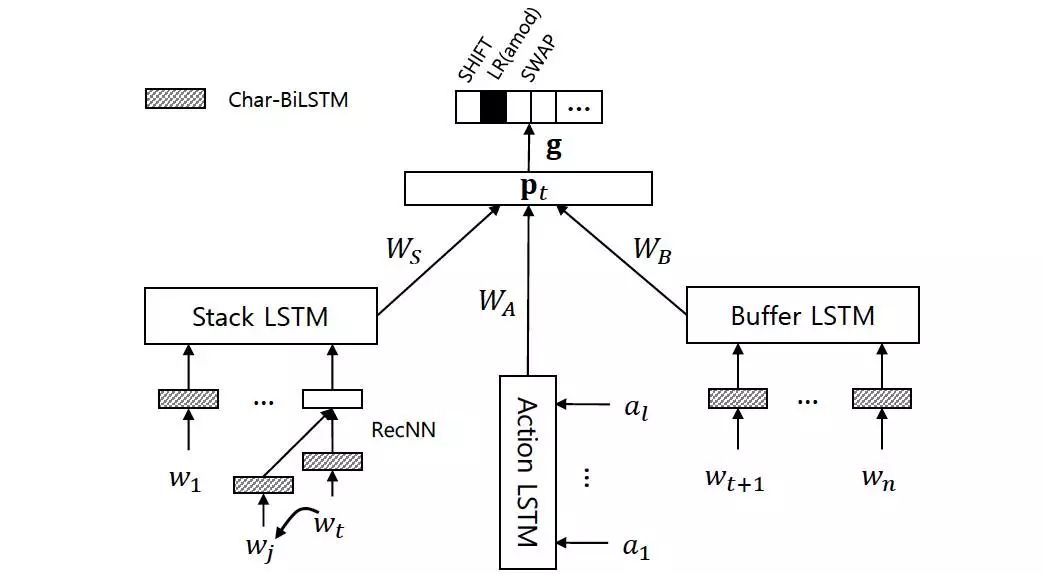
图2:基于LSTM的依存句法分析模型结构
我们将每种树库的学习过程视为一个单独的任务,对应的深度多任务学习框架如图2所示。通过参数共享机制,实现不同树库学习时的信息交互,以提升目标树库上的分析性能。
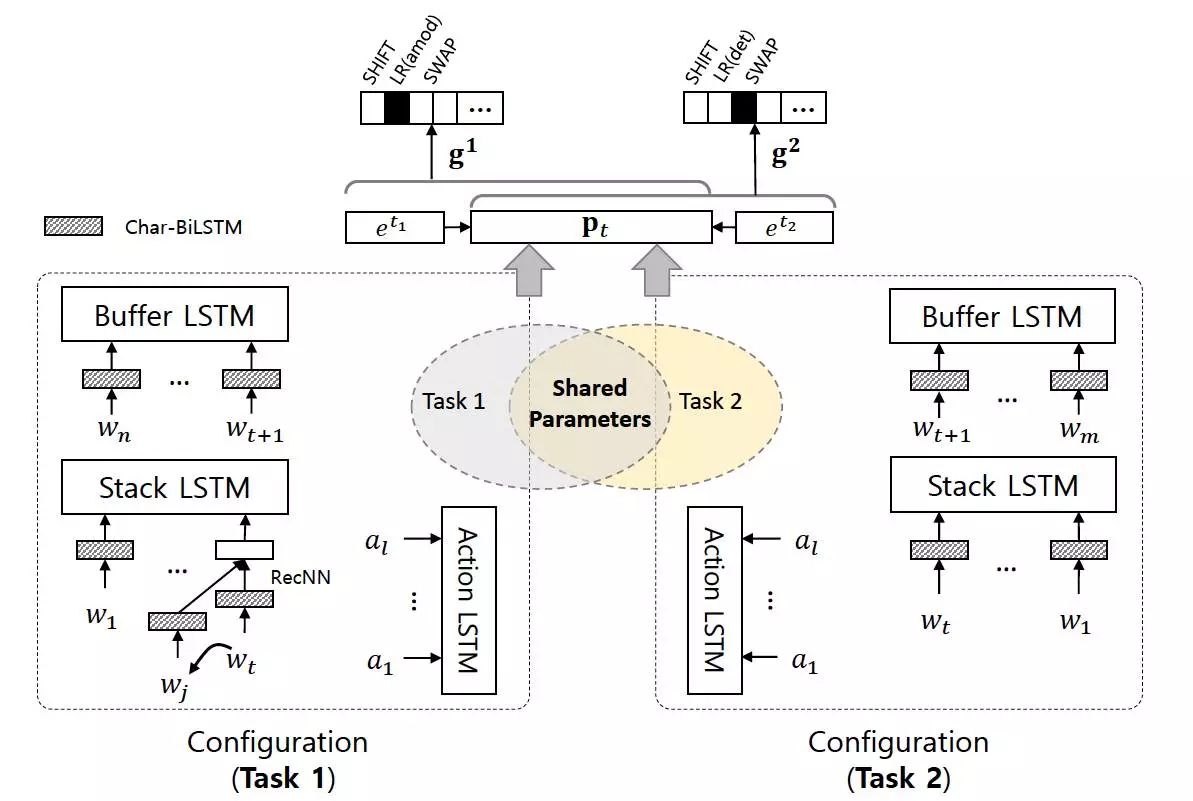
图3:基于深度多任务学习的树库融合框架
具体训练过程如下:
1. 随机选择一个任务;
2. 从该任务(所对应的树库)中随机选择一个句子,并构建用于学习分类器的训练实例;
3. 根据这些训练实例,利用反向传播计算相应参数的梯度,并更新参数;
4. 返回第1步。
最后,我们在多种语言、多种设置下进行了相关的实验,并与传统的有监督学习系统以及级联学习系统进行了对比。实验结果表明,我们的框架在绝大多数情况下能够取得比基准系统更优的性能,证明了深度多任务学习在树库融合上的有效性。
5. 结语
深度多任务学习框架可以充分地利用多种任务、多种标注规范以及多种语言的标注数据,有效防止学习模型过拟合于特定任务或者特定数据,增强系统的泛化能力,从而提升自然语言处理的分析精度。本文以多语言多标注规范依存句法树库融合为例,介绍了深度多任务学习在自然语言处理中的应用,对其它类似的问题具有一定的借鉴作用。
References
[1]相关工作发表于:Jiang Guo, Wanxiang Che, Haifeng Wang and Ting Liu. A Universal Framework for InductiveTransfer Parsing across Multi-typed Treebanks. COLING 2016.
本期责任编辑: 丁效
本期编辑: 施晓明

数据大家:汇聚众人智慧,成就一代大家!
以上是关于基于深度多任务学习的自然语言处理技术的主要内容,如果未能解决你的问题,请参考以下文章
Pythia:Facebook最新开源的视觉语言多任务学习框架