Pytorch创建多任务学习模型
Posted deephub
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch创建多任务学习模型相关的知识,希望对你有一定的参考价值。
在机器学习中,我们通常致力于针对单个任务,也就是优化单个指标。但是多任务学习(MTL)在机器学习的许多应用中都取得了成功,从自然语言处理和语音识别到计算机视觉和药物发现。
MTL最著名的例子可能是特斯拉的自动驾驶系统。在自动驾驶中需要同时处理大量任务,如物体检测、深度估计、3D重建、视频分析、跟踪等,你可能认为需要10个以上的深度学习模型,但事实并非如此。
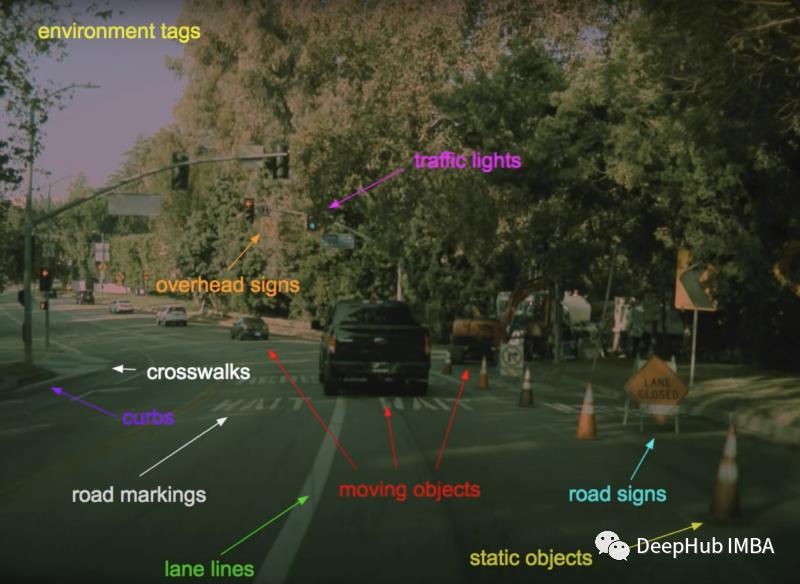
HydraNet介绍
一般来说多任务学的模型架构非常简单:一个骨干网络作为特征的提取,然后针对不同的任务创建多个头。利用单一模型解决多个任务。

上图可以看到,特征提取模型提取图像特征。输出最后被分割成多个头,每个头负责一个特定的情况,由于它们彼此独立可以单独进行微调!
特斯拉的讲演中详细的说明这个模型(youtube:v=3SypMvnQT_s)
多任务学习项目
在本文中,我们将介绍如何在Pytorch中实现一个更简单的HydraNet。这里将使用UTK Face数据集,这是一个带有3个标签(性别、种族、年龄)的分类数据集。
我们的HydraNet将有三个独立的头,它们都是不同的,因为年龄的预测是一个回归任务,种族的预测是一个多类分类问题,性别的预测是一个二元分类任务。
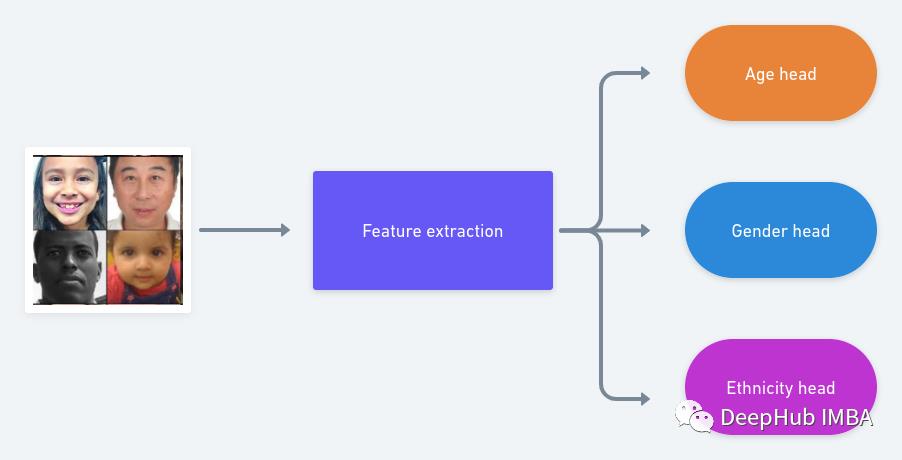
每一个Pytorch 的深度学习的项目都应该从定义Dataset和DataLoader开始。
在这个数据集中,通过图像的名称定义了这些标签,例如UTKFace/30_0_3_20170117145159065.jpg.chip.jpg
- 30岁是年龄
- 0为性别(0:男性,1:女性)
- 3是种族(0:白人,1:黑人,2:亚洲人,3:印度人,4:其他)
所以我们的自定义Dataset可以这样写:
class UTKFace(Dataset):
def __init__(self, image_paths):
self.transform = transforms.Compose([transforms.Resize((32, 32)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
self.image_paths = image_paths
self.images = []
self.ages = []
self.genders = []
self.races = []
for path in image_paths:
filename = path[8:].split("_")
if len(filename)==4:
self.images.append(path)
self.ages.append(int(filename[0]))
self.genders.append(int(filename[1]))
self.races.append(int(filename[2]))
def __len__(self):
return len(self.images)
def __getitem__(self, index):
img = Image.open(self.images[index]).convert('RGB')
img = self.transform(img)
age = self.ages[index]
gender = self.genders[index]
eth = self.races[index]
sample = 'image':img, 'age': age, 'gender': gender, 'ethnicity':eth
return sample
简单的做个介绍:
__init__
方法初始化我们的自定义数据集,负责初始化各种转换和从图像路径中提取标签。
__get_item__
将:它将加载一张图像,应用必要的转换,获取标签,并返回数据集的一个元素,也就是说这个方法会返回数据集中的单条数据(单个样本)
然后我们定义dataloader
train_dataloader = DataLoader(UTKFace(train_dataset), shuffle=True, batch_size=BATCH_SIZE)
val_dataloader = DataLoader(UTKFace(valid_dataset), shuffle=False, batch_size=BATCH_SIZE)
下面我们定义模型,这里使用一个预训练的模型作为骨干,然后创建3个头。分别代表年龄,性别和种族。
class HydraNet(nn.Module):
def __init__(self):
super().__init__()
self.net = models.resnet18(pretrained=True)
self.n_features = self.net.fc.in_features
self.net.fc = nn.Identity()
self.net.fc1 = nn.Sequential(OrderedDict(
[('linear', nn.Linear(self.n_features,self.n_features)),
('relu1', nn.ReLU()),
('final', nn.Linear(self.n_features, 1))]))
self.net.fc2 = nn.Sequential(OrderedDict(
[('linear', nn.Linear(self.n_features,self.n_features)),
('relu1', nn.ReLU()),
('final', nn.Linear(self.n_features, 1))]))
self.net.fc3 = nn.Sequential(OrderedDict(
[('linear', nn.Linear(self.n_features,self.n_features)),
('relu1', nn.ReLU()),
('final', nn.Linear(self.n_features, 5))]))
def forward(self, x):
age_head = self.net.fc1(self.net(x))
gender_head = self.net.fc2(self.net(x))
ethnicity_head = self.net.fc3(self.net(x))
return age_head, gender_head, ethnicity_head
forward方法返回每个头的结果。
损失作为优化的基础时十分重要的,因为它将会影响到模型的性能,我们能想到的最简单的事就是地把损失相加:
L = L1 + L2 + L3
但是我们的模型中
L1:与年龄相关的损失,如平均绝对误差,因为它是回归损失。
L2:与种族相关的交叉熵,它是一个多类别的分类损失。
L3:性别有关的损失,例如二元交叉熵。
这里损失的计算最大问题是损失的量级是不一样的,并且损失的权重也是不相同的,这是一个一直在被深入研究的问题,我们这里暂不做讨论,我们只使用简单的相加,所以我们的一些超参数如下:
model = HydraNet().to(device=device)
ethnicity_loss = nn.CrossEntropyLoss()
gender_loss = nn.BCELoss()
age_loss = nn.L1Loss()
sig = nn.Sigmoid()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.09)
然后我们训练的循环如下:
for epoch in range(n_epochs):
model.train()
total_training_loss = 0
for i, data in enumerate(tqdm(train_dataloader)):
inputs = data["image"].to(device=device)
age_label = data["age"].to(device=device)
gender_label = data["gender"].to(device=device)
eth_label = data["ethnicity"].to(device=device)
optimizer.zero_grad()
age_output, gender_output, eth_output = model(inputs)
loss_1 = ethnicity_loss(eth_output, eth_label)
loss_2 = gender_loss(sig(gender_output), gender_label.unsqueeze(1).float())
loss_3 = age_loss(age_output, age_label.unsqueeze(1).float())
loss = loss_1 + loss_2 + loss_3
loss.backward()
optimizer.step()
total_training_loss += loss
这样我们最简单的多任务学习的流程就完成了
关于损失的优化
多任务学习的损失函数,对每个任务的损失进行权重分配,在这个过程中,必须保证所有任务同等重要,而不能让简单任务主导整个训练过程。手动的设置权重是低效而且不是最优的,因此,自动的学习这些权重是十分必要的,
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics cvpr_2018
这篇论文提出,将不同的loss拉到统一尺度下,这样就容易统一,具体的办法就是利用同方差的不确定性,将不确定性作为噪声,进行训练
End-to-End Multi-Task Learning with Attention cvpr_2019
这篇论文提出了一种可以自动调节权重的机制( Dynamic Weight Average),使得权重分配更加合理,大概的意思是每个任务首先计算前个epoch对应损失的比值,然后除以一个固定的值T,进行exp映射后,计算各个损失所占比
最后如果你对多任务学习感兴趣,可以先看看这篇论文:
A Survey on Multi-Task Learning arXiv 1707.08114
从算法建模、应用和理论分析的角度对MTL进行了调查,是入门的最好的资料。
https://avoid.overfit.cn/post/57d4e8712c634fe887247ce66e694f8f
作者:Alessandro Lamberti
以上是关于Pytorch创建多任务学习模型的主要内容,如果未能解决你的问题,请参考以下文章