诺亚深度自然语言处理高引用论文回顾
Posted 诺亚实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了诺亚深度自然语言处理高引用论文回顾相关的知识,希望对你有一定的参考价值。
华为诺亚方舟实验室近年来开展了一系列关于深度自然语言处理的研究和技术创新,在自然语言处理、机器学习、人工智能等领域的国际会议和期刊上发表论文30余篇,累计被引用2300余次。本文将简要回顾其中代表性的、引用率高的8篇论文。
论文:Convolutional Neural Network Architectures for Matching Natural Language Sentences. In NIPS 2014.
许多应用问题本质上是异质数据的匹配问题,如文本搜索、协同过滤、图片标注等。该论文提出了一个基于卷积神经网络的深度匹配模型,使用一个二维卷积神经网络来逐层地描述两个句子的表示、以及其相互作用的表示,最终得到两个句子匹配的全局表示。在这个全局表示之上再用一个全连接的神经网络来得到两个句子的最终匹配值。这样的架构可以充分描述两个句子中各种粒度的对应关系,包括细粒度(发生在较底层)和粗粒度(发生在较高层)的对应,而各种粒度的选择和组合完全取决于任务和数据的特性,通过学习自动判定。该模型对两个句子的匹配关系进行了比较完整地描述,这使得它的可扩展性与基于词包的或一维的卷积模型相比有明显优势。该论文是基于深度语义匹配方向上的奠基工作之一。截止目前,该论文已被引用440余次,是过去五年发表在NIPS上被引用次数最多的50篇论文之一。
论文:Neural Responding Machine for Short Text Conversation. In ACL 2015.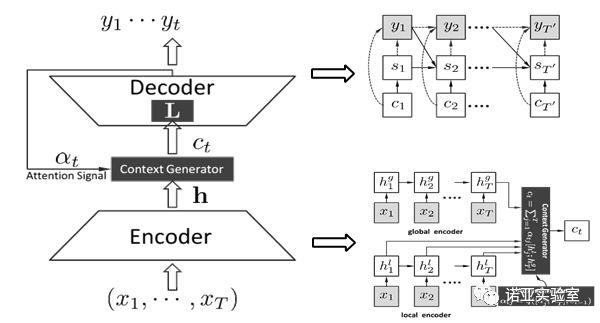 短文本对话是人机对话的子问题,也是人工智能通过图灵测试所必需解决的问题,可以应用到短信自动回复,聊天机器人等许多场景。该论文提出了一种基于深度学习的端到端的生成式对话系统:神经响应机 (Neural Responding Machine)。神经响应机主要由编码器和解码器两个部分组成。 编码器(包括局部编码器和全局编码器)实现“语义理解”的功能, 而解码器则实现“语言生成”的功能。编码器和解码器均通过深度递归神经网络实现。该系统能够对任意输入的短文本自适应的生成一段回复文本,显著超越了之前基于信息检索的对话系统。该论文是最早将Seq2Seq思想应用于自然语言对话领域的工作。截止目前,该论文已被引用350余次,是过去五年发表在ACL上被引用次数最多的20篇论文之一。
短文本对话是人机对话的子问题,也是人工智能通过图灵测试所必需解决的问题,可以应用到短信自动回复,聊天机器人等许多场景。该论文提出了一种基于深度学习的端到端的生成式对话系统:神经响应机 (Neural Responding Machine)。神经响应机主要由编码器和解码器两个部分组成。 编码器(包括局部编码器和全局编码器)实现“语义理解”的功能, 而解码器则实现“语言生成”的功能。编码器和解码器均通过深度递归神经网络实现。该系统能够对任意输入的短文本自适应的生成一段回复文本,显著超越了之前基于信息检索的对话系统。该论文是最早将Seq2Seq思想应用于自然语言对话领域的工作。截止目前,该论文已被引用350余次,是过去五年发表在ACL上被引用次数最多的20篇论文之一。
论文:Incorporating Copying Mechanism in Sequence-to-Sequence Learning. In ACL 2016.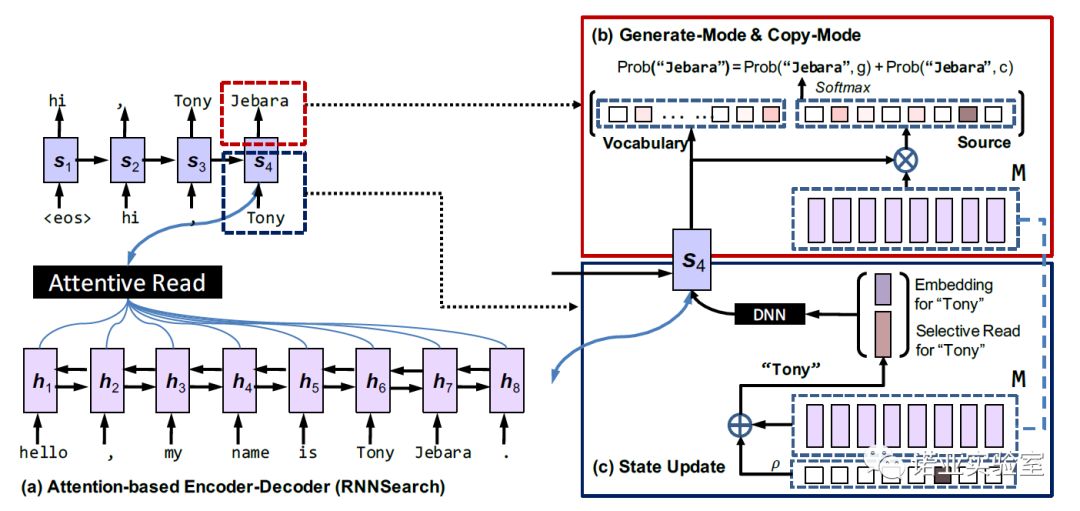 在很多自然语言生成任务中,都需要将输入语句的某些片段复制到输出语句。该论文提出了一种带有复制机制的Seq2Seq模型:CopyNet,将常规的生成模式与拷贝模式结合起来。具体的,该模型的解码器分为“生成”和“拷贝” 两种模式,并通过学习来决定在生成语句的过程中选择哪种模式。自论文发表以来,拷贝机制已经渐渐成为Seq2Seq模型的“标配”,被广泛应用于文本摘要、对话、复述生成、阅读理解、语义解析等多项自然语言生成任务中。截止目前,该论文已被引用210余次,是过去五年发表在ACL的被引用次数最多的30篇论文之一。
在很多自然语言生成任务中,都需要将输入语句的某些片段复制到输出语句。该论文提出了一种带有复制机制的Seq2Seq模型:CopyNet,将常规的生成模式与拷贝模式结合起来。具体的,该模型的解码器分为“生成”和“拷贝” 两种模式,并通过学习来决定在生成语句的过程中选择哪种模式。自论文发表以来,拷贝机制已经渐渐成为Seq2Seq模型的“标配”,被广泛应用于文本摘要、对话、复述生成、阅读理解、语义解析等多项自然语言生成任务中。截止目前,该论文已被引用210余次,是过去五年发表在ACL的被引用次数最多的30篇论文之一。
论文:Modeling Coverage for Neural Machine Translation. In ACL, 2016.
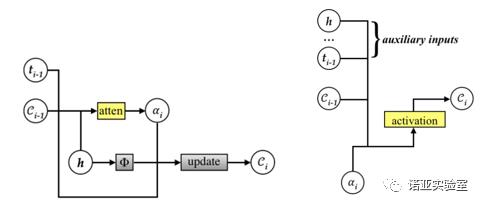
基于注意力机制的神经机器翻译已经得到了广泛应用,但是传统注意力机制忽略了其历史信息,往往会导致“过译”(词被翻译多次)和“漏译”(词没有被翻译)的问题。为了解决这个问题,该论文对注意力机制进行了改进,引入了覆盖向量表示每一个源端词汇是否已经被翻译,并以此去引导神经机器翻译更少地关注到已被翻译的词、而更多地关注到未被翻译的词。实验显示该方法有效地提高了翻译质量和对齐质量,过译和漏译的现象也明显降低。同时,本文提出的方法并不局限于神经机器翻译,对其他基于注意力机制的Seq2Seq任务也很有意义,比如文本摘要、自动问答等。截止目前,该论文已被引用190余次,是过去五年发表在ACL被引用次数最多的30篇论文之一。
论文:Multimodal Convolutional Neural Networks for Matching Image andSentence. In ICCV 2015.
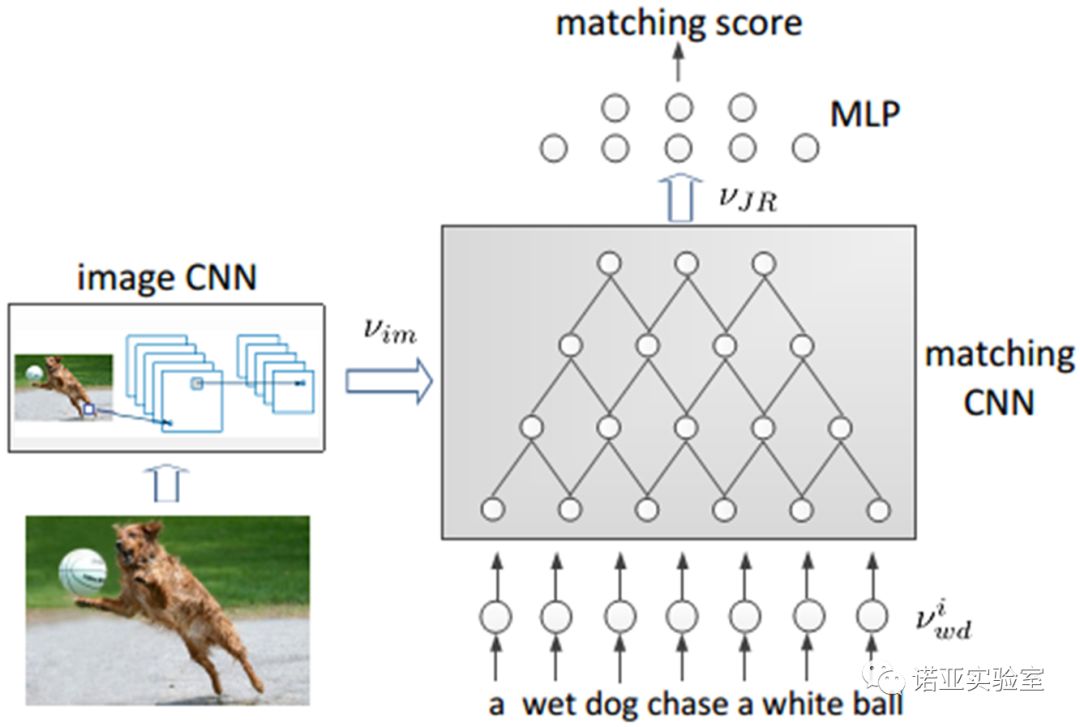
在多模态数据(图像,文本,语音等)数据的处理任务中,语义匹配起到了至关重要的作用。在一个好的图像与文本的匹配模型中,我们不仅要充分地表示图像以及理解自然语句,更重要的是能够表示图像跟自然语句之间的相互作用关系。该论文提出了一个多模态的卷积神经网络模型来学习图像跟文本之间的匹配关系。通过结合不同的语义匹配单元,该模型学习得到了图像与自然语句之间的局部以及整体的匹配关系。实验表明,该模型在图像与文本之间的双向搜索的实验上取得了突出的表现,成为当时该任务上的state-of-the-art,并且带动了其后关于文本图像检索、视觉问答等方向的工作。截止目前,该论文已被引用120余次。
论文:Self-Adaptive Hierarchical Sentence Model. In IJCAI 2015.
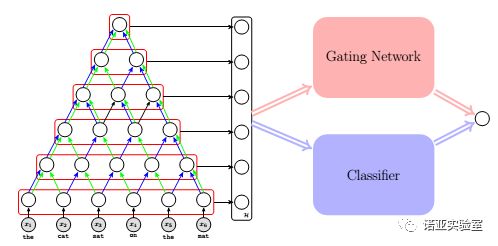
如何对于文本进行不同层次上(词-短语-句子)的建模是自然语言处理中的核心问题,这对于文本分类、文本匹配都起着关键作用。本论文提出了一个自适应的多层次句子模型(简称为AdaSent),该模型以卷积神经网络和门控网络(Gating Network)为基础,通过递归的方式自底向上地构建句子在不同层次上的表示。实验和数据分析表明,针对具体的自然语言处理任务(如文本分类),AdaSent能够自适应的学习到句子最合适的表示,并在该任务上优于当时的算法。AdaSent被认为是基于递归-卷积神经网络结构的句子建模的代表模型之一,被其后多篇研究句子建模的论文引用并作为重要的baseline。截止目前,该论文已被引用80余次。
论文:Encoding source language with convolutional neural network for machine translation. In ACL 2015.
该论文针对机器翻译系统的源语言表示,提出了一种基于卷积神经网络的结构。该结构覆盖整个源语言句子,能利用目标语言的信息动态地捕捉到源语言的相关部分,从而能在解码时取得当前最应关注的源语言部分。该工作是比较早的将卷积神经网络用于获得语言表示的研究工作,启发了后续关于卷积神经网络的神经机器翻译方面的研究。截止目前,该论文已被引用70余次。
论文:Neural Generative Question Answering. In IJCAI 2016.
Seq2Seq模型被广泛用于机器翻译、文本摘要、对话生成等任务,但在涉及到问答任务时,其本身的机制并不能保证生成语句的事实正确性。该论文提出了一种融合知识库的生成式问答系统:GenQA。该系统在Seq2Seq模型的基础上,增加了查询知识库的机制,并设计解码器将查询结果融入生成的语句中。该模型中,知识库的表示、查询、融合均通过神经网络计算完成,因此该模型可以进行端到端的训练。实验结果显示,该模型对于输入的自然语言问题,能够生成语言流畅且事实正确的答案。GenQA对于后续在深度神经网络结构中融入知识的研究工作有启发作用。截止目前,该论文已被引用70余次。
以上是关于诺亚深度自然语言处理高引用论文回顾的主要内容,如果未能解决你的问题,请参考以下文章
ACL 2019全程回顾:自然语言处理趋势及NLP论文干货解读