自然语言处理:使用深度强化学习玩雅达利
Posted 悠哉的咸鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理:使用深度强化学习玩雅达利相关的知识,希望对你有一定的参考价值。
论文名称:Playing Atari with Deep Reinforcement Learning
论文地址:http://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
相关论文:Human-level control through deep reinforcement learning
论文地址:https://storage.googleapis.com/deepmind-data/assets/papers/DeepMindNature14236Paper.pdf
强化学习在自然语言处理的文本生成方向上有不少的应用,本篇博客主要涉及对强化学习原理的解析。
《Playing Atari with Deep Reinforcement Learning》是2013年DeepMind发表在NIPS上的论文,为深度强化学习的开山之作,主要讲解了如何基于游戏数据帧(一幅幅游戏图像),使用深度强化学习在游戏上通关。《Human-level control through deep reinforcement learning》是对上一篇论文的改进,2015年发表于nature。
一、强化学习的基本原理
1.什么是强化学习
我们给出一堆红苹果和青苹果的照片(每张照片中只有一个苹果),通过图像识别能够辨别图片中苹果的红绿,因为我们事先已经对苹果的照片进行了标注。比如红苹果标记为1,青苹果标记为0,机器从我们事先标记的照片中学得信息,再用于别的苹果照片(监督学习)。但是这样存在一个问题,这些苹果的初始标注是怎么来的,没有初始标注如何学习标注同类物体的能力?我们人类在与环境不断的交互,不断的进行试错才学习得到辨别物体的能力。强化学习能从无标注的某类物体中学习知识,并能由此采取利益最大化的决策。
强化学习与我们人类的学会走路方式相似,一开始跌跌撞撞,在摔倒这个疼的环境反馈下,我们走下一步会越来越好。作用机制如下图所示,我们先观察环境状态(state),然后采取行动(action),获得反馈(reward)。通过上一步的行动,我们进入新环境,根据reward中学到的知识采取下一步动作。可以这么认为,强化学习就是智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的过程。
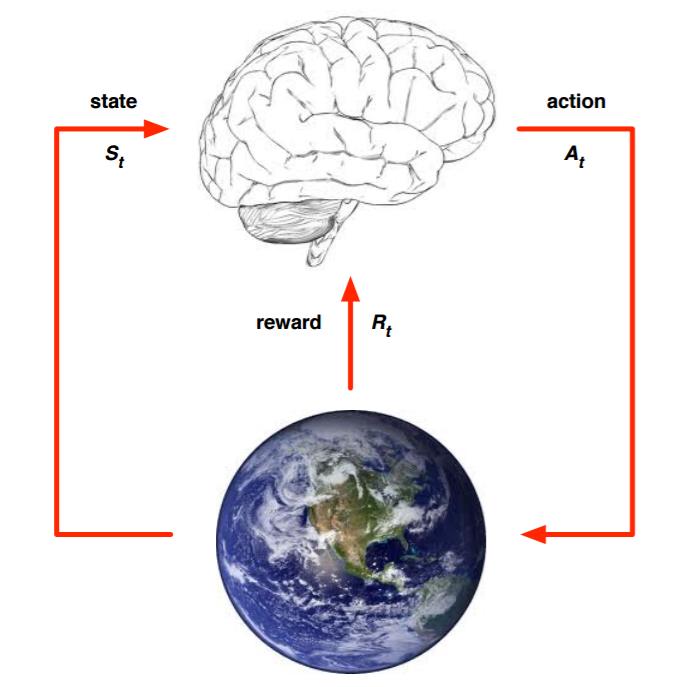
2.强化学习的要素
(1)环境状态
S
{\\rm{S}}
S,
t
t
t时刻环境状态为
S
t
{S_t}
St。
(2)个体(例子中是人,也可以是其它,通常称为agent智能体)的动作A,
t
t
t时刻采取的动作为
A
t
{A_t}
At。
(3)环境的奖励的
R
{\\rm{R}}
R,
t
t
t时刻在环境状态
S
t
{S_t}
St,采取
A
t
{A_t}
At动作,获得的奖励
R
t
+
1
{R_{{\\rm{t + 1}}}}
Rt+1(某个动作采取后,下一时刻才能获得回报)。奖励可为正奖励和负奖励(惩罚)。
(4)个体的策略(policy)π,是个体采取动作的根据。
π
(
a
∣
s
)
=
P
(
A
t
=
a
∣
S
t
=
s
)
\\pi (a|s) = P({A_t} = a|{S_t} = s)
π(a∣s)=P(At=a∣St=s)表示在
t
t
t时刻状态
S
t
{S_t}
St下,个体根据π策略采取动作
A
t
{A_t}
At的概率,一般最大概率动作就是我们采取的下一步动作。
(5)个体在策略π和状态
S
{\\rm{S}}
S时,采取行动后的价值(value),一般用
v
π
(
s
)
{v_\\pi }(s)
vπ(s)表示。虽然我们已经有了一个延时奖励
R
t
+
1
{R_{{\\rm{t + 1}}}}
Rt+1,但是很多情况下我们不能仅仅只看当前的回报。比如我们的目标是让我们生活舒适,现在我们拿了一万块钱工资,前几天大吃大喝会让我们相当舒服,但后边的日子就会相当难受。即我们不能仅仅考虑下一步的奖励,还得考虑后续的奖励。
v
π
(
s
)
{v_\\pi }(s)
vπ(s)可用公式表示:
v π ( s ) = E π ( R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . ∣ S t = s ) = E π ( R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ) {v_\\pi }(s) = {E_\\pi }({R_{t + 1}} + \\gamma {R_{t + 2}} + \\gamma 2{R_{t + 3}} + ...\\mid {S_t} = s){\\rm{ = }}{E_\\pi }({R_{t + 1}} + \\gamma {v_\\pi }({S_{t + 1}})|{S_t} = s) vπ(s)=Eπ(Rt+1+γRt+2+γ2Rt+3+...∣St=s)=Eπ(Rt+1+γvπ(St+1)∣St=s)
E
π
{E_\\pi }
Eπ表示的是后n步的数学期望;
γ
\\gamma
γ是奖励衰减因子,在[0,1]区间。
γ
\\gamma
γ=0为只考虑下一步的贪心算法,
γ
\\gamma
γ=1后续n步和下一步的同等重要。
γ
\\gamma
γ一般取(0,1),表示下一步的奖励最重要,但是其他后续奖励同样不可忽略。
(6)动作价值函数
q
π
(
s
,
a
)
{q_\\pi }(s,a)
qπ(s,a),表示在每个状态s下采取动作a带来的价值影响,计算公式如下:
q
π
(
s
,
a
)
=
E
π
(
G
t
∣
S
t
=
s
,
A
t
=
a
)
=
E
π
(
R
t
+
1
+
γ
R
t
+
2
+
γ
R
t
+
3
+
.
.
.
∣
S
t
=
s
,
A
t
=
a
)
=
E
π
(
R
t
+
1
+
γ
q
π
(
S
t
+
1
,
A
t
+
1
)
∣
S
t
=
s
,
A
t
=
a
)
{q_\\pi }(s,a) = {E_\\pi }({G_t}|{S_t} = s,{A_t} = a) = {E_\\pi }({R_{t + 1}} + \\gamma {R_{t + 2}}{\\rm{ + }}\\gamma {R_{t + 3}}{\\rm{ + }}...|{S_t} = s,{A_t} = a) = {E_\\pi }({R_{t + 1}} + \\gamma {{\\rm{q}}_\\pi }({S_{t + 1}},{A_{t + 1}})|{S_t} = s,{A_t} = a)
qπ(s,a)=Eπ(Gt∣St=s,At=a)=Eπ(Rt+1+γRt+2+γRt+3+...∣St=s,At=a)=Eπ(Rt+1+γqπ(St+1,At+1)∣St=s,At=a)
(7)状态转换机,在状态s下采取动作a,转到下一个状态s′的概率,表示为
P
s
s
′
a
{\\rm{P}}_{ss'}^a
Pss′a。
(8)探索率ϵ,我们在行动时一般会采取最有利的,但是这样也会导致一些陌生的行动方式没有被我们考虑到。此时我们有一定的概率采取别的行动,该概率为ϵ。一般来说,随着时间推移ϵ会越来越小,表示我们的行动已经逐渐利益最大化,采取别的行动对我们效益逐渐减小。
3.计算方法
实际中,强化学习的建模非常复杂,需要引入马尔科夫过程。我们假设某个状态s转移到下一个状态s’不与之前的状态产生关系,即某一状态仅与上一状态有关(马尔科夫性)。
在状态s下采取动作a,转移到下一个状态s’的概率计为
P
s
s
′
a
{\\rm{P}}_{ss'}^a
Pss′