自然语言处理中数据增强(Data Augmentation)技术最全盘点
Posted 深度学习与NLP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理中数据增强(Data Augmentation)技术最全盘点相关的知识,希望对你有一定的参考价值。
与“计算机视觉”中使用图像数据增强的标准做法不同,在NLP中,文本数据的增强非常少见。这是因为对图像的琐碎操作(例如将图像旋转几度或将其转换为灰度)不会改变其语义。语义上不变的转换的存在是使增强成为Computer Vision研究中必不可少的工具的原因。
是否有尝试为NLP开发增强技术的方法,并探讨了现有文献。在这篇文章中,将基于我的发现概述当前用于文本数据扩充的方法。
本文内容翻译整理自网络。
NLP数据扩充技术
1.词汇替代
此工作尝试在不更改句子含义的情况下替换文本中出现的单词。
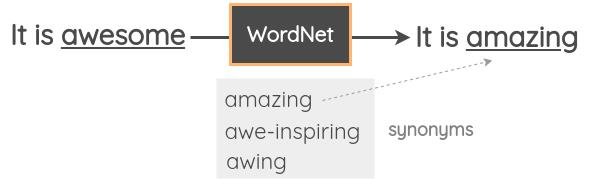
基于同义词库的替换
在此技术中,从句子中抽取一个随机单词,然后使用同义词库将其替换为其同义词。例如,可以使用WordNet数据库中的英语查找同义词,然后执行替换。它是一个人工编辑的数据库,描述单词之间的关系。
Zhang在他们的2015年论文“Character-level Convolutional Networks for Text Classification”中使用了该技术。Mueller等人使用相似的策略为其句子相似性模型生成额外的10K训练数据。Wei等人也使用了这种技术作为“轻松数据增强”论文中四个随机增强集合中的一种技术。
为了实现,NLTK提供了对WordNet 的编程访问。读者也可以使用TextBlob API。此外,还有一个名为PPDB的数据库,其中包含数百万个可以通过编程方式下载和使用的短语。
词嵌入替换
在这种方法中,采用了经过预训练的词嵌入,例如Word2Vec,GloVe,FastText,Sent2Vec,并使用嵌入空间中最近的相邻词作为句子中某些词的替换。Jiao已在他们的论文“ TinyBert ” 中将这种技术与GloVe嵌入一起使用,以改进其语言模型在下游任务上的通用性。Wang等人用它来增强学习主题模型所需的推文。

例如,读者可以将单词替换为最接近的3个单词,并获得文本的三种变体。
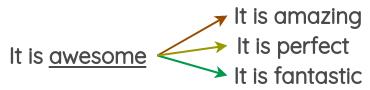
使用诸如Gensim之类的包来访问预先训练的单词向量并获取最近的邻居是很容易的。例如,在这里使用在推特上训练的单词向量找到单词“ awesome”的同义词。
相关好书推荐,京东1万+评论,99%好评:
以上是关于自然语言处理中数据增强(Data Augmentation)技术最全盘点的主要内容,如果未能解决你的问题,请参考以下文章
自然语言处理增强大法好!最易上手的 Augmentation Techniques有哪些?
20220310-nlp-text-data-augmentation
自然语言处理NLP之BERTBERT是什么智能问答阅读理解分词词性标注数据增强文本分类BERT的知识表示本质