自然语言处理增强大法好!最易上手的 Augmentation Techniques有哪些?
Posted 大数据应用
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理增强大法好!最易上手的 Augmentation Techniques有哪些?相关的知识,希望对你有一定的参考价值。

简单的文本编辑技术就能给小数据集在模型表现上带来巨大的收益。
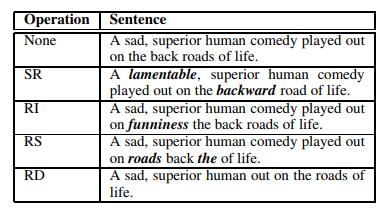
上图展示了该篇论文(https://arxiv.org/abs/1901.11196)中提出的各种针对NLP的数据增强操作。其中SR、RI、RS、RD分别表示同义替换、随机插入、随机交换和随机删除。有关这些技术的Github资料库在这里:https://github.com/jasonwei20/eda_nlp。
数据增强常用于计算机视觉方面。在视觉上,你几乎可以保证在不改变原始标签的情况下对一幅图像进行翻转、旋转或者镜像化。然而,在自然语言处理(NLP)中,事情就不一样了。改变一个词语就有可能会改变整个句子的意思。所以我们想不出简单的数据增强规则。还是说我们真有办法呢?
我要向你介绍EDA(Easy Data Augmentation):用于提升文本分类任务表现的简单数据增强技术。EDA由四项简单的操作构成,它们能出色地防止过拟合并有助于训练更为健全的模型,十分令人惊讶。它们是:
1. 同义替换:随机在语句中选择n个非停用词的词汇。对每个词随机选取它们的一个同义词进行替换。
2. 随机插入:给句子里的一个随机非停用词随机寻找一个同义词。将该同义词插入句子中的一个随机位置。重复该过程n次。
3. 随机交换:随机选择句子里的两个词进行位置交换。重复该过程n次。
4. 随机删除:随机移除句子里的词汇,每个词被移除的概率均为p。
这些技术真的有用吗?出乎意料得有用!虽然某些生成出来的句子可能有点莫名其妙,但在数据集中包括进一些噪声极有助于训练一个更加健全的模型,尤其是在小数据集上进行训练的时候。
正如上述论文所展示的,在五项基准文本分类任务中,使用EDA在几乎所有大小的数据集上都比通常的训练方法有更好的表现,而当训练小数据时,则比后者表现得好的多。平均来看,当用EDA训练循环神经网络(RNN)时,只使用可用训练集的50%,就能达到与用所有可用数据进行常规训练同等的准确率:
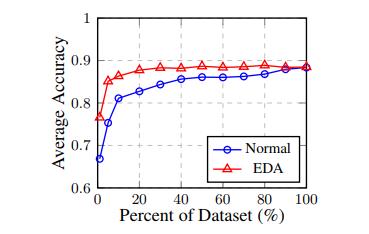
EDA能保存受增强句子的真实标签吗?
我知道你在想什么:你真的能在进行这些增强操作的同时保持受增强句子的真实标签吗?让我们用一个可视化方法来看看吧。。。
你训练了一个针对正面和负面评价的RNN模型,在常规和增强过的语句上都运行一遍,提取出神经网络的最末层,然后用t-SNE算法得到一个隐空间可视化图像:
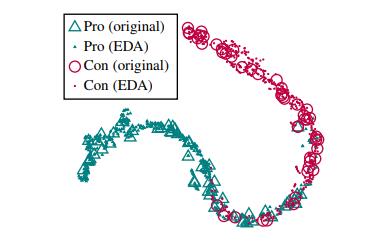
结果是受增强句子的隐空间表示紧紧环绕在原始句子周围!这意味着生成出来的增强语句极可能保留了与它们的原始语句相同的标签。
所有这些操作都有效吗?
现在,让我们把这些数据增强技术各自单独的效果给找出来吧。同义替换(直观上)是说得通的,但是其它3项操作呢?我们可以把各项技术孤立起来单独测试,该测试将它们应用于一个可变的α参数上,该参数粗略地表示“句子中被改变的词语数量的百分比”:
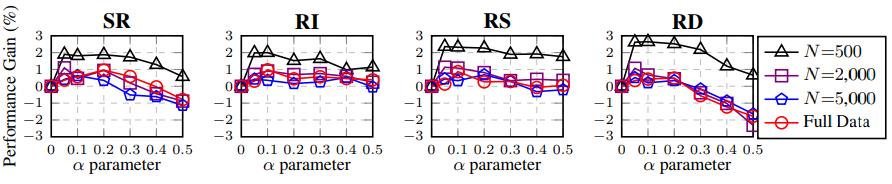
上图展示了五项文本分类任务中,EDA操作在不同训练集容量上的性能提升。
可以看到,小数据集上的性能提升尤其高,在2%到3%左右,而对大数据量的提升则比较有限,1%往下。然而,所有这些技术,只要使用一个合理的增强参数(不要在一个句子里改变超过四分之一的词),都有助于训练更健全的模型。
增强多少呢?
最后,我们应该给每个真实语句生成多少增强语句呢?这个问题的答案取决于你的数据集大小。若你只有一个小数据集,那就更可能会有过拟合问题,所以你可以生成更多的增强语句。对于大些的数据集,添加太多增强数据可能没有好处,因为当有大量真实数据的时候你的模型可能已经能够良好泛化了。下图展示了对每个原始语句生成不同数量的增强语句分别带来的性能提升:
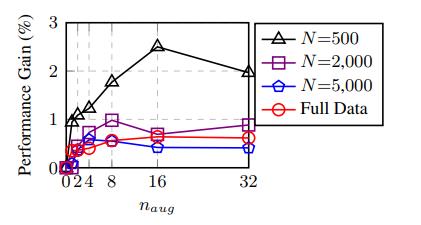
其中n_aug表示为每个原始语句生成的增强语句数量。
然后呢?
我们已经展示了,简单的数据增强操作可以显著提升文本分类的表现。如果你正在一个小数据集上训练文本分类器并且想找一个获得更好性能的简便方法的话,欢迎把这些操作应用到你的模型里。或者你可以从我上文给出的Github页面获取代码。你在本文开头所述论文中可以找到更多详细内容。
翻译:Siyu Hao

往期精彩回顾
以上是关于自然语言处理增强大法好!最易上手的 Augmentation Techniques有哪些?的主要内容,如果未能解决你的问题,请参考以下文章
初学者易上手的SSH-struts2 04值栈与ognl表达式
[YOLO专题-20]:YOLO V5 - ultralytics代码解析-马赛克数据增强mosaic augment