17.1 自然语言处理中文本数据增强方法
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了17.1 自然语言处理中文本数据增强方法相关的知识,希望对你有一定的参考价值。
文章目录
如今深度学习取得了令人瞩目的成功,但是深度学习模型需要有大量的标注数据进行支撑。真实应用情景中,经常会出现缺乏标注数据、数据分布不均衡导致模型鲁棒性差、模型性能不佳的问题,而文本增强能在一定程度上解决这些问题。
为什么文本增强会为模型带来性能提升呢?在扩大数据的数量使模型能够充分训练的表象之下,主要包含以下几个原因:
1、文本增强引入了外部知识
- 人工的先验知识,如将图片翻转之后图片类别不变,句子中动词的缩写展开变为原型语义不变等。
- 领域外知识,如使用预训练的生成器生成新的样例时,引入了预训练模型中丰富的知识。
2、防止过拟合
- 通过向数据中加入随机噪声,提升模型鲁棒性。
- 通过扩大数据的数量,使其更加平滑。
1、方法综述
数据增强最早应用在CV领域,如对图片进行翻转、旋转、缩放、平移等。近年来,出现了更为复杂的CV数据增强方法,如图片风格迁移Luan et al.(2017)[1](如图1)。

图 1 : 通 过 风 格 迁 移 得 到 图 片 增 强 图1: 通过风格迁移得到图片增强 图1:通过风格迁移得到图片增强
相较于数据增强在CV领域的广泛应用,其在NLP领域的应用较少。这是因为与图片的连续性表示不同,文本的表示是离散的、符号化的。这导致如翻转等简单的数据增强操作在NLP中失效。同时,自然语言中顺序信息十分关键,比如“小博吃了苹果”与“苹果吃了小博”是完全不同的含义。因此NLP领域中,需要尝试更复杂、更有挑战性的方法进行文本增强。
NLP领域中短文本常见的文本增强方法包括四大类(如图2):
图
2
:
自
然
语
言
处
理
中
的
数
据
增
广
方
法
分
类
图2 :自然语言处理中的数据增广方法分类
图2:自然语言处理中的数据增广方法分类
- 标签无关的通用文本增强方法不需要提供数据标签、任务需求等信息,只基于无标签的训练数据即可按照规则实现文本增强。
- 标签相关的特定文本增强方法则利用标签信息、按照任务需求进行增强,且需要考虑增强数据的标签相比于原数据标签是否变化的问题。
2、同义词替换
该方法通常利用近义词替换文本中的原始单词,从而在保持文本语义尽量不发生改变的前提下,得到新的表述方式。
2.1 基于近义词表的替换
这种方法使用近义词表,将句子中的部分单词利用其近义词替代,使增强数据尽量贴合原始语义。Zhang et al.(2015)[2] 和Jonas et al.(2016)[3] 使用来源于WordNet[4]的英语词库mytheas来自动进行近义词替换,该词库将单词的近义词按照相似度进行排序。对于每个句子,检索出该句中拥有近义词的所有单词,按照几何分布 P [ r ] p r P [r] ~ pr P[r] pr采样其中的 r r r个,并分别用其第 s s s个近义词替换, s s s也由几何分布决定: P [ s ] p s P [s] ~ ps P[s] ps 。这种方法保证了用更大的概率选中与原始单词更相似的近义词。
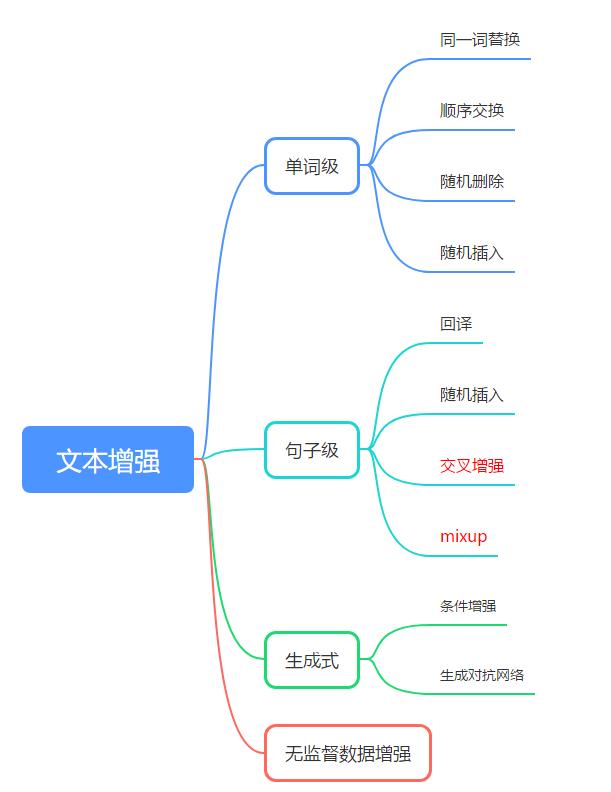
Wei et al.(2019)[5]同样使用WordNet作为近义词表,从句子中随机选择N个非停用词,N的大小与句子长度成正比,在它们的近义词中分别随机选择一个替换对应的原始单词。以下图3为基于近义词表进行单词替换的例子。
图
3
图3
图3
在句子中随机抽取n个词,然后从同义词词典中随机抽取同义词,并进行替换。
def synonym_replacement(words, n):
new_words = words.copy()
random_word_list = list(set([word for word in words if word not in stop_words]))
random.shuffle(random_word_list)
num_replaced = 0
for random_word in random_word_list:
synonyms = get_synonyms(random_word)
if len(synonyms) >= 1:
synonym = random.choice(list(synonyms))
new_words = [synonym if word == random_word else word for word in new_words]
#print("replaced", random_word, "with", synonym)
num_replaced += 1
if num_replaced >= n: #only replace up to n words
break
#this is stupid but we need it, trust me
sentence = ' '.join(new_words)
new_words = sentence.split(' ')
return new_words
def get_synonyms(word):
synonyms = set()
for syn in wordnet.synsets(word):
for l in syn.lemmas():
synonym = l.name().replace("_", " ").replace("-", " ").lower()
synonym = "".join([char for char in synonym if char in ' qwertyuiopasdfghjklzxcvbnm'])
synonyms.add(synonym)
if word in synonyms:
synonyms.remove(word)
return list(synonyms)
input: 我要像风一样自由
output: ['我要 像 风 一样 受限制', '我要 像 风 一样 公民权利', '我要 像 和风 一样 自由']
Coulombe et al.(2018)[12]介绍了引入常见拼写错误的文本作为增强数据,来模拟真实文本中包含此类噪声的情况,从而使模型对这种特殊类型的文本噪声变得更加鲁棒。英语中常见的拼写错误列表可以通过 Oxford Dictionaries的在线资源得到:https://en.oxforddictionaries.com/spelling/common-misspellings
Xie et al.(2017)[16]同样使用词表中的其他单词替换原始单词。该工作通过unigram 频率分布采样得到其他单词,将新单词作为噪声替换原始单词,产生增强数据。其中,unigram频率可通过单词在训练语料中的出现次数得到。
通 过 u n i g r a m 频 率 加 入 噪 声 通过unigram频率加入噪声 通过unigram频率加入噪声
基于近义词表的单词替换方法简单且方便,但是由于近义词表的限制,这种方法仍有一定局限性:
- 近义词表的规模有限,因此句子中能够利用近义词表进行替换的单词范围同样有限。
- 近义词表包含的单词词性有限,如WordNet中只包括名词、动词、形容词、副词四类,其他词性的单词无法通过近义词表进行替换。
- 近义词表中存在一词多义的情况,但是替换时难以判断原始单词在句中对应哪个词义,因此随机选择的新单词词义有可能与原始词义不符,使得增强数据的句义发生改变。
- 该方法以单词为单位进行替换,不同单词的替换过程相互独立。因此当一个句子的替换次数过多时,有可能损害语义流畅度。
2.2 基于词向量的替换
这种方法克服了基于近义词表的替换方法中对替换范围和单词词性的限制,采用预训练好的词向量,如Glove、Word2Vec、FastText等,用向量空间中距离原始单词最近的词将其代替。
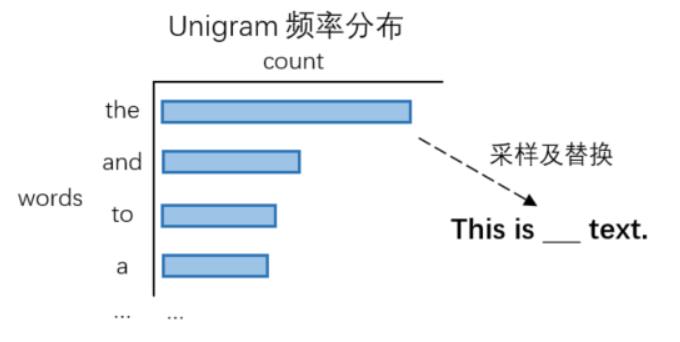
在文本分类任务中,由于Twitter的消息通常简短且噪声较多,同时每个类别的训练数据都相对匮乏,因此Wang et al.(2015)[6]引入连续的词向量来增强文本的多分类任务,来保证增强数据的多样性。如图4,对原始单词用余弦相似度最高的K个单词(k nearest neighbors)代替,如“Being late is terrible”变为“Being behind are bad”。同时类别标签不变。
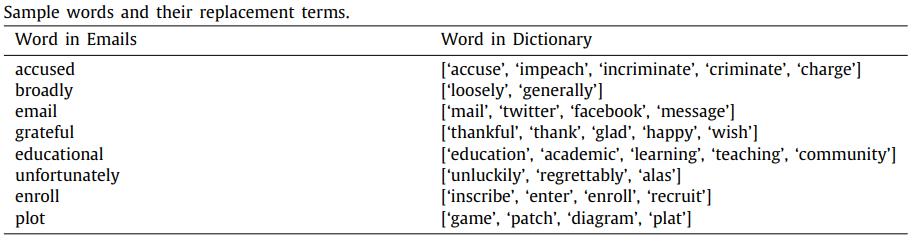
Liu et al.(2020)[7]在邮件分类任务中结合了基于近义词表和基于词向量的单词替换方法。首先基于词向量的相似度,为词表中的每个单词建立其最相关单词的字典。之后根据WordNet对这个字典进行修正或补充,如删除掉字典中不合理的缩略词,和添加字典中不存在的近义词。最后对句子中每个单词按照0.5的概率替换为它的近义词,同时每个近义词被选择的概率为0.2,以此得到该电子邮件的增强数据。图5为单词及其替换词字典的示例,图6为使用单词替换方法对邮件中数据进行增强的示例。
图
5
邮
件
中
单
词
及
其
替
换
词
字
典
图5 邮件中单词及其替换词字典
图5邮件中单词及其替换词字典
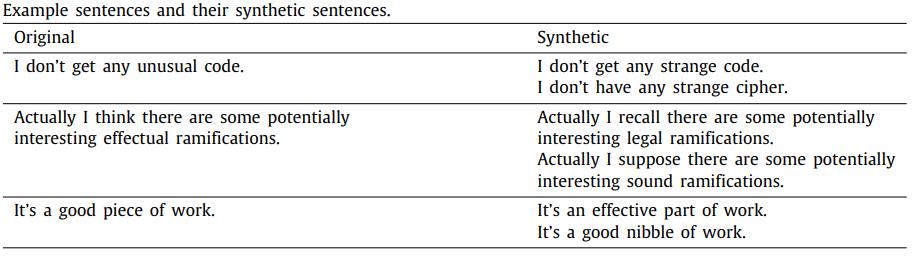
图 6 邮 件 分 类 任 务 中 使 用 单 词 替 换 的 方 法 进 行 文 本 增 强 图6 邮件分类任务中使用单词替换的方法进行文本增强 图6邮件分类任务中使用单词替换的方法进行文本增强
基于词向量的替换方法无需额外训练,且解决了近义词表只能应用于特定范围内单词的问题。但是,该方法同样面临一些问题:
- Wrod2Vec等静态的词向量对于每个单词只有一种表示方式,无法解决一词多义的情况。
- 该替换方法同样以单词为单位,与基于近义词表的方法类似,当一个句子的替换次数过多时,仍有可能损害语义流畅度。
2.3 MASK语言模型的替换
预训练语言模型凭借其出色的性能,成为近年来的主流模型。BERT、BoBERTa等掩码语言模型通过预训练的方式,获得了根据上下文预测文本中被mask的词语的能力,可用于文本增强。具体来说,将文本中的部分单词用[MASK]替换,用训练好的掩码语言模型对该位置的单词进行预测,补全句子信息。
Jiao et al.(2019)[8]先对每一条原始数据使用BERT自带的分词器进行分词,得到若干word piece,为每一个word piece构建其替换词的候选集合,其中构建替换词集合的过程包括前文的基于词向量的方法,以及基于掩码模型的方法。具体来说,如果该word piece不是完整单词,则利用Glove检索与其相似度最高的K个单词组成候选集合;如果该word piece是完整单词,则用[MASK]将它代替并用BERT预测出K个单词组成候选集合;最后以0.4的概率决定每个word piece是否被候选集合中随机一个词替换。下图7为基于掩码模型进行单词替换的示例。

图
7
基
于
掩
码
模
型
的
替
换
图7 基于掩码模型的替换
图7基于掩码模型的替换
与前面两种方法相比,掩码语言模型在预测时考虑到上下文信息,克服了一词多义的问题,因此能够生成语义更通顺的句子。但是,这种方法往往需要启发式的方法确定mask的位置,以保证增强语句不偏离原始语句的语义。
2.4 非核心词替换
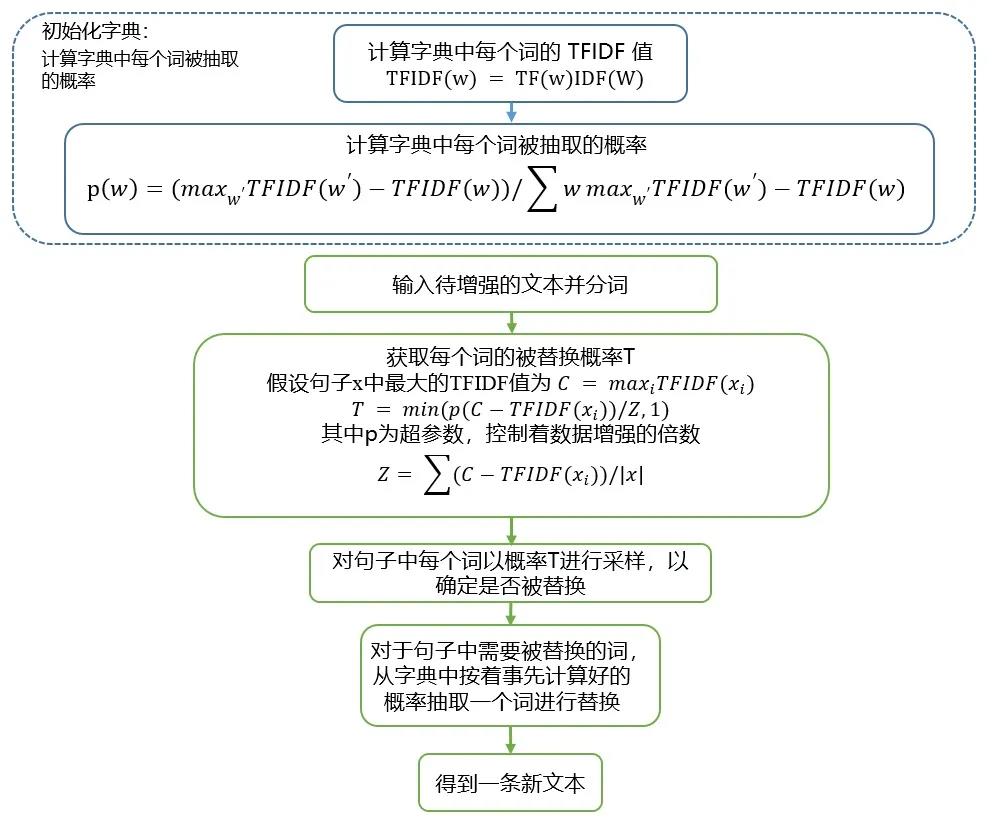
文本分类任务中,不同单词对分类预测的贡献不同,为了避免增强数据干扰分类准确性,Xie et al.(2019)[9]保留句中对分类结果影响较大的keywords,同时将其他普通单词随机替换为整个词表中的非keywords单词。
整个技术的核心点也比较简单,用词典中不重要的词去替换文本中一定比例的不重要词,从而产生新的文本。
我们知道在信息检索中,一般会用 TF-IDF值来衡量一个词对于一段文本的重要性,下面简单介绍一下 TF-IDF 的定义:
TF ( 词频 ) 即一个词在文中出现的次数,统计出来就是词频TF,显而易见,一个词在文章中出现很多次,那么这个词可能有着很大的作用,但如果这个词又经常出现在其他文档中如"的"、“我”,那么其重要性就要大打折扣,后者就是用 IDF 来表征。
IDF ( 逆文档频率 ),一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
I
D
F
=
log
(
语料库文档总数
包含词条
w
的文档数
+
1
)
\\mathrm{IDF}=\\log \\left(\\frac{\\text { 语料库文档总数 }}{\\text { 包含词条 } w \\text { 的文档数 }+1}\\right)
IDF=log( 包含词条 w 的文档数 +1 语料库文档总数 )
TF-IDF = TF×IDF,通过此公式可以有效衡量一个词对于一段文本的重要性。
当我们知道一个词对于一个文本的重要性之后,再采用与 TF-IDF 负相关的概率去采样文中的词,用来决定是否要替换,这样可以有效避免将文本中的一些关键词进行错误替换或删除。
UDA [9]论文中所提出的具体实现方式如下:
非 核 心 词 替 换 非核心词替换 非核心词替换
该工作使用TF-IDF值评估单词重要性,该单词被替换的概率与其重要性负相关。在替换过程中,使用整个词表中的非keywords单词替换该原始单词:使用频率和IDF值计算词表中每一个单词的重要性,归一化后作为使用该单词替换的概率。
整体来说,单词替换是单词级别的文本增强,着重对单个单词的独立更改。这种方法的优点包括操作简单、适用性强,不需要通过模型学习和大规模训练数据就可进行增强。缺点包括这种方法通常基于近义词进行增强,得到的增强数据丰富度有限;增强语句的语义可能不流畅或相对原始数据发生变化。
3、 回译
得益于近几年文本翻译领域的显著进展、各种先进翻译模型的开源 ( 包括百度、google 等翻译工具的接口开放 ),基于回译 ( back translation ) 方法的文本数据增强成为了质量高又几乎无技术门槛的通用文本增强技术。回译方法的基本流程很简单,利用翻译模型将语种1的原始文本翻译为语种2的文本表达,基于语种2的表达再翻译为语种3的文本表达,最后再直接从语种3的形式翻译回语种1的文本表达,此文本即是原始文本增强后的文本。当然,很多时候只采用一种中间语种也可以实现很好的增强效果。
我们利用 google 翻译举个例子:
- 原始文本为:文本数据增强技术在自然语言处理中属于基础性技术;
- 翻译为日语:テキストデータ拡張技術は、自然言語処理の基本的な技術です;
- 日语再翻译为英语:Text data extension technology is a basic technology of natural language processing;
- 英语再翻译回中文:文本数据扩展技术是自然语言处理的基本技术。
可以看出来,由于 google 翻译足够优秀,增强前后的文本在语义上基本保持一致。因此,对于回译这一增强技术,翻译模型的好坏决定了数据增强的最终效果。
其中还有一些细节值得说一下:
- 第一,如果采用翻译模型,可以采用 random sample 或 beam search 等策略实现成倍数的数据扩充。如果采用google等翻译工具,通过更换中间语种,也可以实现N倍的数据扩充。
- 第二,目前翻译模型对长文本输入的支持较弱,因此在实际中,一般会将文本按照 "。"等标点符号拆分为一条条句子,然后分别进行回译操作,最后再组装为新的文本。
google 团队提出了一种可用于 NLP 任务的半监督学习算法 ( UDA ) [9],使用WMT’14的英语-法语翻译模型(双向)对句子进行回译。这篇文章本身并不复杂,主要是实验证明了 回译 等文本增强技术可以用于半监督学习,而且结果看起来很惊人,他们仅用了 20 条样本作为标签数据,就在 IMDb 数据集上实现了接近 SOTA 的性能。当然,我们觉得这里面至少有一半的原因是算法采用的 BERT 模型原本就已经在大规模预料上学习过。
Luque et al.(2019)[10]则在英语、法语、葡萄牙语和阿拉伯语之间进行翻译。Zhang et al.(2020)[11]在风格迁移任务中引入数据增强,将非正式的原始英语数据翻译成法语,再重新翻译成英语,得到原始数据的正式表达。
4、 加入随机噪声
单词替换、回译方法的重点是使增强数据尽量与原始数据相似,构造更多类似于原始数据的新数据。与之相比,加入噪声的方法则为文本添加不太影响语义的微弱噪声,使之适当偏离原始数据,在扩大训练数据量的同时,提高模型的鲁棒性。人类通过对语言现象及先验知识的掌握,可以大大降低微弱噪声对语义理解的影响,但这种噪声可能为模型带来挑战。以下将对该方法以文本形式、顺序、语义三个方面进行介绍。
4.1 改变语法形式
单词级别的缩写还原、句子级别的句式转换(如主动变被动)虽然给语句的形式带来一定改变,但未对语义产生影响。将原始数据按照规则进行合理的形式变换,得到的增强数据将带有形式变化的噪声,提升模型对句式的把握。
4.1.1、单词级别语法变换
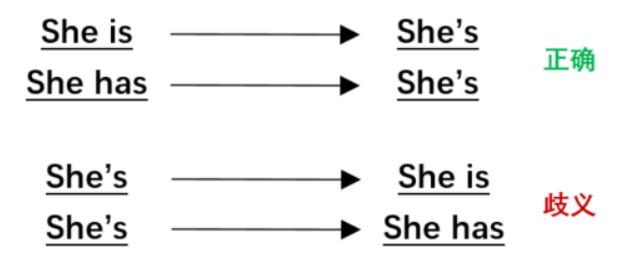
Be动词、情态动词、否定等缩写和原型间的转换属于简单模式匹配变换(text surface transformation),这种单词级别的语言现象虽然在形式上发生变化,却不改变语义。Coulombe et al.(2018)[12]介绍了使用正则表达式对英语中的简单模型进行变换,如通过一些固定的规则在be动词、情态动词和否定等的缩写和原型之间变换。 be动词的缩写、原型间的变换示例:

简
单
模
式
匹
配
变
换
示
例
简单模式匹配变换示例
简单模式匹配变换示例
需要注意的是,有些缩写对应多种原型表示,此时盲目转换会带来错误。对于这种情况,可避免缩写展开的方法,仅使用原型收缩为缩写的规则,保证准确。
原
型
收
缩
为
缩
写
不
会
出
错
,
而
缩
写
展
开
为
原
型
则
有
可
能
导
致
语
义
变
化
原型收缩为缩写不会出错,而缩写展开为原型则有可能导致语义变化
原型收缩为缩写不会出错,而缩写展开为原型则有可能导致语义变化
4.1.2、句子级别的语法树变换
该方法首先得到整个原始句子的依存树,并基于依存树使用规则对句子进行转换,来得到语法正确、语义不变的增强数据。相比于原始数据,该方法产生的增强数据携带有句式相关的噪声。
Coulombe et al.(2018)[12]介绍了这种通过依存树进行数据增强的方法:基于一个句子的依存树,按照规则进行转换,能够保持新句子的语法正确 。Min et al.(2020)[13] 借鉴了这种思想,如利用规则替换原句的主语宾语、将主动语态变为被动语态等。
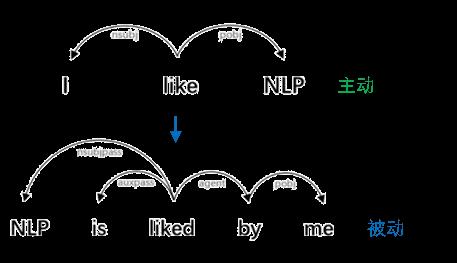
将
主
动
语
态
变
为
被
动
语
态
不
影
响
原
始
句
义
将主动语态变为被动语态不影响原始句义
将主动语态变为被动语态不影响原始句义
引入文本形式相关的噪声,即进行单词级别的简单模式匹配变换或句子级别的句式变换。它能够保证数据的语义不发生改变,同时增加模型对文本相应形式的鲁棒性。这种方法通常需要人为设计转换的规则,可控性强,同时文本增强过程直接可靠。
4.2、 文本交换
自然语言的语义对文本顺序信息敏感,如句子内不同单词的顺序和篇章内不同句子的顺序决定了句子或篇章的语义。但同时,如果在合理的范围内对文本顺序进行少量的调换[14],其结果对于人类而言仍然是可读的,即可通过阅读调换了语序的文本来理解原始文本的语义 。因此,少量的顺序调换可作为文本增强的方法,向模型引入文本顺序相关的噪声。

4.2.1、单词级别的文本顺序交换
该方法是指句子中不同单词之间进行顺序交换,如Wei et al.(2019)[5]提出了名为EDA的文本分类任务数据增强工具包,除了包括前文提到的近义词替换方式,也包括单词随机交换的方法。该工作在句子中随机选择两个单词并交换位置,重复n次。其中,随机交换的次数n与句子长度l成正比,即n=αl。

def random_swap(words, n):
new_words = words.copy()
for _ in range(n):
new_words = swap_word(new_words)
return new_words
def swap_word(new_words):
random_idx_1 = random.randint(0, len(new_words)-1)
random_idx_2 = random_idx_1
counter = 0
while random_idx_2 == random_idx_1:
random_idx_2 = random.randint(0, len(new_words)-1)
counter += 1
if counter > 3:
return new_words
new_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]
return new_words
4.2.2、句子级别的文本顺序交换
该方法是指篇章中不同句子之间进行顺序交换,如Yan et al.(2019)[15]使用随机排序的方法对法律文书进行句子级别的操作 。由于句子独立地包含了相对完整的语义,且文书中句子的顺序对原始文本的含义影响不大,因此将句子打乱顺序进行随机排列,从而得到增强文本。
Y
a
n
e
t
a
l
.
(
2019
)
[
15
]
对
法
律
文
书
句
子
使
用
随
机
插
入
、
删
除
、
排
序
的
文
本
增
强
Yan et al.(2019)[15] 对法律文书句子使用随机插入、删除、排序的文本增强
Yanetal.(2019)[15]对法律文书句子使用随机插入、删除、排序的文本增强
引入文本顺序相关的噪声,对句子和篇章分别进行适量的单词级别、句子级别的顺序调换,对语义的影响有限。使用这种方法需要合理设置顺序交换的次数和对象,保证增强数据的语义不过分偏离原始数据。
4.3、 文本语义相关的噪声
这类方法通常指通过单词或句子级别的删除、插入、替换等操作,为原始语料带入语义相关的噪声。
4.3.1、 随机删除
该方法包括“单词级”和“句子级”两种层次的删除操作,分别表示在句子中随机删除单词和在篇章中随机删除句子。
在单词级别的方法中,Wei et al.(2019)[5]EDA按照概率 p p p随机删除原始句子中的每个单词。

单
词
级
别
的
随
机
删
除
单词级别的随机删除
单词级别的随机删除
def random_deletion(words, p):
#obviously, if there's only one word, don't delete it
if len(words) == 1:
return words
#randomly delete words with probability p
new_words = []
for word in words:
r = random.uniform(0, 1)
if r > p:
new_words.append(word)
#if you end up deleting all words, just return a random word
if len(new_words) == 0:
rand_int = random.randint(0, len(words)-1)
return [words[rand_int]]
return new_words
Xie et al.(2017)[16]借鉴了“word-dropout”的思想,随机删减句子中的部分单词避免模型过拟合,但与 EDA不同的是,该工作用“_”作为占位符替换被删除单词的位置,表示该位置的信息为空。Yu et al.(2019)[17]包括单词、句子两种层次的删减,在单词级别上,首先对一条语句做attention,来衡量句子中不同单词的重要程度。根据该重要程度对句子中的单词进行删减:将重要性低于一定阈值的单词按照0.5的概率随机删除,剩下的单词互相拼接作为单词级别的文本增强。
在句子级别的方法中,与前文单词级别的随机删除类似,Yu et al.(2019)[17]在句子级别同样使用attention来衡量篇章中每个语句的重要性:对于包括10个及以上句子的篇章,首先对其做句子级
以上是关于17.1 自然语言处理中文本数据增强方法的主要内容,如果未能解决你的问题,请参考以下文章