复习一下数据结构——无序查找二分查找斐波那契分割查找
Posted 散人阿淦的自学之旅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了复习一下数据结构——无序查找二分查找斐波那契分割查找相关的知识,希望对你有一定的参考价值。
嗯哼!没错,是我阿淦,我来力!在实际工作中我发现有些在数据库的数据查出来其实是有序的,然后突然奇想,既然要找一条特定的记录,那我用二分查,不就完美了吗?!(鼻子老高哈哈哈哈哈)这个时候我体会到了查找算法的美丽!于是乎,回顾了一下《大话数据结构》中的查找算法(查找算法桢美啊~)
一、概念
1、查找:根据给定的某个值,从查找表中确定一个其关键字等于给定值的数据元素(或记录)。(在书架上找一本名为《美少女死神还我H之魂的书②》,不能找到一本《哆啦A梦②》);
2、查找表:由同一类型的数据元素(或记录)构成的集合。(下面那一排书同时同一类元素吧,可以想象成是一个数组Book[]);
3、关键字:数据元素中某个数据项的值(又称之为键值,“啊,我好想找《美少女死神还我H之魂的书②》这本书啊~”,这个时候“美少女死神还我H之魂的书②”就叫关键字);
4、关键码:记录中的某个数据项(字段)(比如说,《美少女死神还我H之魂的书②》这个值的数据项叫“书名”);
5、主关键字/次关键字:比如说图片中的书名,我能够通过"Java网络编程"找到唯一一本,那么“Java网络编程”这个叫主关键字,同时“书名”可以作为是主关键码;但是如果我想找“类别”为“Java”的书,这个时候查找出来的科不仅仅是一本“java网络编程”那么简单了,那么“Java”就是次关键字,而“类别”呢就是次关键码)
二、无序查找
无序查找其实没啥好说的,因为无序,所以没有规律,只能从头到尾遍历找。想想看《冥侦探孙X川》《名侦探柯南》中第一季,滚筒洗衣机家里的那些书,全部没有分门别类,然后你妈妈突然让你找一本书,这个时候你会有两种做法,一个是顺序找,一个是随机找(但是随机找你还得记录哪里找过了没有找到)
public int sequentialSearch(int[] a, int target) {for (int i = 0; i < a.length; i++) {if (target == a[i]) return i;}return -1;}
但其实这里还可以优化一下,与其每次循环都要判断是否数组越界,不如先设置一个结束点,然后让i到结束点的时候自动停下,但这个时候需要对数据空出一格,存放这个结束点
public int sequentialSearchNew(int[] a, int target) {int a[0] = target;int i = a.length - 1;// 循环从尾部开始while (a[i] != key) {i--;}return i;// 返回0则查找失败}
这两种查找算法看上去虽然没什么差别,但是总数据很多的时候,效率的提高是非常大的。顺序查找时间复杂度为O(n)
三、有序查找
对于无序的书来说,数量大了之后查找是非常困难的,如果在对书进行整理的时候,通过某一特性对书进行有序排列之后,对查找来说是非常有帮助的。
1、二分查找
带家都知道排序二叉树吧(没错!就是那个左子树不为空时子树上所有结点的值均小于它的根结点的值;右子树不为空时右子树上所有结点的值均大于它的根结点的值的那个!看一下图吧),那我要找,6,先从根节点出发,8,8 > 6,那么往左边查,以此类推,最终找到值
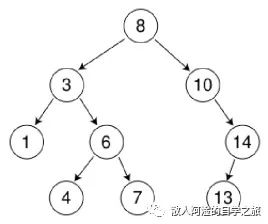
根据这个原理,不难得出二分查找的算法如下:
public int binarySearch(int a[], int target) {int left = 0;int right = a.length - 1;while (left <= right) {mid = (left + right) / 2;if (target < a[mid]) right = mid - 1;else if (key > a[mid]) left = mid + 1;else return mid;}return -1;}
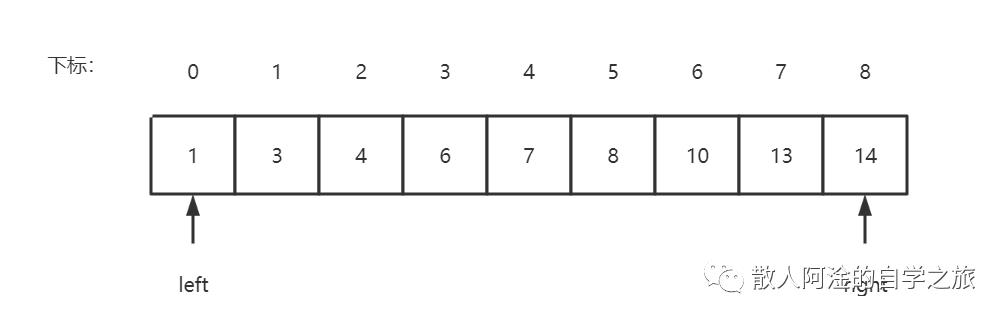
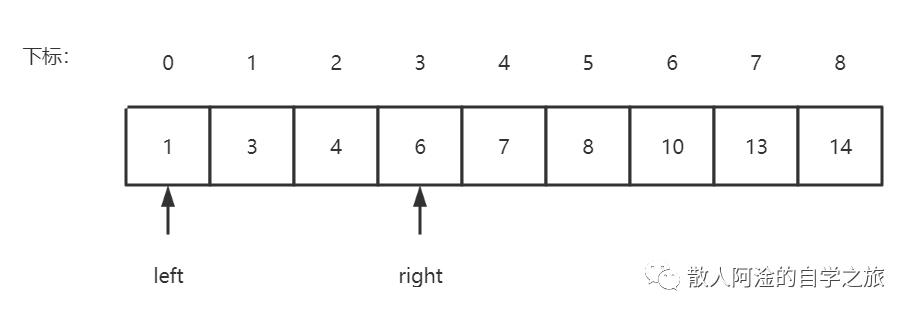
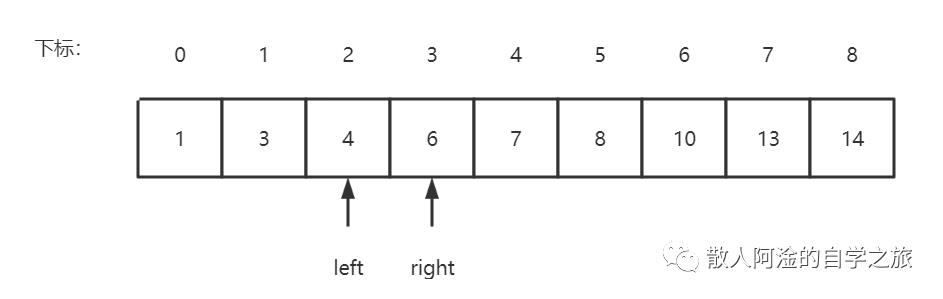
那么,我现在把数据a[] a = {1, 3, 4, 6, 7, 8, 10, 13, 14}放进去,target为6,这个时候呢,left = 0, right = 8;然后进入while循环,计算得出mid=4,a[4]=7,这个时候target < a[mid],所以right=4-1=3;依次类推
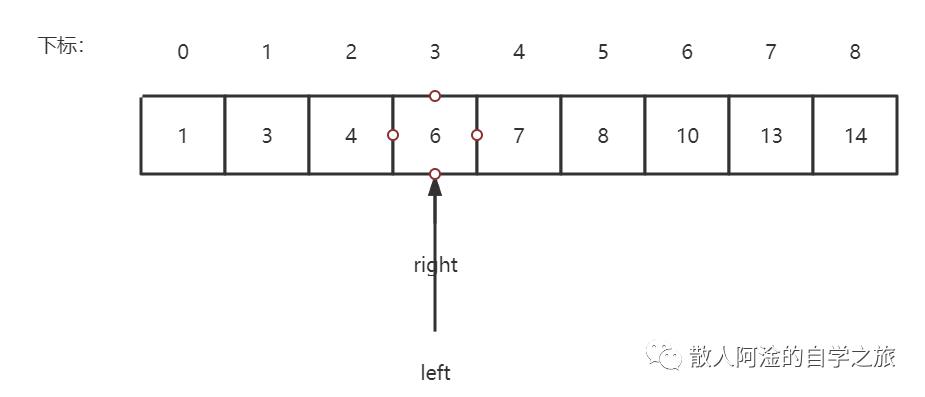
二分查找时间复杂度为O(logn),对于需要频繁插入或者删除的数据集来说,维护有序的序列会带来不少的工作量,就不建议使用二分查找了。
2、插值查找
那么问题又来了,为啥一定要二分呢,我四分行不行?(五等分的XX)八分行不行?答案是可以的。来个浅显的例子,假如说,您在找“apple”这个单词的时候,是会先把英语词典折半分,然后再折半吗?不会吧?这个时候肯定是有目的得只对前一小部分进行查找的。所以0~1000000从小到大均匀分布的数组中,要查找5的话,自然会考虑从下表比较小的开始找起。那么二分查找语句那么可以修改呢?
mid = (left + right) / 2 = left + (right - left) / 2 而我们就是要对这个1/2动歪脑筋(不是我,我不是数学家):
mid = left + (right - left) * (key - a[left]) / (a[right] - a[left]) 这里将1/2变成了(key - a[left]) / (a[right] - a[left])
假设a[] = {1, 3, 4, 6, 7, 8, 10, 13, 14},left = 0, right = 8,那么a[left] = 1, a[right] = 14,如果我们要找的key是6的话,我们需要4次查找到结果,而
(key - a[left]) / (a[right] - a[left]) = (6 - 0)/ (14 - 1)约等于0.462,即mid约等于 0 + 0.462 x (8 - 0) = 3(只需要3次查到结果,数据表更长的时候效率更明显)
3、斐波那契查找(黄金分割原理)
对于斐波那契数列来说,有个递归公式:F[k] = F[k - 1] + F[k - 2](k ∈ N且k >= 2 ),所以说,对于有序查找表,通过让其补充数据的方式满足F[k]个个数,然后再通过斐波那契分割对查找表进行分割,使其前半部分变为F[k - 1],后半部分为F[k - 2],找出要查找到的那个数据之前一直递归,直到查找到。第一次估值点为 mid1 = F(k - 2) / F(n)和 mid2 = 1 - (F(k - 2) / F(n))= F(k - 1) / F(n);若精度值f(mid1) > f(mid2),则删去(mid2, 1],否则删去[0, mid1),然后再对留下的区间进行函数估值
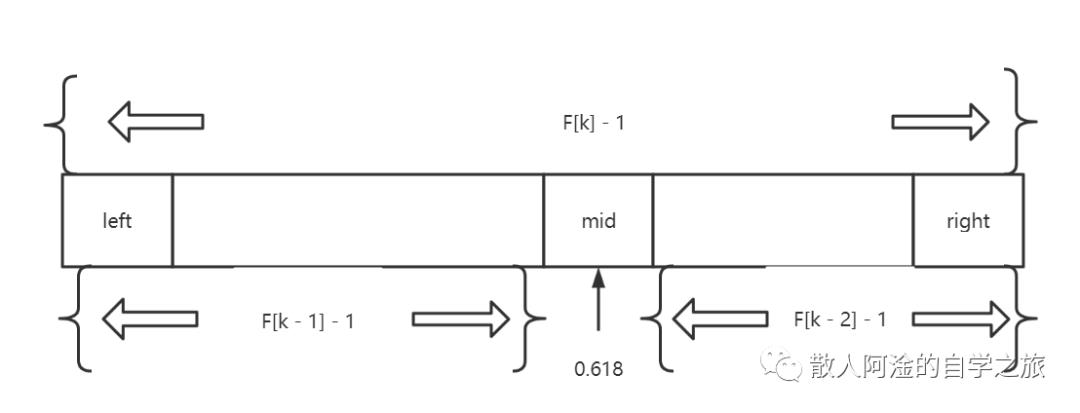
public int fibonacciSearch(int a[], int target) {int left = 0, right = a.length - 1, mid, k = 0, n = a.length;while (right > F[k] - 1) { // 计算n位于斐波那契数列的位置k++;}// 需要通过copyof去扩充数组,数组长度固定了,这里就不写了,直接通过// a[i]复制for (int i = right + 1; i < F[k] - 1; i++) {// 将不满的数值补全a[i] = a[right];}while (left <= right) {mid = left + F[k - 1] - 1; // 计算当前分隔的下标if (target < a[mid]) {right = mid - 1;// 如果目标值小于当前的a[mid],调整最高下标k = k - 1; // 斐波那契数列下标-1} else if (target > a[mid]) {low = mid + 1; // 如果目标值大于当前的a[mid],调整最低下标k = k -2; // 这里跟target < a[mid]不一样,是k - 2} else {if (mid <= a.length - 1) {return mid; // 相等则说明mid在原数组中的位置} else {return a.length - 1; // mid > a.length - 1则说明是补全数据}}}}
3.1、程序运行,target = 59,left指向0位置,right指向a数组的末尾下标
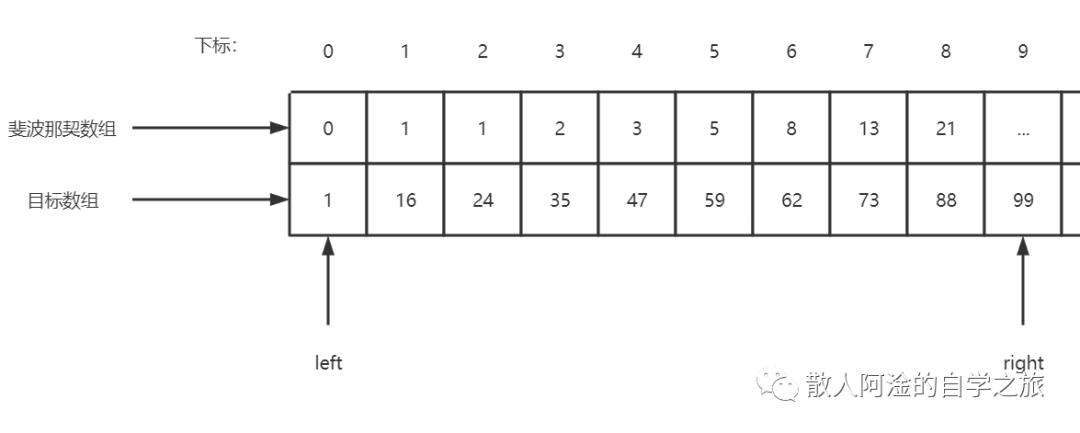
3.2、执行while循环,然后执行for循环将不足的数据补全(即k = 7时候,补全a[10]~a[11]的数据)
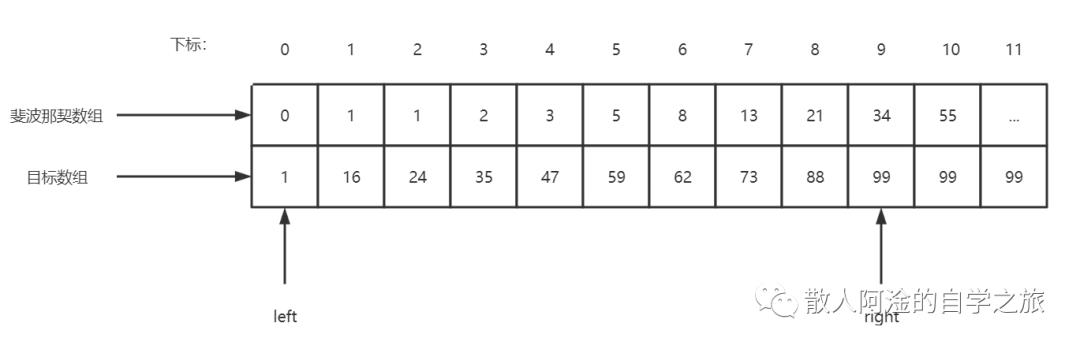
3.3、执行查找算法
mid = 0 + F[7 - 1] - 1 = 7, 59(target) < 73(a[7]),所以right = mid - 1 = 6,k = k - 1 = 6;
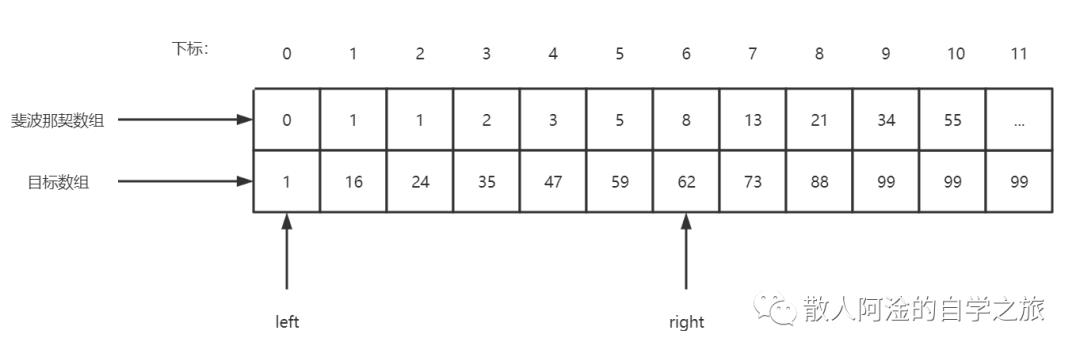
3.4、再次执行循环,这时候mid = 0 + F[6 - 1] - 1= 4,而59(target)> 47(a[4]),所以呢,left = mid + 1 = 5, k = k -2 = 4;
3.5、再次执行循环,mid = 5 + F[4 - 1] -1 = 6,而59(target)< 62(a[6]),所以,right = mid - 1 =5,k = k - 1 = 3;
3.6、最后执行循环的时候,mid = 5 + F[3 - 1] - 1= 5;target = a[5],返回5,程序结束。
3.7、如果target = 99的时候,第一次循环,mid依然为7,但99 > 73,所以left=8,k = 5;第二次循环,mid为10,此时若为补全a[10], a[11],则会因为数组越界而报错,补全数据是为了这种情况而出现的。
以上是关于复习一下数据结构——无序查找二分查找斐波那契分割查找的主要内容,如果未能解决你的问题,请参考以下文章
[Algorithm]二分插值斐波那契查找算法 Java 代码实现
[Algorithm]二分插值斐波那契查找算法 Java 代码实现