数据挖掘系列篇:聚类算法概述
Posted 区块链导报
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘系列篇:聚类算法概述相关的知识,希望对你有一定的参考价值。
本篇重点介绍聚类算法的原理,应用流程、使用技巧、评估方法、应用案例等。具体的算法细节可以多查阅相关的资料。聚类的主要用途就是客户分群。
1.聚类 VS 分类
分类是“监督学习”,事先知道有哪些类别可以分。
聚类是“无监督学习”,事先不知道将要分成哪些类。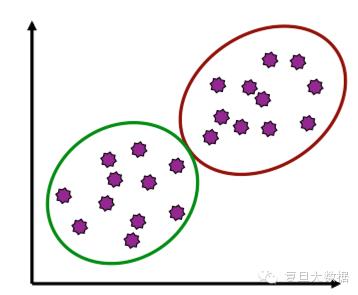
2.聚类的常见应用
我们在实际情况的中的应用会有:
marketing:客户分群
insurance:寻找汽车保险高索赔客户群
urban planning:寻找相同类型的房产
比如你做买家分析、卖家分析时,一定会听到客户分群的概念,用标准分为高价值客户、一般价值客户和潜在用户等,对于不同价值的客户提供不同的营销方案;
还有像在保险公司,那些高索赔的客户是保险公司最care的问题,这个就是影响到保险公司的盈利问题;
还有在做房产的时候,根据房产的地理位置、价格、周边设施等情况聚类热房产区域和冷房产区域。
3.k-means
(1)假定K个clusters
(2)目标:寻找紧致的聚类
a.随机初始化clusters
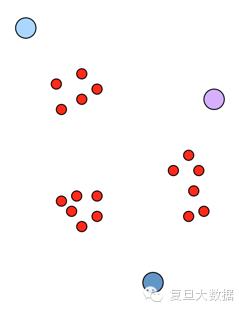 b.分配数据到最近的cluster
b.分配数据到最近的cluster
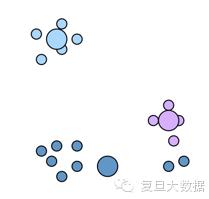
c.重复计算clusters
d.repeat直到收敛
优点:局部最优
缺点:对于非凸的cluster有问题
k-means聚类算法优缺点? - 数据挖掘
链接:http://www.zhihu.com/question/31296149
其中K=?
K<=sample size
取决于数据的分布和期望的resolution
AIC,DIC
层次聚类避免了这个问题
4.评估聚类
鲁棒性?
聚类如何,是否过度聚合?
很多时候是取决于聚合后要干什么。
如何评价聚类结果的好坏? - 机器学习
链接:http://www.zhihu.com/question/19635522
5.case案例
case 1:卖家分群云图
SPSS案例可以参考:
Spss K-means聚类分析案例——某移动公司客户细分模型
链接:http://www.datasoldier.net/post/kmeans.html
以上是关于数据挖掘系列篇:聚类算法概述的主要内容,如果未能解决你的问题,请参考以下文章