第一节:基于网格的聚类算法概述
Posted 我擦我擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一节:基于网格的聚类算法概述相关的知识,希望对你有一定的参考价值。
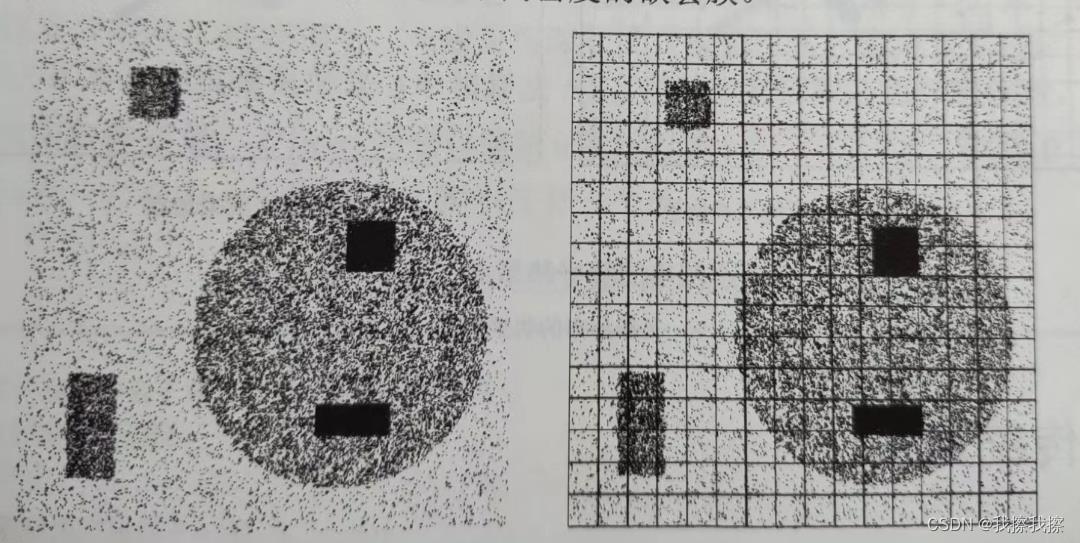
基于网格的聚类算法:主要用于处理大规模多维数据的聚类问题。它利用一个网格结构,将数据分布的空间划分为有限数目的单元,然后在这些网格单元上执行聚类操作。基于网格的聚类算法主要优点是能处理大数据集的聚类问题,其处理时间与数据量基本呈线性关系,主要依赖于数据空间的维度和每一维的单元数量。基于网格的聚类算法一般有以下五个典型步骤
- 建立网格结构:将要处理数据所分布的空间用网格的结构进行分割。一维数据用点分割,二维数据用线分割,分割得到的每个小块称之为单元
- 计算单元密度:单元密度是指每个单元数据点的数量与单元空间大小的比值
- 对单元按照密度进行排序:
- 识别簇中心:具有最高密度的单元即为簇中心
- 对邻接单元进行遍历:从簇中心开始,对与其邻接的单元进行遍历,找到同一簇中的其他单元
注意
- 在对单元进行排序和识别簇中心的时候,需要计算每个簇的密度,因此,有些时候基于网格的聚类算法也被视为基于密度的聚类算法
- 一些基于网格的聚类算法也结合了层次聚类(例如GRIDCLUS、STING算法都使用到了层次树结构),因此也被视为基于层次的聚类算法
尽管基于网格的聚类算法能在短时间内完成聚类,但同时也易受到下列类型数据的干扰
- 不统一的数据:由于基于网格的聚类算法使用了单一且不灵活的网格结构,对于那些高度不规则分布的数据,算法很难有效发现其分布结构
- 局部分布的数据:如果数据分布具有局部形状和局部密度问题,那么基于网格的聚类算法将由于受单元大小,边界和有效单元的密度阈值等问题的约束而受到限制
对于这两种类型数据,解决方法分别为
- 自适应网格聚类算法:会将特征空间分成多种分辨率,通过改变网格大小能较好处理数据不统一的问题
- 轴平移算法:这类算法采取轴平移分区策略来识别高密度的区域
以上是关于第一节:基于网格的聚类算法概述的主要内容,如果未能解决你的问题,请参考以下文章