冰山下的阴影--聚类算法在搜索用户体验测试的应用
Posted 唯品会质量工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了冰山下的阴影--聚类算法在搜索用户体验测试的应用相关的知识,希望对你有一定的参考价值。
背景—面对的挑战
背景:
作为搜索测试团队。我们主要负责唯品会搜索功能的质量。因为算法模型的特殊性,最基本的功能测试,已经不能保证结果的正确性,需要我们从多维度测试,来分析测试结果和算法结果的正确性。
目标:
针对搜索功能,摸索从多维度进行测试和质量保证。
Bug简述—Bug分析以及解决思路
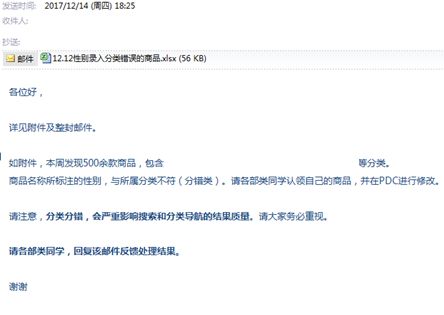
· 发现的问题与定位方式
用户在搜索筛选条件下,可以看到一些不符合逻辑的数据
· 定位问题:
发现在商务录入的时候,录入了错误的属性数据。
· 问题的通用性:
如何快速发现这类问题?定位商品?
· 旧的办法:
人工巡检 --> 输入query对比查询条件:数量小、速度慢。
· 新的方式:
对top1000热词的前450个商品直接进行聚类,根据分类的不同直接查看结果。
基本原理
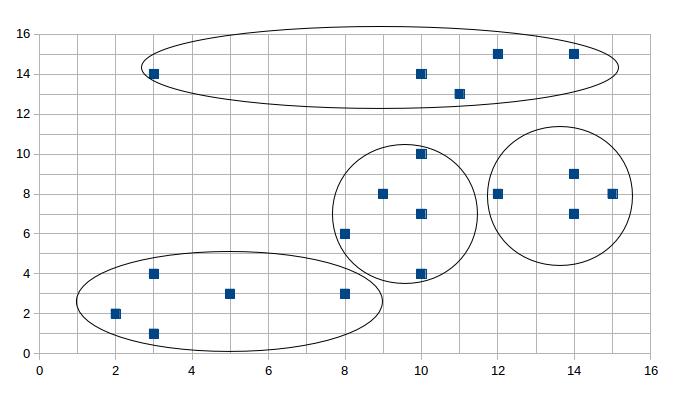
KMeans算法的基本思想
按照最邻近原则把待分类样本点分到各个簇。然后迭代重新计算各个簇的质心,从而确定新的簇心。直到簇心的移动距离小于某个给定的值。
· 目前的计算方式
1. 将现有属性拆分成矩阵
2. 根据现有矩阵执行聚类
· 后续建议
1.提高性能、可以对二维数据做归一化处理
2.可以先根据位置和簇点提前指定质心

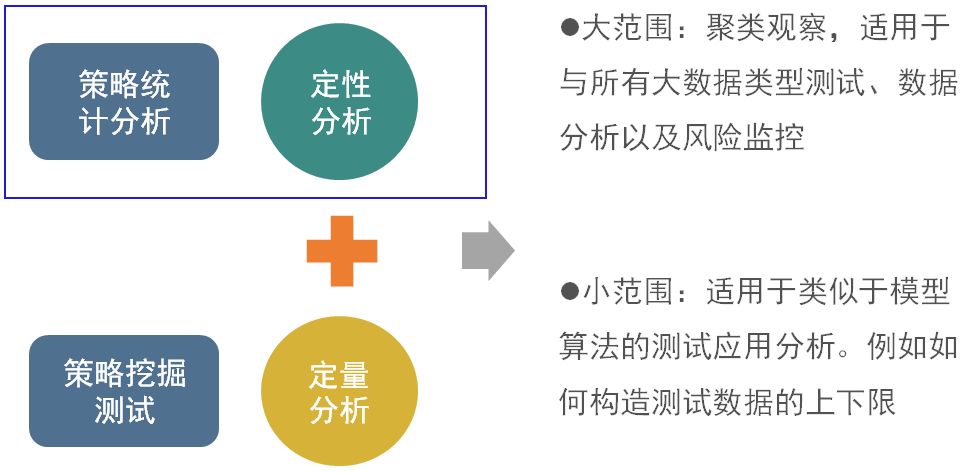
测试的普适性—可以用于哪些方面
聚类方法的普适性
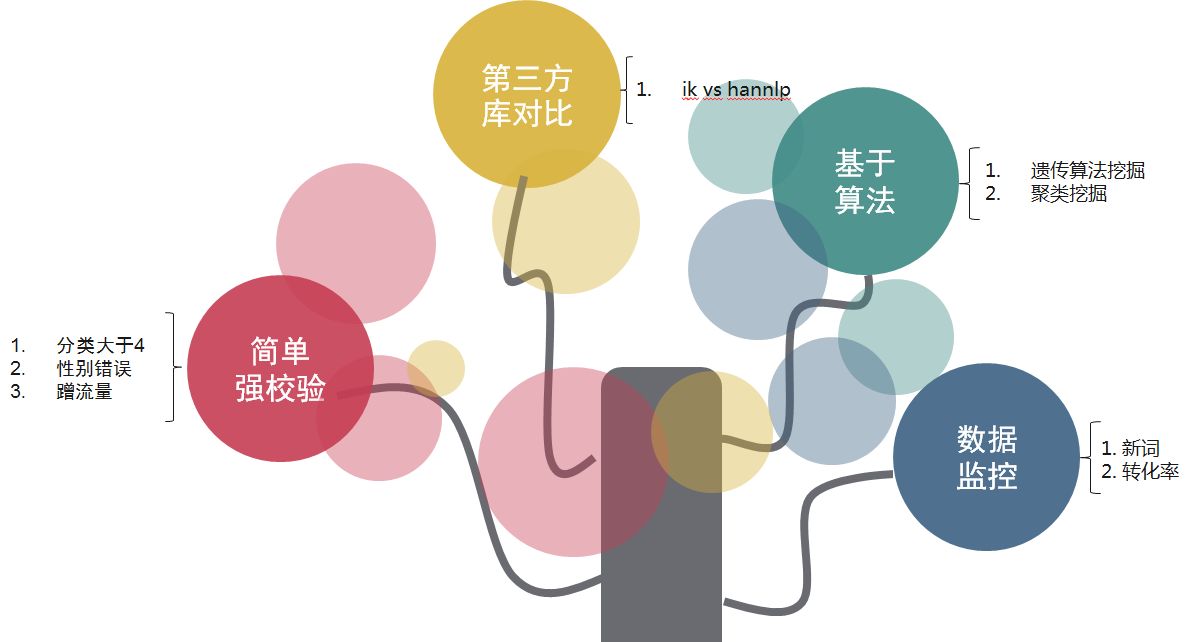
挖掘覆盖的范围
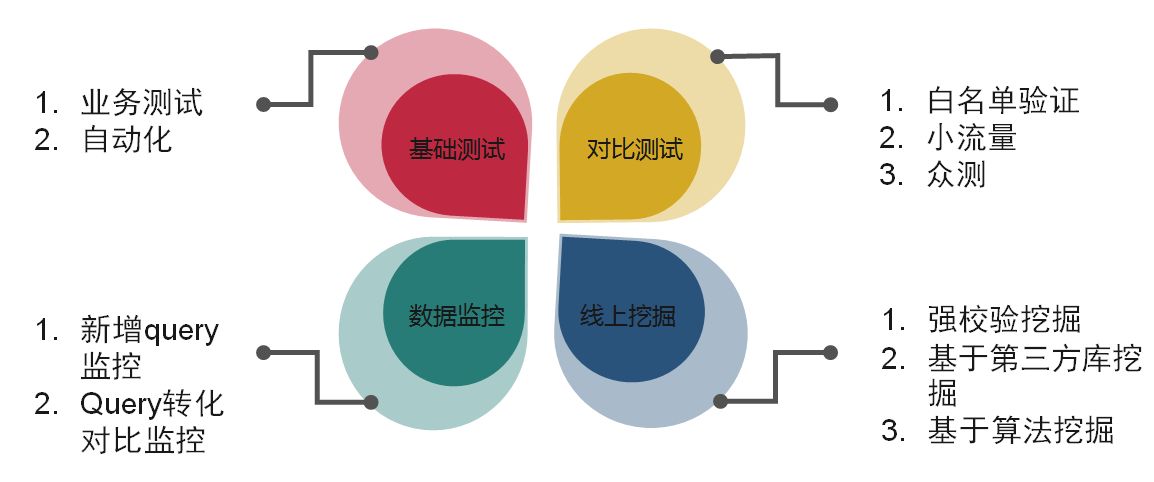
搜索质量效果保证方法
QA影响力
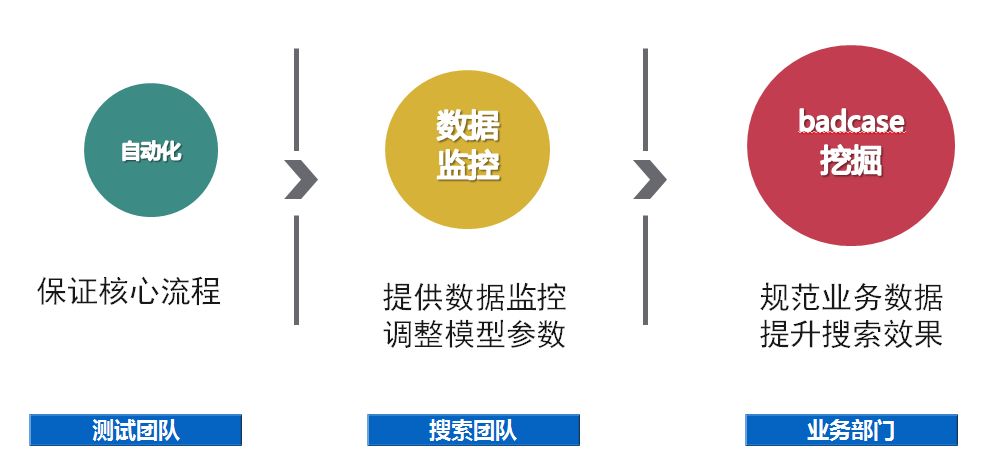
业务价值


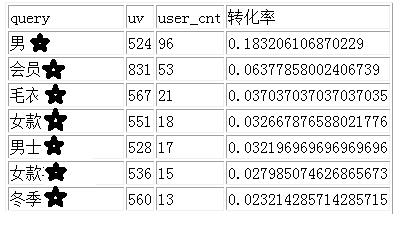
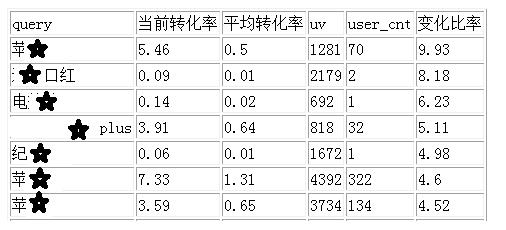
后续演进—定义算法测试
搜索的演进,从单纯提供搜索结果的solr1.0逐步进化为基于算法平台的多数据模型
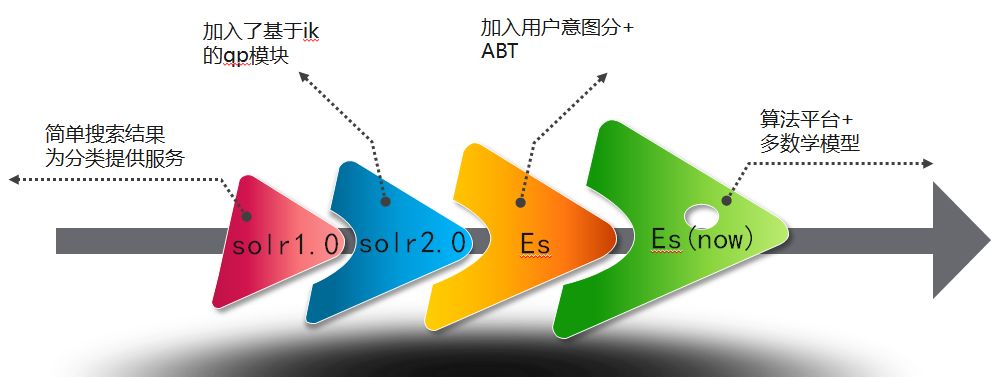
搜索测试的演进,从单纯的黑盒测试逐步进化为基于基于效果测试,以及定义数据的评估指标
以上是关于冰山下的阴影--聚类算法在搜索用户体验测试的应用的主要内容,如果未能解决你的问题,请参考以下文章