聚类算法学习笔记
Posted 拽拽的鼻嘎
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法学习笔记相关的知识,希望对你有一定的参考价值。
1. 补充:κ-误差图
κ(卡帕)是一个统计量,它可以度量个体学习器之间的多样性:当值为0时,说明两个学习器时偶然达成一致;当值为1,说明两个学习器完全一致;当值为负数,则表示达成一致的概率甚至低于偶然达成一致的概率,通常情况下,κ 为非负数。
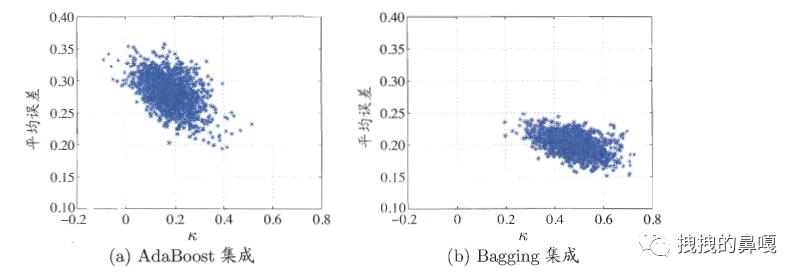
κ-误差图就是将每一对分类器作为图上的一个点,在这个图中横坐标为这对分类器的 κ 值,纵坐标为平均误差。针对得到的结果,数据云(数据点的汇集)越高,说明分类器的准确率越低,数据云越靠右,说明个体学习器的多样性越差,如图所示(图来源于西瓜书):
2. 聚类的定义
聚类指的是将数据集中的样本划分为若干个互无交集的子集,每个子集称为一个簇,每个簇潜在对应一些类别,但是类别的概念对于聚类算法而言是事先未知的,聚类算法仅仅是生成簇的结构,而具体簇含义的确定需要使用者自己去把握。
聚类既能作为一个单独的过程来寻找数据内部的结构,又可以作为其他算法的先行步骤,即先形成簇结构,再根据这些簇来训练算法。

3. 聚类的性能度量
聚类要求样本物以类聚,即相似的样本或者具有某些共同属性的样本划分为一个簇,簇内的相似程度越高越好,我们称这个指标为簇内相似度,它是聚类的内部指标;而对于簇与簇之间,我们则希望他们的相似度越低越好(相似度越低说明分类效果越好),称这个指标为簇间相似度,它是聚类的外部指标。
为了量化聚类的内部指标和外部指标,设数据集 D={x1,x2,x3,...,xm},使用聚类算法得到的簇为 C={C1,C2,...Ck},数据集的参考分类(参考分类可以理解数据集的原有分类或专家分类)为C*={C1*,C2*,...Ck*},λ 和 λ*分别表示C 和
C*的簇标记向量,将样本两两配对(xi,xj),定义四个参数a、b、c、d:
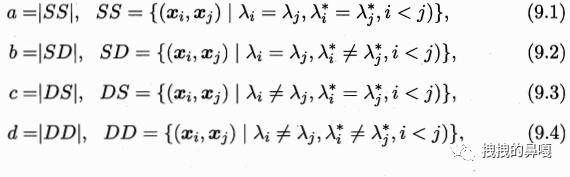
a 表示,xi 和 xj 在 C 中属于一个簇,在 C* 中也属于同样的簇;
b 表示,xi 和 xj 在 C 中属于一个簇,在 C* 中属于不同的簇;
c 表示,xi 和 xj 在 C 中属于不同的簇,在 C* 中属于同样的簇;
d 表示,xi 和 xj 在 C 中属于不同的簇,在 C* 中也属于不同的簇;
每个样本对只能出现在1个集合之中,所以 a+b+c+d 的和与样本对的数目一直,样本对数目=1+2+······+(m-1) = m(m-1)/2 个。
则根据a、b、c、d四个参数可以定义外部参数,其中常用的外部参数有:

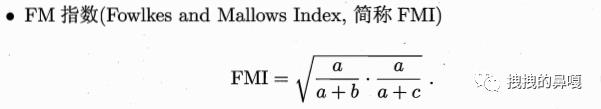

他们取值的结果都在区间 [0,1] 之间,值越大表示簇间差异越大,效果越好。
在分析簇内的相似度时,更多考虑的是样本之间的距离,因此,下面定义一些距离参数:
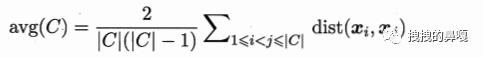
avg(C) 表示簇(C)内之间样本的平均距离;
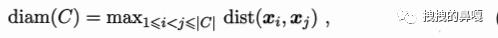
diam(C) 表示簇(C)内样本之间的最远距离;
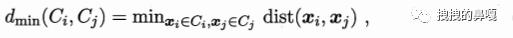
dmin(Ci,Cj) 表示簇(Ci)与簇(Cj)之间最近样本的距离;
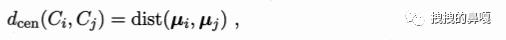
dcen(Ci,Cj) 表示簇(Ci)与簇(Cj)之间中心点的距离,其中中心点 μ 的求解方法为:

则常用的内部指标的求解如下:

DBI 的公式中,可以看到在括号中,决定大小的是分母部分,dcen 的大小越大,DBI 的值就越小,说明簇与簇之间的距离越大,分类效果越好。

DI 的公式中,决定其大小的是 diam ,diam 越小,DI的值越大,簇的样本之间的距离越近,说明簇内样本越集中,分类效果越好。
4. 距离计算
我们常将属性划分为两种:连续属性和离散属性。在涉及到距离计算时,除了连续和离散,还要考虑属性本身是否具备“序”的特征。例如:{1,2,3},这是一组离散属性,但是1、2、3本身具备“序”的概念,即3>2>1,因此,这就是一组有序属性;{学生,上班族,退休工} 这也是一组离散属性,但是特征之间本身并不具备“序”关系,因此这就是一组无序属性。
对于有序属性,我们求解距离常使用曼哈顿距离(亦称街区距离):
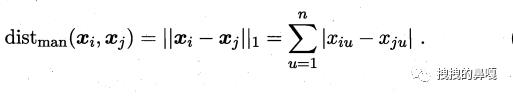
而对于无序属性可采用 VDM 距离:
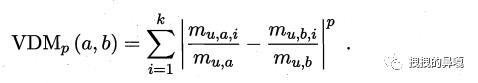
mu,a 表示属性 u 取值为 a 的样本个数,mu,a,i 表示在簇 i 中属性 u 取值为 a 的样本个数。
如果将曼哈顿距离和 VDM 相结合,就可以得到一个可以处理混合属性的距离度量:
同样,针对不同属性重要性不同的特点,可以对其进行加权,如下:
参考文章
【1】西瓜书—第九章—聚类
【2】西瓜书—第八章—集成学习
以上是关于聚类算法学习笔记的主要内容,如果未能解决你的问题,请参考以下文章