K均值聚类算法
Posted MaxAttention
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K均值聚类算法相关的知识,希望对你有一定的参考价值。
聚类算法
聚类属于典型的无监督学习算法,在数据挖掘与模式识别中有着广泛应用,此类算法需要处理的数据或者说样本特征一般情况下没有标签指明,该算法通过衡量样本间的相似度来使得相似样本归为一类(簇),而类的数量与属性也是未知的,属于需要进行调优的超参数。具体的类的数量我们在后文通过sse可以大致描述出来。
聚类算法的种类
-
层次聚类(hierarchical clustering) -
k均值聚类(K-means clustering)
本文介绍的是第二类:K-means算法 聚类所操作的对象便是实际的特征向量,假如我们有n个样本(向量),每个样本向量中有m个属性,那么下面的矩阵就可以表示样本集合
其中 表示第 个样本,而 表示第 个样本中的第 个属性,在做聚类算法的时候,我们需要考虑的重要因素是如何衡量样本(向量)之间的相似度(距离)。
闵可夫斯基距离(Minkowski distance)
欧几里得距离(Euclidean distance)
欧式距离隶属于闵可夫斯基距离 也是我们平时生活学习工作中最常用的距离表示,他的具体形式是p = 2
曼哈顿距离(Manhattan distance)
曼哈顿距离隶属于闵可夫斯基距离 ,他的具体形式为p=1
各类距离的定义我们知道上述常用的足矣,而在K-means算法中,一般使用的是欧氏距离,即
并且在计算的时候,一般不需要进行开放运算,因为这在保证距离相对工整的前提下,减少计算量。其实无论是工作中还是学习时,我们的算法除了保证更高的精确度,还要考虑算力不足的情况,只有那些巨擘型的企业才能玩得起依赖超大数据,超高算力的AI模型。相关系数
除了使用样本特征(向量)之间的距离之外,还可以使用样本(向量)间的相关系数进行衡量,相关系数属于一个归一化之后的值,代表的含义是相关系数接近1,表明样本(向量)越相似,越接近0,特性反之。样本 与样本 之间的相关系数定义为
其中
余弦夹角
样本(向量)之间的相似度也可以用余弦(cosine)来表示
K均值聚类
K-means算法将所有的样本特征放到K个类中,并且一个样本只属于一个类,不会出现交替重叠的情况,因此k-means算法属于硬聚类算法,这个前提也大大简化了模型算法的复杂度
K-means的策略与算法
通过函数最小化选取最优的划分或函数 ,而样本之间的距离衡量,选取的是欧式距离的平方
损失函数为样本到所属类的中心距离的总和,即
但是在给定超参数:k之后,使用损失函数而进行的聚类组合过程是指数级的运算。这也是一个NP困难问题,在现实中,通常使用迭代来计算求解
下面给出K-means的具体过程 输入:具有n个样本的集合X 输出:样本集合的聚类C
-
1.初始化第一次聚类过程需要的质心, -
2.对于第t次进行聚类操作所使用的质新 ,将每个样本 与质心分别衡量相似度,将这个样本分配至相似度最高的质心所在的类中。构成新的聚类 -
3.利用 聚类得到的结果 ,重新计算K个类的K个质心 -
4.如果迭代收敛或符合终止条件,那么有 ,否则t = t+1 返回step2
k-means的时间复杂度是:
代码部分
我们将使用鸢尾花数据集来做一个简单的练习,虽然这个数据集在有监督学习比较常用,但是不会影响我们的练习结果,不考虑标签列即可,数据集可以到Tensorflow官网自行下载
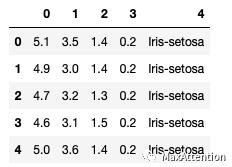
# 导入相关第三方包以及读取鸢尾花数据import numpy as npimport pandas as pdimport matplotlib as mlpimport matplotlib.pyplot as pltiris = pd.read_csv("iris.data.csv",header=None)iris.head()
## 定义计算向量见得欧式距离接口def distEclud(arrA,arrB):d = arrA-arrBdist = np.sum(np.power(d, 2), axis=1)return dist
# 随机生成质心def randCent(dataSet,k):n = dataSet.shape[1]data_min = dataSet.iloc[:, :n-1].min()data_max = dataSet.iloc[:, :n-1].max()data_cent = np.random.uniform(data_min, data_max, [k, n-1])return data_cent
对质心生成函数进行简单测试
data_cent = randCent(iris,3)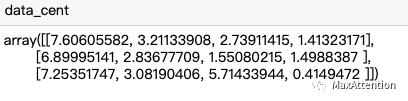
# DIY的K-means函数def kmeans(dataSet,k,distMeas=distEclud,createCent=randCent):m,n = dataSet.shapecentroids = createCent(dataSet,k)clusterAssment = np.zeros((m,3))clusterAssment[:, 0] = np.infclusterAssment[:, 1:3] = -1result_set = pd.concat([dataSet,pd.DataFrame(clusterAssment)],axis=1,ignore_index=True)clusterChanged = Truewhile clusterChanged:clusterChanged = Falsefor i in range(m):dist = distMeas(dataSet.iloc[i, : n-1].values,centroids)result_set.iloc[i, n] = dist.min()result_set.iloc[i, n+1] = np.where(dist==dist.min())[0]clusterChanged = not (result_set.iloc[:,-1] == result_set.iloc[:, -2]).all()if clusterChanged:cent_df = result_set.groupby(n + 1).mean()centroids = cent_df.iloc[:, :n-1].valuesresult_set.iloc[:, -1] = result_set.iloc[:, -2]print(clusterChanged)return centroids, result_set
这里需要解释下这个DIY的K-means的过程,读者可参考这个想法来阅读代码
-
-
使用randCent接口来创建k个质心,这是在随机选取的 -
-
在原数据基础上增加三列数据,第一列为该当前样本距离最近的质心的距离,第二列为当前所属质心,即所属簇,第三列为上一次所属质心即所属簇 -
-
不断迭代当前簇与上一次簇,直到所有样本完全一致,结束。下面是结果的部分截图
发现聚类的效果还可以
以上是关于K均值聚类算法的主要内容,如果未能解决你的问题,请参考以下文章