CNN发展史及其网络模型简介
Posted 沣云平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CNN发展史及其网络模型简介相关的知识,希望对你有一定的参考价值。
CNN发展史
及其网络模型简介
关键词:卷积神经网络
P1
卷积神经网络模型概览
从一开始的LeNet到后来的VGGNet,再到google的Inception系列,再到ResNet系列,每一种神经网络模型都有其创新的点,下面我们就来按照历史脉络好好讲解一下各种模型的特点。
1.LeNet模型结构
LeNet网络结构是在1998年由lecun提出的。它被创造出来的目的是解决手写数字识别的问题。即它是一个10分类任务的解决办法。
下图是它的一个基本的网络结构。
网络结构图中显示的很清楚。它包括了两个卷积层,两个下采样层,两个全连接层和一个激活层,最后有一个sotfmax分类层。可以说,LeNet麻雀虽小,五脏俱全。包括了基本的卷积神经网络的所有单元。
2.AlexNet
话不多说,我们直接上来看AlexNet的网络结构:
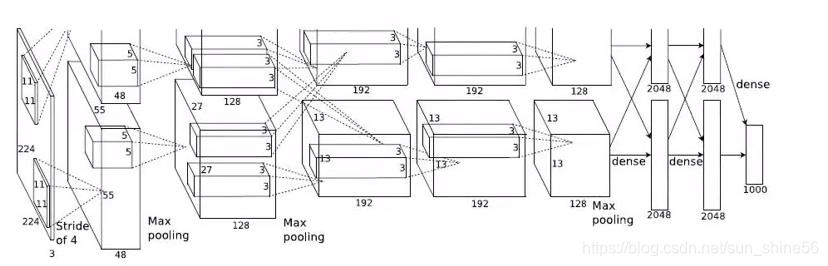
我们可以看到,它的网络结构被分成了两支,这是因为当时的GPU计算能力不够,显存容量不够大。为了完成模型的训练,作者使用了两块显卡来进行分布式的训练。我们现在想要训练这样一个模型,只需要实现其中一条就好了。
对比刚刚的LeNet,我们可以发现从结构上来看,它并没有很大的改变。我们看它的网络结构:输入层是224* 224的数据,然后进行了多轮卷积(提取特征),其中包括11* 11的卷积核,5* 5的卷积核,3* 3的卷积核。
虽然在图片上我们只画了卷积层,但我们应该知道,每一个卷积层之后都会跟上一个激活层(用来增加模型的非线性表达能力),一个降采样pooling层(减小数据量,提取主要特征),以及一个局部归一化处理(对数据进行一定的约束,使我们的数据约束在一定的范围内,使网络更好的收敛)。
经过多个卷积层之后,就会有三个fc层(全连接层)。同样的,在每一个fc层之后,也会有有一个relu激活层,以及一个dropout层(减小参数量,防止过拟合,增加i网络结构变化)。
最后,通过一个fc层+softmax层来将我们的数据映射到一个一千维的向量上去(因为实现的是一千种物品的分类网络),这个向量就是我们输入的图像在这一千个类别上的概率分布。其中概率值最高的那个类别就是网络判断出来图像所属的类别。
相较于LeNet网络,它的网络深度更深,并且成功运用了gpu进行运算,为后面的人们打开了新世界大门。整个网络的参数量在60兆以上,最终训练出来的模型文件在200兆以上。它最大的意义在于,通过这次实验,证明了更深层次的卷积神经网络,可以提取出更加鲁棒的特征信息,并且这些特征信息能更好的区分物品类别。
我个人的意见是,这个更深层网络提取更高维度的特征,它是这么个意思:前面的卷积层提取一些浅层的特征,比如纹理,形状(我们输入的是颜色特征),然后中间的卷积层呢,提取的是一些更复杂的特征,这些特征难以描述,就类似于我们中国说看山不是山,看水不是水的境界,只可意会,不可言传。而最后的分类信息,就是最后的看山还是山,看水还是水的境界。
在AlexNet网络中,有以下特点:
*增加了relu非线性激活函数,增强了模型的非线性表达能力。成为以后卷积层的标配。
*dropout层防止过拟合。成为以后fc层的标配。
*通过数据增强,来减少过拟合。
*引入标准化层(Local Response Normalization):通过放大那些对分类贡献较大的神经元,抑制那些对分类贡献较小的神经元,通过局部归一的手段,来达到作用。
当然后来人们通过研究发现,这个LRN层并没有啥太好的作用,所以在后来的网络结构中,它被BN层(批归一化层)取代了。
3.ZFNet
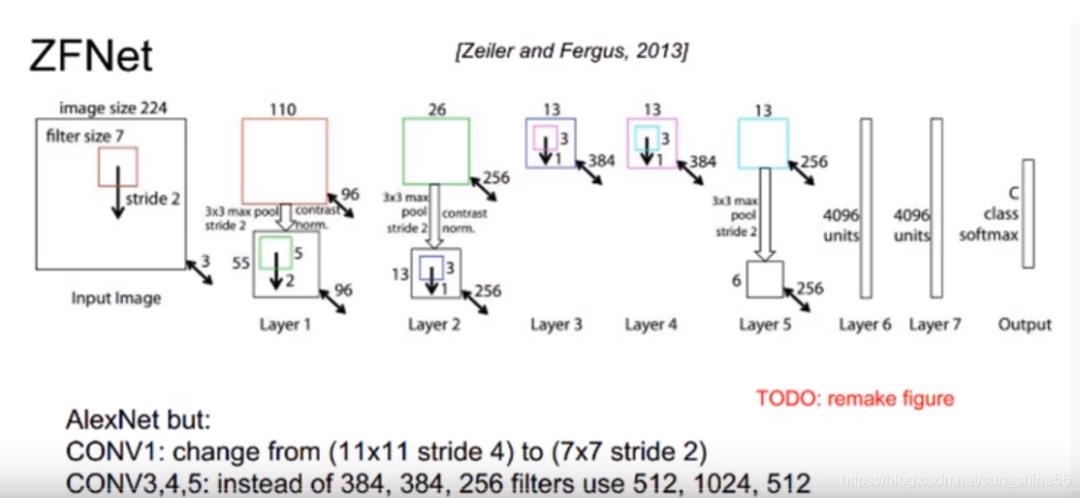
ZFNet在AlexNet的基础上做了小小的改进:
*调整第一层卷积核大小为7*7
*设置卷积参数stride=2
通过更小的卷积核和更小的步长,来提取更多的信息,确保网络提取出来的信息更加有效。其次,它增加了卷积核数量,导致网络更加庞大。
最重要的是:它从可视化的角度出发,解释了CNN有非常好的性能的原因。
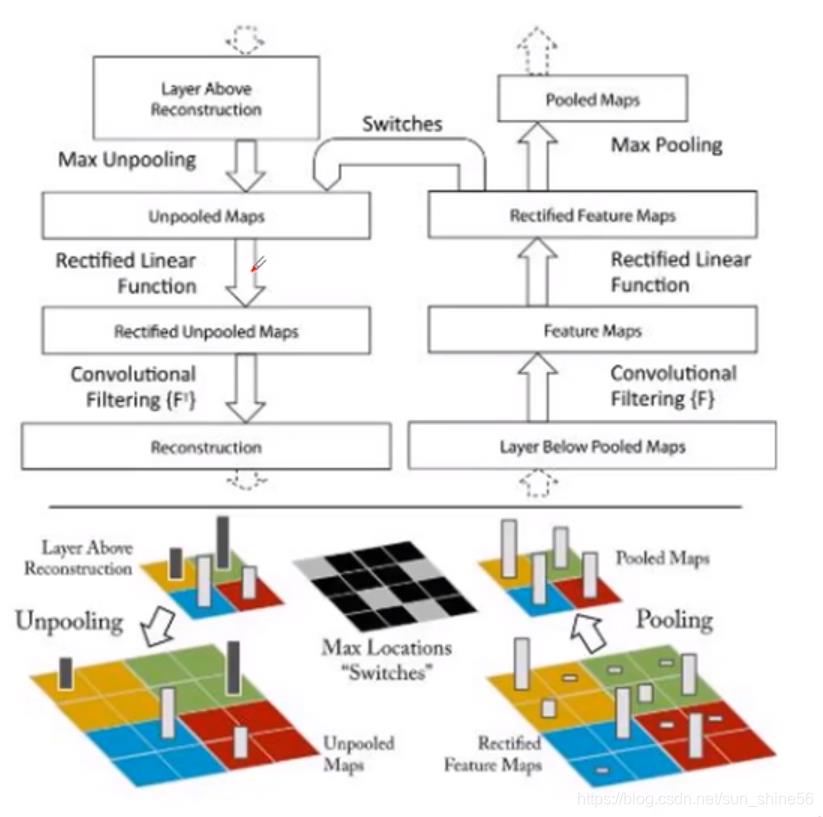
如图所示,右半边是我们一个正常的神经网络的数据流向:对于一副输入图像,我们通过pooling层来进行下采样,再通过卷积层进行特征提取,通过relu层来提升非线性表达能力。对于最后的输出结果,我们怎么把它还原成原始的图片呢?
实际上,如果我们想进行100%的还原是不可能的,因为每一次的pooling层都会丢失一些信息。因此我们在可视化的时候,更主要的是对它的特征的语义进行更高层次的分析。通过对输出层进行上采样,可以得到与我们原始图像大小一致的特征图。通过观察这些特征图,作者得出了这样的一些结论:
*特征分层次体系结构(就是我前面说的三层)
*深层特征更鲁棒(区分度高,不受图片微小的影响)
*深层特征收敛更慢
4.VGGNet
它由牛津大学计算机视觉组和Google Deepmind共同设计。主要是为了研究网络深度对模型准确度的影响,并采用小卷积堆叠的方式,来搭建整个网络。它的参数量达到了138M,整个模型的大小>500M.网络结构如下:
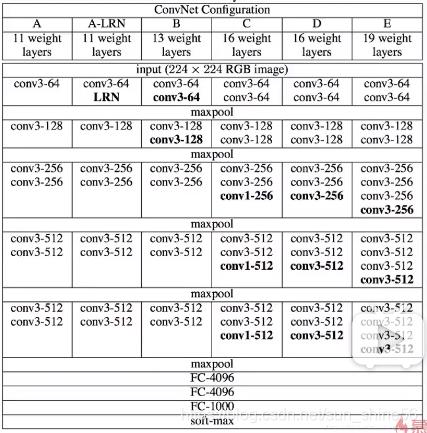
从上面的结构中我们可以看到,VGGNet的网络结构被分为11,13,16,19层。每层都包含了不同数量的卷积层(需要注意的是,每层卷积层之后都有激活层和池化层,只是由于长度限制没有在表中列出来),最后通过三个fc层来将我们的特征进行最后的向量化,最终得到一个1000维的向量,这个向量经过softmax之后,就会得到最终我们类别上的概率分布。而概率值最高的那个,就是我们所要分类的那个类别。
VGGNet的特点:
*网络深,卷积层多。结构哦更加规整,简单。
*卷积核都是3* 3的或者1* 1的,且同一层中channel的数量都是相同的。最大池化层全是2*
2。
每经过一个pooling层后,channel的数量会乘上2.
也就是说,每次池化之后,Feature Map宽高降低一半,通道数量增加一倍。VGGNet网络层数更多,结构更深,模型参数量更大。
VGGNet的意义:
*证明了更深的网络,能更好的提取特征。
*成为了后续很多网络的backbone。
5.GoogleNet/Inception v1
在设计网络结构时,不仅仅考虑网络的深度,也会考虑网络的宽度,并将这种结构定义为Inception结构(一种网中网(Network in Network)的结构,即原来的节点也是一个网络)。
值得一提的是,GoogleNet网络的参数量只有6.9兆,模型大小大约50M.
为什么GoogleNet网络的参数这么少呢?我们先来看一下它的基本单元的结构:
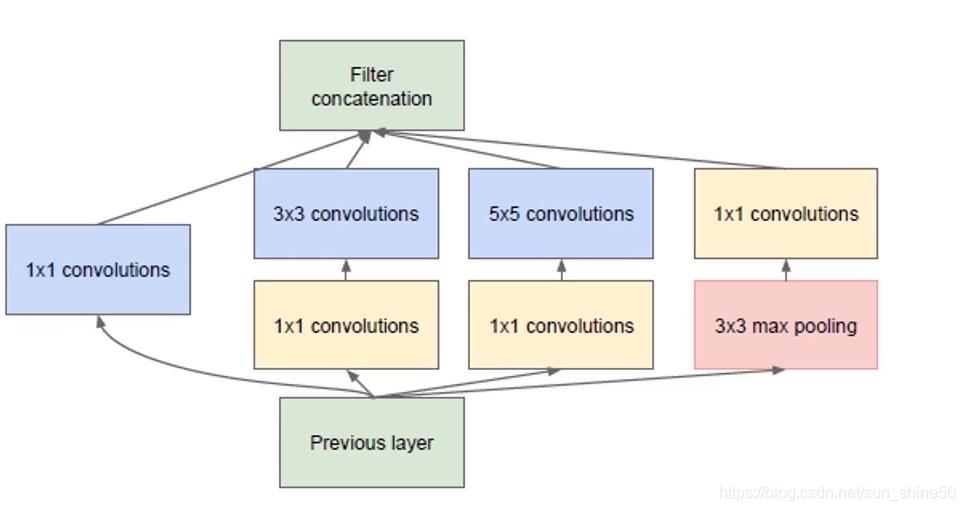
主要原因就是它有效的利用了1* 1 的卷积核。不同于VGGNet从上到下的类似于一个串的结构,Inception的结构表现为一个网中网的结构。也就是说,对于我们中间的一个隐藏层层,它的每个节点也都是一个卷积网络。
对于前一层传入进来的特征图,这层的每一个节点对它进行了1* 1 ,3* 3,5* 5的卷积和3* 3的pooling操作。其中值得一提的是,在3* 3和5* 5 的卷积操作之前,该网络用1* 1 的卷积核降低了输入层的channel的数量。
例如:我们的输入是一个56* 56 * 128维的这么一个特征(这时候128就是我们channel的数量)。我们通过一个1* 1 的卷积核,可以将通道数降为32,然后我们将它再输入到3* 3的卷积核中。大大减少了计算量。最后,我们将所有的Feature Map进行连接,最后得到这个层的输出。
在ZFNet的学习中我们知道,更深层的网络收敛的速度就越慢。在GoogleNet中,为了保证网络更深之后,能够哦收敛的比较好,它采用了两个loss来对网络参数进行调节,进而确保在网络变深之后,依然能够达到一个比较好的收敛效果。
这里需要解释一下什么叫网络宽度:网络深度指的是当前的这个网络一共有多少层,宽度则是说在同一层上channel的数量。
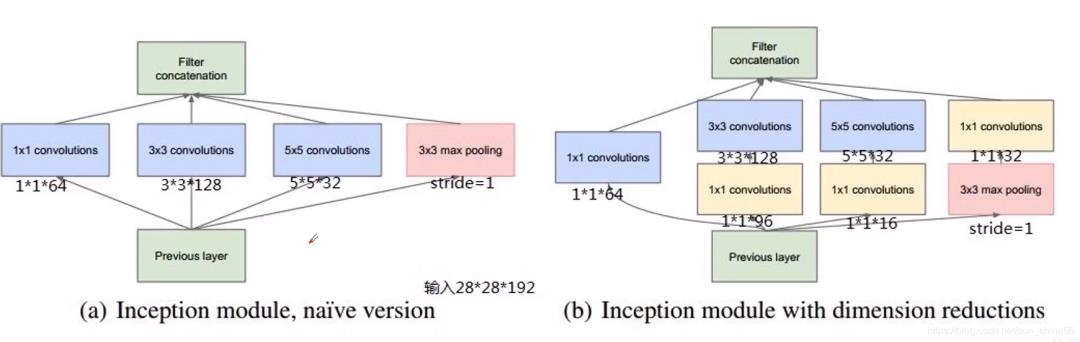
这里我们举了一个例子,来说明如何通过1* 1 的卷积核来进行计算量的一个节省,以及参数规模的一个降低。大家自行体会。
6.Inception v2/v3
在提出了Inception v1之后,google又提出了Inception v2/v3/v4.在前面介绍视觉感受的时候,我们曾经说过,一个大的卷积核可以由多个小的卷积核来替代。在v2/v3中,他们有效的利用了这个知识。在Inceptiion v2中,伟大的作者们通过两层3* 3的卷积核代替掉了5* 5的卷积核。而在Inception v3中,更是桑心病狂 别出心裁的用n* 1 + 1* n的卷积核代替了n* n的卷积核。
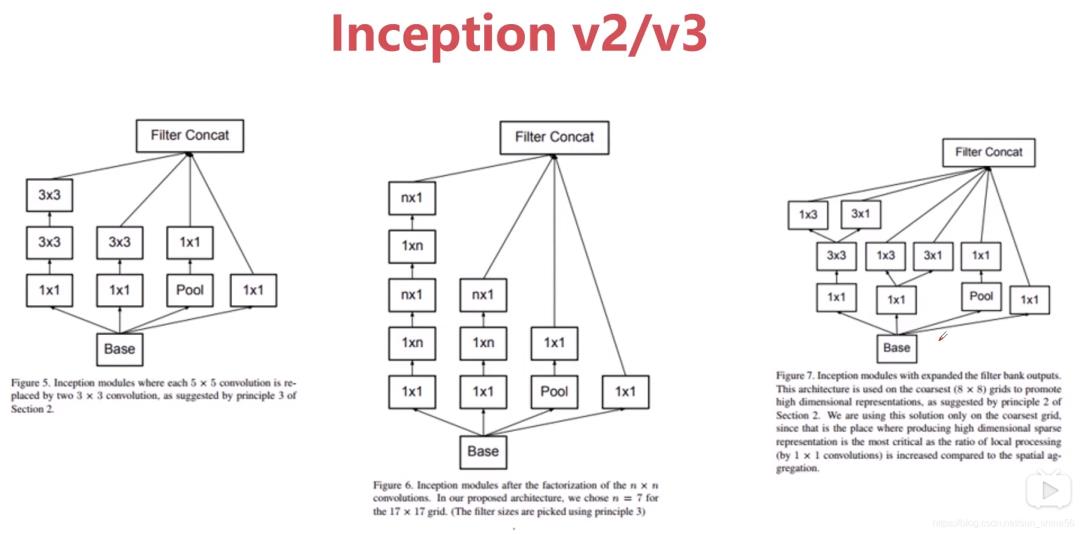
通过这样的操作,我们能够实现什么样的效果呢?
*参数量降低,计算量减少。
*网络变深,网络非线性表达能力更强(因为在每一个卷积层后面都可以增加一个激活层)
要注意的是,在实验中伟大的先行者们发现,并不是拆分都能达到很好的效果。卷积的拆分最好是用在中间的部分,不要在图像的开始就进行这样的拆分。
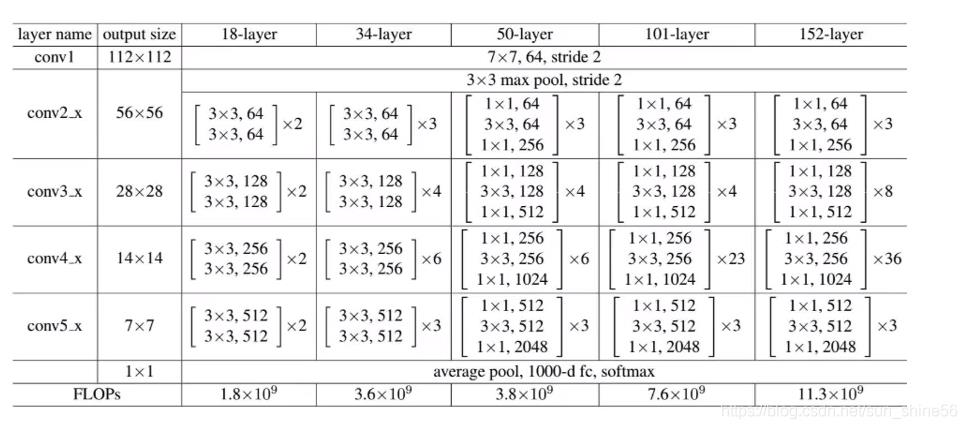
7.ResNet
它是在2015年,由何凯明团队提出,引入了跳连的结构来防止梯度消失的问题,进而可以进一步加大网络深度。它的结构如下所示:
跳连的结构如下所示:
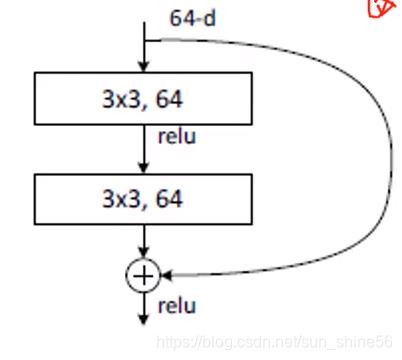
可以发现,其他的网络中,都是从上到下的串联的结构 ,而resnet网络则是跳连结构,它的意思是将输入特征直接传输到输出层,和经过卷积之后的特征相加,共同组成输出层的一部分。
那么,为什么通过跳连结构就可以加深网络的深度呢?在VGG网络中,我们知道当网络深度达到一定界限的时候,在训练中就较难收敛。较难收敛的原因就是随着网络深度的加深,产生了梯度消失的问题。
什么是梯度消失呢?有基础的人应该知道,卷积神经网络在进行BP时,都是通过梯度来计算权重修改量的。而梯度的计算遵循的是链式法则,即一个参数的梯度是多个梯度相乘之后的结果。
假如每个梯度都小于1的话,那么,x1 * x2* x3* x4…,当n趋于无穷的时候,limxn=0,即梯度消失。假如每个梯度都大于1的话,那么,x1 * x2 x3 * x4…,当n趋于无穷的时候,limxn=正无穷,即梯度爆炸。(这里的n其实就是卷积的层数)
所以理论上来说,伴随着网络的加深,我们可以提取到更好的特征,但是网络的参数是非常难以调节的,因为这时候我们求解出来的梯度是没办法来调节参数的。而resnet通过跳连的结构,就可以缓解这个问题。
我们可以很清楚的从跳连结构示意图中看到,加入了跳连结构之后,并没有增加模型的参数量,尽管它改变了网络结构。
从ResNet的网络结构中我们可以发现,它在一开始时设置卷积核大小为7 7,这是因为一开始的时候我们的输入图像的channel只有3,与7* 7的卷积核进行计算的话并不会增加多少计算量。而在ResNet网络的最后,伟大的作者们又一次别出心裁,用average pool层代替了全连接层。这一手操作也是大大的降低了参数量和计算量。因为我们知道,全连接层的参数多,且计算最为复杂,在VGG中,全连接层的参数量占到了总参数量的80%。而pooling层并没有参数。
接下来我们来讨论一下,为什么ResNet网络可以缓解梯度消失的问题呢?跳连结构实际上也被称为恒等映射:H(x)=F(x)+x。
当F(x)=0时,H(x)=x,这就是所谓的恒等映射。这个跳连的这根线,可以实现差分放大的效果,将梯度放大,来缓解梯度的消失。
举个例子,假设F(x)=2x,当x从5变化成为5.1时,F(x)从10变为10.2.如果这时候求F(x)的导数的话,公式为(10.2-10)/(5.1-5)=2.而如果变成H(x)的话,导数为(10.2+5.1-(10.0+5))/(5.1-5)=3.这样就放大了导数,即梯度。
在ResNet中有两种跳连结构:
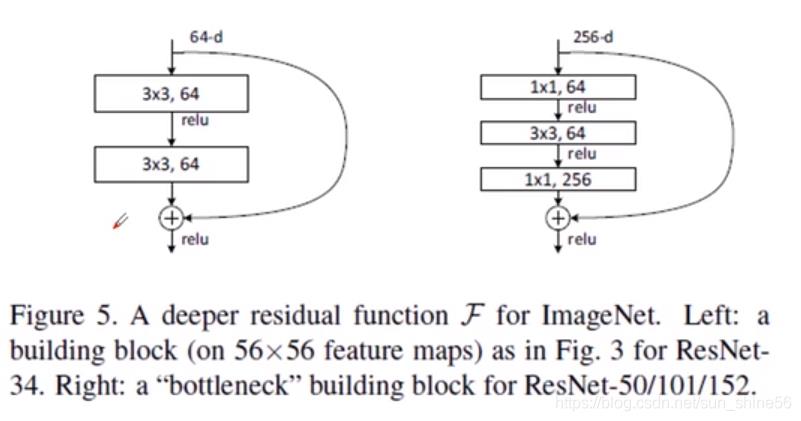
左边的是当层数较小时,不用1* 1的卷积核来降低参数量和计算量,后面的是在50,101,152层的网络中,用1* 1 的卷积核来降低参数量和计算量。
在ResNet中,除了跳连结构之外,它还采用了BatchNormalization批归一化来对数据scale和分布进行约束,同时BN层也可以进行简单的正则化,提高网络抗过拟合能力(每个卷积之后配合一个BN层)。
ResNet的设计特点:
*核心单元简单堆叠。
*跳连结构解决网络梯度消失问题。
*Average Pooling层代替fc层。
*BN层加快网络训练速度和收敛时的稳定性。
*加大网络深度,提高模型的特征抽取能力。
P2
卷积神经网络结构对比
【END】
版权声明
本文内容采编自极智能,版权归原作者所有,沣云平台不拥有其著作权,亦不承担相应法律责任。如果本文涉及版权问题,请联系工作人员删除,感谢。
往期 · 推荐
以上是关于CNN发展史及其网络模型简介的主要内容,如果未能解决你的问题,请参考以下文章
[人工智能-深度学习-21]:卷积神经网络CNN -- 多维输入的神经元模型及其本质:一维矩阵的点乘