深度学习不是万灵药!神经网络3D建模其实只是图像识别?
Posted 机器学习研究组订阅号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习不是万灵药!神经网络3D建模其实只是图像识别?相关的知识,希望对你有一定的参考价值。
随着深度学习的大热,许多研究都致力于如何从单张图片生成3D模型。但近期一项研究表明,几乎所有基于深度神经网络的3D中重建工作,实际上并不是重建,而是图像分类。深度学习并不是万能的!
深度学习并不是万灵药。
近几年,随着深度学习的大热,许多研究攻克了如何从单张图片生成3D模型。从某些方面似乎再次验证了深度学习的神奇——doing almost the impossible。
但是,最近一篇文章却对此提出了质疑:几乎所有这些基于深度神经网络的3D重建的工作,实际上并不是进行重建,而是进行图像分类。
https://arxiv.org/pdf/1905.03678.pdf
在这项工作中,研究人员建立了两种不同的方法分别执行图像分类和检索。这些简单的基线方法在定性和定量上都比最先进的方法产生的结果要更好。
正如伯克利马毅教授评价:

几乎所有这些基于深度神经网络的3D重建的工作(层出不穷令人眼花缭乱的State of the Art top conferences 论文),其实还比不上稍微认真一点的nearest neighbor baselines。没有任何工具或算法是万灵药。
至少在三维重建问题上,没有把几何关系条件严格用到位的算法,都是不科学的——根本谈不上可靠和准确。
基于对象(object-based)的单视图3D重建任务是指,在给定单个图像的情况下生成对象的3D模型。

如上图所示,推断一辆摩托车的3D结构需要一个复杂的过程,它结合了低层次的图像线索、有关部件结构排列的知识和高层次的语义信息。
研究人员将这种情况称为重建和识别:
重构意味着使用纹理、阴影和透视效果等线索对输入图像的3D结构进行推理。
识别相当于对输入图像进行分类,并从数据库中检索最合适的3D模型。
虽然在其它文献中已经提出了各种体系结构和3D表示,但是用于单视图3D理解的现有方法都使用编码器——解码器结构,其中编码器将输入图像映射到潜在表示,而解码器执行关于3D的非平凡(nontrivial)推理,并输出空间的结构。
为了解决这一任务,整个网络既要包含高级信息,也要包含低级信息。
而在这项工作中,研究人员对目前最先进的编解码器方法的结果进行了分析,发现它们主要依靠识别来解决单视图3D重建任务,同时仅显示有限的重建能力。
为了支持这一观点,研究人员设计了两个纯识别基线:一个结合了3D形状聚类和图像分类,另一个执行基于图像的3D形状检索。
在此基础上,研究人员还证明了即使不需要明确地推断出物体的3D结构,现代卷积网络在单视图3D重建中的性能是可以超越的。
在许多情况下,识别基线的预测不仅在数量上更好,而且在视觉上看起来更有吸引力。
研究人员认为,卷积网络在单视图3D重建任务中是主流实验程序的某些方面的结果,包括数据集的组成和评估协议。它们允许网络找到一个快捷的解决方案,这恰好是图像识别。
实验基于现代卷积网络,它可以从一张图像预测出高分辨率的3D模型。
方法的分类是根据它们的输出表示对它们进行分类:体素网格(voxel grids)、网格(meshes)、点云和深度图。为此,研究人员选择了最先进的方法来覆盖主要的输出表示,或者在评估中已经清楚地显示出优于其他相关表示。
研究人员使用八叉树生成网络(Octree Generating Networks,OGN)作为直接在体素网格上预测输出的代表性方法。
与早期使用这种输出表示的方法相比,OGN通过使用八叉树有效地表示所占用的空间,可以预测更高分辨率的形状。
还评估了AtlasNet作为基于表面的方法的代表性方法。AtlasNet预测了一组参数曲面,并在操作这种输出表示的方法中构成了最先进的方法。它被证明优于直接生成点云作为输出的唯一方法,以及另一种基于八叉树的方法。
最后,研究人员评估了该领域目前最先进的Matryoshka Networks。该网络使用由多个嵌套深度图组成的形状表示,,这些深度图以体积方式融合到单个输出对象中。
对于来自AtlasNet的基于IoU的表面预测评估,研究人员将它们投影到深度图,并进一步融合到体积表示。 对于基于表面的评估指标,使用移动立方体算法从体积表示中提取网格。
研究人员实现了两个简单的基线,仅从识别的角度来处理问题。
第一种方法是结合图像分类器对训练形状进行聚类;第二个是执行数据库检索。
在聚类方面的基线中,使用K-means算法将训练形状聚类为K个子类别。
在检索基线方面,嵌入空间由训练集中所有3D形状的两两相似矩阵构造,通过多维尺度将矩阵的每一行压缩为一个低维描述符。
研究人员根据平均IoU分数对所有方法进行标准比较。
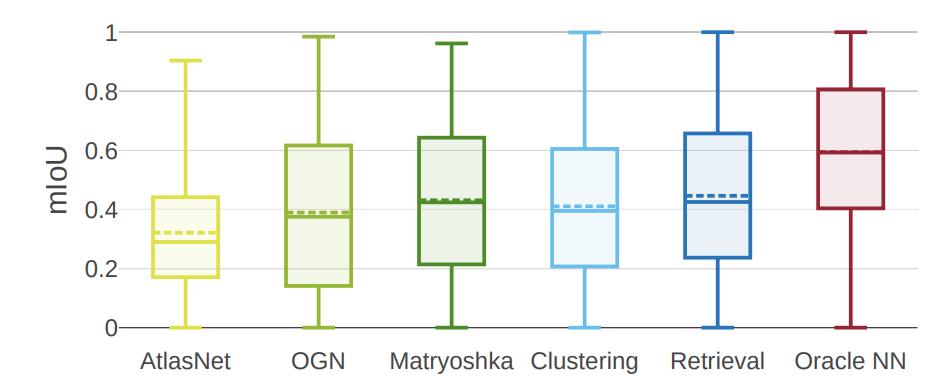
研究人员发现,虽然最先进的方法有不同体系结构的支持,但在执行的时候却非常相似。
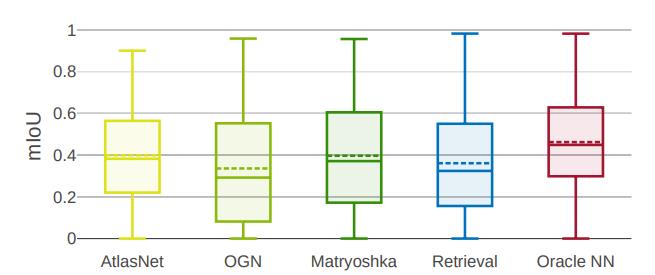
有趣的是,检索基线是一种纯粹的识别方法,在均值和中位数IoU方面都优于所有其他方法。简单的聚类基线具有竞争力,性能优于AtlasNet和OGN。
但研究人员进一步观察到,一个完美的检索方法(Oracle NN)的性能明显优于所有其他方法。值得注意的是,所有方法的结果差异都非常大(在35%到50%之间)。
这意味着仅依赖于平均IoU的定量比较不能提供这种性能水平的全貌。 为了更清楚地了解这些方法的行为,研究人员进行了更详细的分析。
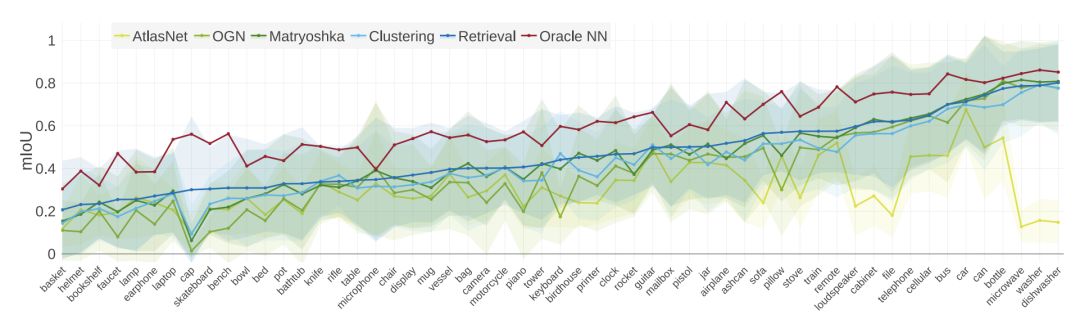
每类mIoU比较。
总的来说,这些方法在不同的类之间表现出一致的相对性能。检索基线为大多数类生成最佳重构。所有类和方法的方差都很大。
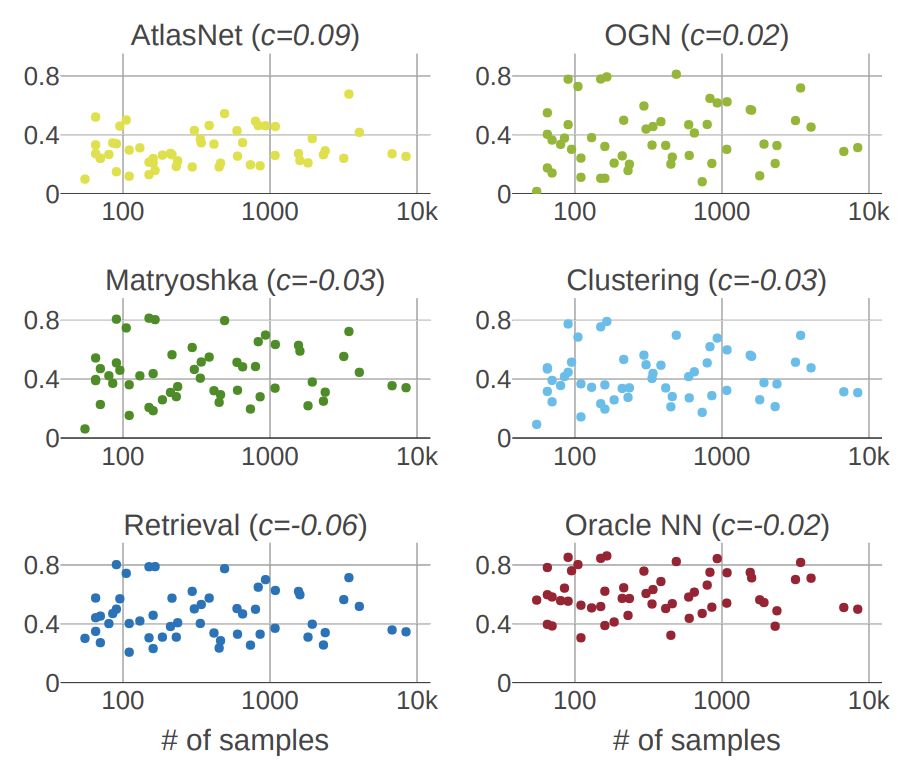
mIoU与每个类的训练样本数量。
研究人员发现一个类的样本数量和这个类的mIoU分数之间没有相关性。所有方法的相关系数c均接近于零。
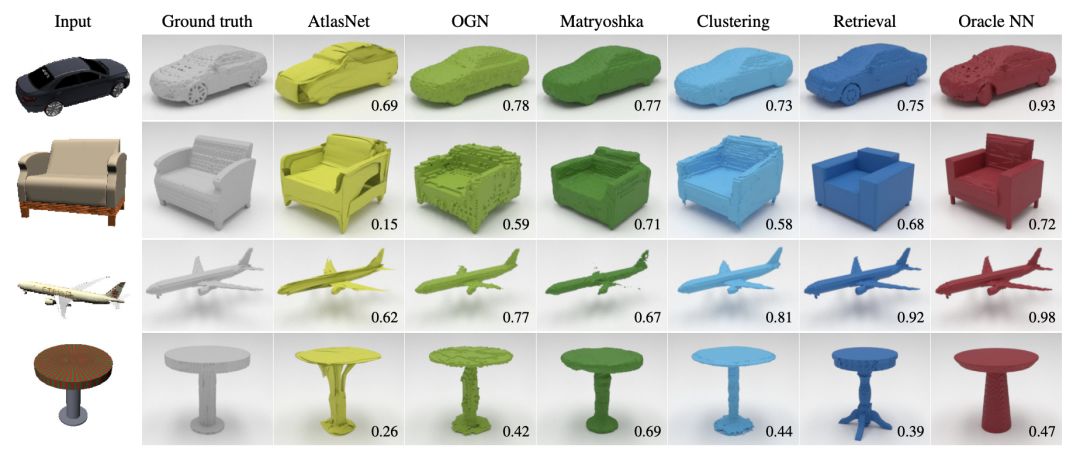
定性的结果
聚类基线产生的形状质量与最先进的方法相当。 检索基线通过设计返回高保真形状,但细节可能不正确。 每个样本右下角的数字表示IoU。
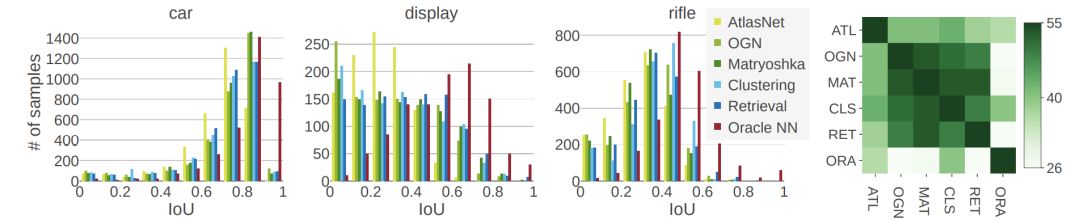
左:为所选类分配IoU。 基于解码器的方法和显式识别基线的类内分布是类似的。 Oracle NN的发行版在大多数类中都有所不同。 右图:成对Kolmogorov-Smirnov检验未能拒绝两个分布的无效假设的类数的热图。
参照系的选择
我们尝试使用视角预测网络对聚类基线方法进行扩展,该方法将重点回归摄像头的方位角和仰角等规范框架,结果失败了,因为规范框架对每个对象类都有不同的含义,即视角网络需要使用类信息来解决任务。我们对检索基线方法进行了重新训练,将每个训练视图作为单独样本来处理,从而为每个单独的对象提供空间。
量度标准
平均IoU通常在基准测试中被用作衡量单视图图像重建方法的主要量化指标。如果将其作为最优解的唯一衡量指标,就可能会出现问题,因为它在对象形状的质量值足够高时才能有效预测。如果该值处于中低水平,表明两个对象的形状存在显着差异。

如上图所示,将一个汽车模型与数据集中的不同形状的对象进行了比较,只有 IoU分数比较高(最右两张图)时才有意义,即使IoU=0.59,两个目标可能都是完全不同的物体,比较相似度失去了意义。
倒角距离(Chamfer distance)

如上图所示,两者目标椅子与下方的椅子的下半部分完美匹配,但上半部分完全不同。但是根据得分,第二个目标要好于第一个。由此来看,倒角距离这个量度会被空间几何布局显著干扰。为了可靠地反映真正的模型重建性能,好的量度应该具备对几何结构变化的高鲁棒性。
F-score
我们绘制了以观察者为中心的重建方式的F分数的不同距离阈值d(左)。在 d =重建体积边长的2%的条件下,F分数绝对值与当前范围的 mIoU分数相同,这并不能有效反映模型的预测质量。
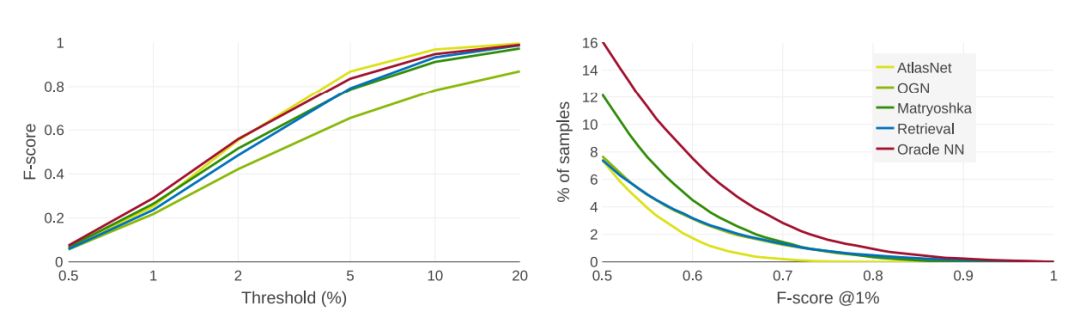
因此,我们建议将距离阈值设为重建模型体积边长的1%以下来考察F值。如上图(右)中所示,在阈值d = 1%时,F分数为0.5以上。只有一小部分模型的形状被精确构建出来,预设任务仍然远未解决。我们的检索基线方法不再具有明显的优势,进一步表明使用纯粹的识别方法很难解决这个问题。
现有的基于CNN的方法在精度上表现良好,但丢失了目标的部分结构
在这项研究中,研究人员通过重建和识别来推断单视图3D重建方法的范围。
工作展示了简单的检索基线优于最新、最先进的方法。分析表明,目前最先进的单视图3D重建方法主要用于识别,而不是重建。
研究人员确定了引起这种问题的一些因素,并提出了一些建议,包括使用以视图为中心的坐标系和鲁棒且信息量大的评估度量(F-score)。
另一个关键问题是数据集组合,虽然问题已经确定,但没有处理。研究人员正努力在以后的工作中纠正这一点。
参考链接:
https://arxiv.org/pdf/1905.03678.pdf
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会
以上是关于深度学习不是万灵药!神经网络3D建模其实只是图像识别?的主要内容,如果未能解决你的问题,请参考以下文章