ResNet:用于图像识别的深度残差网络
Posted 计算机视觉知识星球
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ResNet:用于图像识别的深度残差网络相关的知识,希望对你有一定的参考价值。
文章目录
4.1 ImageNet 分类
4.2 CIFAR-10与分析
4.3 在PASCAL和MS COCO上的目标检测
3.1 残差学习
3.2 通过快捷方式进行恒等映射
3.3 网络结构
3.4 应用
摘要
1. 介绍
2. 相关工作
3. 深度残差学习
4. 实验
前言:
为了让读者有更好的阅读体验,我对排版上进行了如下改进:
论文重点内容用红色字体显示
每一章节段与段之间用空白行隔开
对于一些专业词汇保留原译,不予翻译
原文中的引用,我依然保留。想查看引用来源的盆友请参考原论文附录:《Deep Residual Learning for Image Recognition》
温馨提示:ResNet的实战教程我也将马上更新,想要学习的盆友,可关注我的博客动态。
摘要
一般来说,更深的神经网络更难训练。因此本文提出了一种残差学习框架,以简化对更深网络的训练。该方法显式地将层重新配置为参考输入层的学习残差函数,而不是学习非参考函数。本文提供了充分的经验证据,这些证据表明,残差网络易于深度验证,并且从大大增加的深度中可以获得准确性。在ImageNet数据集上,评估深度最大为152层的残差网络-比VGG网络[41]深8倍,但仍具有较低的复杂度。这些残差网络的整体在ImageNet测试集上实现3.57%的误差。这是ILSVRC 2015分类任务的第一名。除此之外,本文还介绍了具有100和1000层的残差网络在CIFAR-10数据集上的分析。
1. 介绍
深度卷积神经网络[22,21]导致了图像分类的一系列突破[21,50,40]。深度网络自然地以端到端的多层方式集成了低/中/高级特征[50]和分类器,并且特征的“级别”可以通过堆叠的层数(深度)来丰富。最新证据[41,44]揭示了网络深度至关重要,在具有挑战性的ImageNet数据集[36]上的领先结果[41,44,13,16]都利用了“非常深”的模型[41], 深度为十六[41]到三十[16]。许多其他非常普通的视觉识别任务[8、12、7、32、27]也从非常深的模型中受益匪浅。
当更深层的网络能够开始聚合时,就会出现降级问题:随着网络深度的增加,精度达到饱和(这可能不足为奇),然后迅速降级。出乎意料的是,这种降级不是由过度拟合引起的,这在[11,42]中提到过,并且由我们的实验完全可以验证,将更多层添加到适当深度的模型中会导致更高的训练误差。图1显示了一个典型示例。图1. CIFAR-10数据集上,20层和56层“普通”网络的训练错误率(左)、测试错误率(右)。 较深的网络具有较高的训练错误,从而导致测试错误。
训练准确性的下降表明并非所有系统都同样(通过增加深度)容易优化。让我们考虑一个较浅的体系结构,以及一个较深的体系结构,它在其上添加了更多层。通过构建更深层的模型可以找到解决方案:添加的层是恒等映射,其他层是从学习的浅层模型中复制的。此构造解决方案的存在表明,较深的模型不会比浅模型产生更高的训练误差。但是实验表明,我们现有的求解器无法找到比构造的解决方案好或更好的解决方案,或者无法在可行的时间内找到解决方案。
在本文中,我们通过引入深度残差学习框架来解决退化问题。而不是希望每个堆叠的层都直接适合所需的基础映射,我们明确让这些层适合残差映射。形式上,将所需的基础映射表示为H ( x ) H(x)H(x),我们让堆叠的非线性层适合 F ( x ) : = H ( x ) − x F(x):= H(x)-xF(x):=H(x)−x 的另一个映射。原始映射将重铸为F ( x ) + x F(x) + xF(x)+x。我们假设优化残差映射比优化原始未引用映射要容易。极端地,如果恒等映射是最佳的,则将残差推到零比通过非线性层的堆栈拟合恒等映射要容易。
F ( x ) + x F(x)+ xF(x)+x 的公式可通过具有“快捷连接(shortcut connections)”的前馈神经网络来实现(图2)。快捷连接[2、34、49]是跳过一层或多层的连接。在我们的例子中,快捷方式连接仅执行恒等映射(identity mapping),并将其输出添加到堆叠层的输出中(图2)。恒等快捷方式连接既不增加额外的参数,也不增加计算复杂度。整个网络仍然可以通过SGD反向传播进行端到端训练,并且可以使用通用库(例如Caffe [19])轻松实现,而无需修改求解器。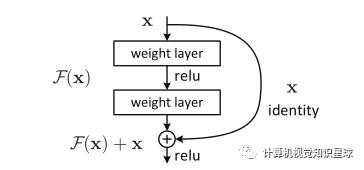 图2. 残差学习:构建基块
图2. 残差学习:构建基块
我们在ImageNet [36]上进行了全面的实验,以显示退化问题并评估我们的方法。 我们证明:1)我们极深的残差网络易于优化,但是当深度增加时,对应的“普通”网络(简单地堆叠层)显示出更高的训练误差;2)我们的深层残差网络可以通过大大增加深度来轻松享受精度提升,从而产生比以前的网络更好的结果。
在CIFAR-10集上也显示了类似的现象[20],这表明这种有效的方法不仅仅适用于特定数据集。我们在此数据集上展示了经过成功训练的100层以上的模型,并探索了1000层以上的模型。
在ImageNet分类数据集[36]上,我们通过极深的残差网获得了出色的结果。我们的152层残差网络是ImageNet上提出的最深的网络,同时其复杂度仍低于VGG网络[41]。我们的方法在ImageNet测试集上的Top-5错误率为3.57%,并在ILSVRC 2015分类竞赛中获得第一名。极深的表示形式在其他识别任务上也具有出色的泛化性能,使我们在ILSVRC和COCO 2015竞赛中进一步赢得了第一名:ImageNet检测,ImageNet定位,COCO检测和COCO分割。有力的证据表明,残差学习原理是通用的,我们希望它适用于其他视觉和非视觉问题。
2. 相关工作
残差表示。在图像识别中,VLAD [18]是通过相对于字典的残差矢量进行编码的表示,Fisher Vector [30]可以公式化为VLAD的概率版本[18]。它们都是用于图像检索和分类的有力的浅层表示[4,48]。对于矢量量化,编码残差矢量[17]比编码原始矢量更有效。
在低级视觉和计算机图形学中,为了求解偏微分方程(PDE),广泛使用的Multigrid方法[3]将系统重新形成为多个尺度的子问题,其中每个子问题负责较粗和较细之间的剩余解。规模。Multigrid的替代方法是分层基础预处理[45,46],它依赖于表示两个尺度之间残差矢量的变量。已经证明[3,45,46],这些求解器收敛速度比标准求解器快得多,而标准求解器并未意识到解决方案的剩余性质。这些方法表明,良好的重构或预处理可以简化优化过程。
快捷连接。导致快捷连接[2、34、49]的实践和理论已经研究了很长时间。训练多层感知器(MLP)的早期实践是添加从网络输入连接到输出的线性层[34,49]。在[44,24]中,一些中间层直接连接到辅助分类器,以解决消失/爆炸梯度(比如GoogLeNet)。[39,38,31,47]的论文提出了通过快捷连接实现居中层响应,梯度和传播误差居中的方法。在[44]中,“起始”层由一个快捷分支和一些更深的分支组成。
在我们工作的同时,“高速网络” [42、43]提供了具有选通功能[15]的快捷连接。与我们的不带参数的恒等快捷方式相反,这些门取决于数据并具有参数。当封闭的快捷方式“关闭”(接近零)时,高速网中的图层表示非残留功能。相反,我们的公式总是学习残差函数。我们的恒等快捷方式永远不会被关闭,所有信息始终都会通过传递,还有其他剩余功能需要学习。另外,高速网络还没有显示出深度极大增加(例如超过100层)的精度。
3. 深度残差学习
3.1 残差学习
让我们将 H ( x ) H(x)H(x) 视为由一些堆叠层(不一定是整个网络)拟合的基础映射,其中x表示这些层中第一层的输入。如果假设多个非线性层可以渐近逼近复杂函数,则等效于假设它们可以渐近逼近残差函数,即H ( x ) − x H(x)-xH(x)−x(假设输入和输出的维数相同) 。因此,我们没有让堆叠的层近似为H ( x ) H(x)H(x),而是明确地让这些层近似为残差函数F ( x ) : = H ( x ) − x F(x):= H(x)-xF(x):=H(x)−x。因此,原始函数变为F ( x ) + x F(x) + xF(x)+x。尽管两种形式都应能够逐渐地逼近所需的函数(如假设),但学习的难易程度可能有所不同。
这种重新定义是由与退化问题有关的违反直觉的现象引起的(图1,左)。正如我们在引言中讨论的那样,如果可以将添加的层构造为恒等映射,则较深的模型的训练误差应不大于其较浅的模型的训练误差。退化问题表明,求解器可能难以通过多个非线性层来逼近恒等映射。利用残差学习重新形成,如果恒等映射是最佳的,则求解器可以简单地将多个非线性层的权重逼近零以逼近恒等映射。
在实际情况下,恒等映射不可能达到最佳状态,但是我们的重新制定可能有助于解决问题。如果最优函数比零映射更接近于一个恒等式,那么求解器应该参考恒等式来查找扰动,而不是学习一个新的函数。我们通过实验(图7)表明,学习到的残差函数通常具有较小的响应,这表明恒等映射提供了合理的预处理。
3.2 通过快捷方式进行恒等映射
我们对每几个堆叠的层采用残差学习。构建块如图2所示。形式上,在本文中,我们考虑定义为: y = F ( x , W i ) + x y = F(x,{W_i}) + xy=F(x,Wi)+x (1)
这里的x和y是所考虑层的输入和输出向量。函数F ( x , W i ) F(x,{W_i})F(x,Wi)表示要学习的残差映射。对于图2中具有两层的示例,F = W 2 σ ( W 1 x ) F = W_2σ(W_1 x)F=W2σ(W1x),其中σ表示ReLU 函数[29],并且为了简化符号省略了偏置。F + x F + xF+x操作通过快捷连接和逐元素加法执行。在加法之后我们采用第二个非线性度(即σ(y),见图2)。
公式(1)中的快捷连接既没有引入额外的参数,也没有引入计算的复杂性。这不仅在实践中具有吸引力,而且在我们比较普通网络和残差网络时也很重要。我们可以公平地比较同时具有相同数量的参数,深度,宽度和计算成本(除了可忽略的元素方式加法)的普通/残差网络。
x和F的尺寸在等式(1)中必须相等。如果不是这种情况(例如,在更改输入/输出通道时),我们可以通过快捷连接执行线性投影W s W_sWs以匹配尺寸:
y = F ( x , W i ) + W s x y = F(x,{ W_i })+ W_s xy=F(x,Wi)+Wsx (2)
我们也可以在等式(1)中使用平方矩阵W s W_sWs。但是我们将通过实验证明,恒等映射足以解决降级问题并且很经济,因此W s W_sWs仅在匹配尺寸时使用。
残差函数F的形式是灵活的。本文中的实验涉及一个具有两层或三层的函数F(图5),而更多的层是可能的。但是,如果F仅具有单层,则等式(1)类似于线性层:
y = W 1 x + x y = W_1 x + xy=W1x+x,对此我们没有观察到优势。
我们还注意到,尽管为简化起见,上述符号是关于全连接层的,但它们也适用于卷积层。函数F ( x , W i ) F(x,{W_i})F(x,Wi)可以表示多个卷积层。对两个要素图逐个通道执行逐元素加法。
3.3 网络结构
我们已经测试了各种普通/残留网络,并观察到了一致的现象。为了提供讨论实例,我们描述了ImageNet的两个模型,如下所示。
普通网络。我们简单的基线(图3,中间)主要受到VGG网络原理的启发[41](图3,左)。 卷积层大多具有3×3滤镜,并遵循两个简单的设计规则:(i)对于相同的输出要素图大小,这些图层具有相同数量的滤镜;(ii)如果特征图的大小减半,则过滤器的数量将增加一倍,以保持每层的时间复杂度。我们直接通过步长为2的卷积层执行下采样。网络以全局平均池化层和带有softmax的1000路全连接层结束。在图3中,加重层的总数为34(中)。
值得注意的是,我们的模型比VGG网络[41]具有更少的卷积运算和更低的复杂度(图3,左)。我们的34层基准具有36亿个FLOP(乘法加法),仅占VGG-19(196亿个FLOP)的18%。
残差网络。在上面的普通网络的基础上,我们插入快捷方式连接(图3,右),将网络变成其对应的残差版本。当输入和输出的尺寸相同时,可以直接使用标识快捷方式(等式(1))(图3中的实线快捷方式)。当尺寸增加时(图3中的虚线快捷方式),我们考虑两个选项:(A)快捷方式仍然执行恒等映射,并为增加尺寸填充了额外的零项。此选项不引入任何额外的参数。(B)等式(2)中的投影快捷方式用于匹配尺寸(按1×1卷积完成)。对于这两个选项,当快捷方式遍历两种尺寸的特征贴图时,步长为2。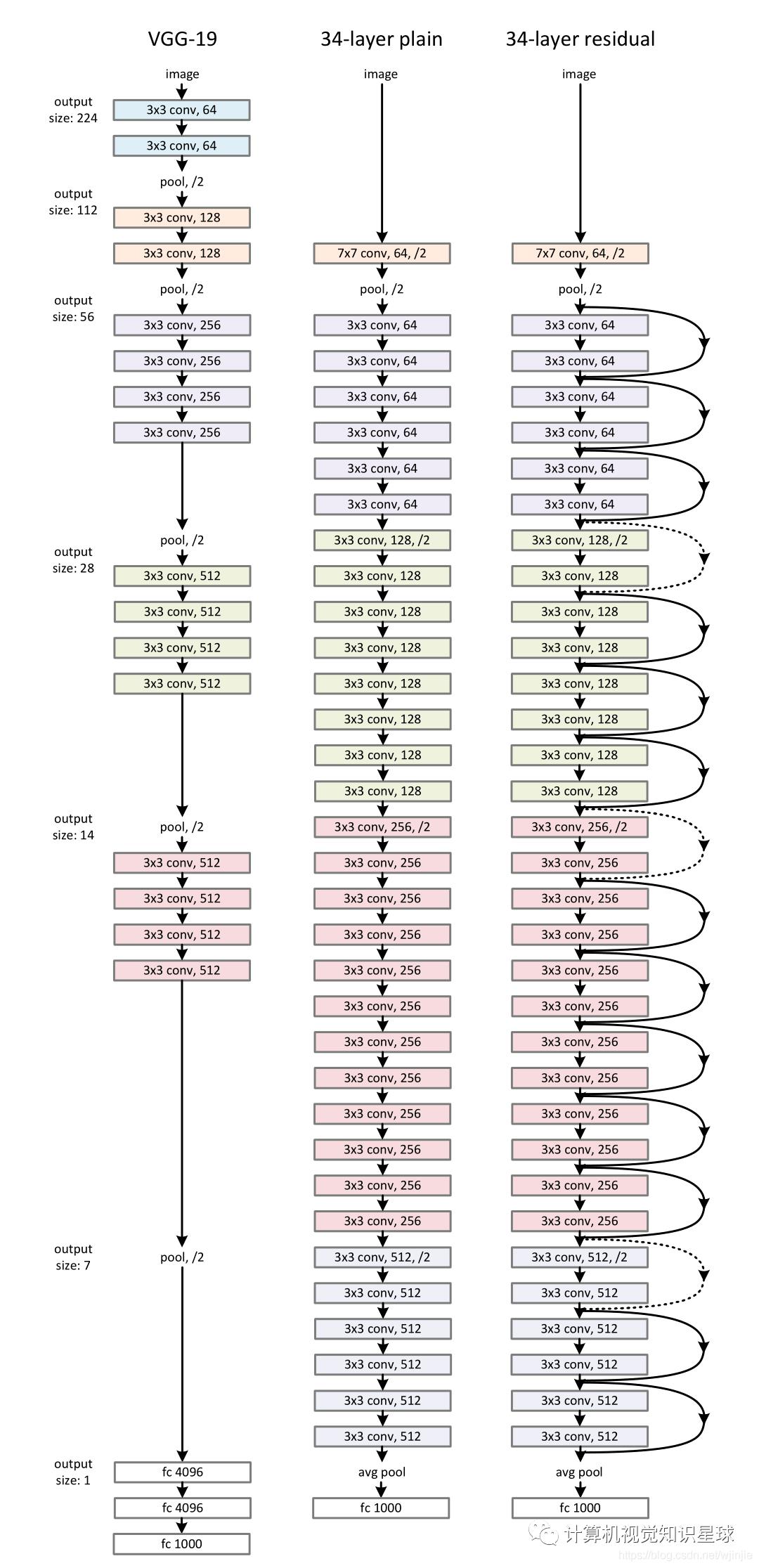
图3. ImageNet的示例网络架构。左图:作为参考的VGG-19模型[41](196亿个FLOP)。中:包含34个参数层(36亿个FLOP)的普通网络。右图:一个具有34个参数层的残差网络(36亿个FLOP)。虚线快捷方式会增加尺寸。表1显示了更多详细信息和其他变体。
3.4 应用
我们对ImageNet的实现遵循[21,41]中的做法。调整图像大小,并在[256,480]中随机采样其较短的一面,以进行比例增强[41]。从图像或其水平翻转中随机采样成224×224的裁剪大小,并减去每像素均值[21]。使用[21]中的标准颜色增强。在每次卷积之后和激活之前,紧接着[16],我们采用批归一化(BN)[16]。我们按照[13]中的方法初始化权重,并从头开始训练所有普通/残差网络。我们使用最小批量为256的SGD。学习率从0.1开始,当误差平稳时除以10,并且对模型进行了多达60×10 4次迭代的训练。我们使用0.0001的权重衰减和0.9的动量。我们不遵循[16]中的做法使用Dropout [14]。
在测试中,为了进行比较研究,我们采用了标准的10种crops测试方法[21]。为了获得最佳结果,我们采用[41,13]中的全卷积形式,并在多个尺度上对分数取平均(图像被调整大小,使得较短的边在{224,256,384,480,640}中)。
4. 实验
4.1 ImageNet 分类
我们在包含1000个类别的ImageNet 2012分类数据集[36]上评估了我们的方法。在128万个训练图像上训练模型,并在5万张验证图像上进行评估。我们还将在测试服务器报告的10万张测试图像上获得最终结果。我们评估了top-1和top-5的错误率。
普通网络。我们首先评估18层和34层的普通网络。34层的普通网络在图3中(中)。18层普通网具有类似的形式。有关详细架构,请参见表1。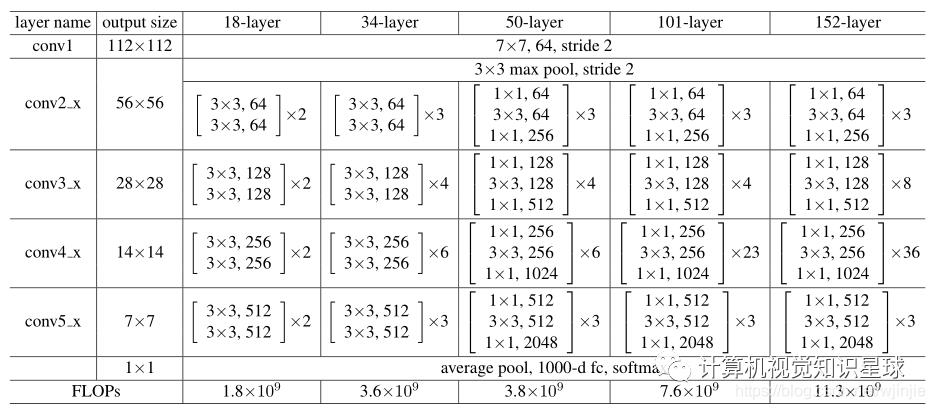 表1. ImageNet的体系结构。
表1. ImageNet的体系结构。
表2中的结果表明,较深的34层普通网比较浅的18层普通网具有更高的验证误差。为了揭示原因,在图4(左)中,我们比较了他们在训练过程中的训练/验证错误。我们已经观察到退化问题-尽管18层普通网络的解决方案空间是34层普通网络的子空间,但在整个训练过程中34层普通网络具有较高的训练误差。 表2. ImageNet验证集上的Top-1错误率(%,进行了十次裁剪测试)。
表2. ImageNet验证集上的Top-1错误率(%,进行了十次裁剪测试)。
ResNet与普通的ResNet相比没有额外的参数。图4显示了训练过程。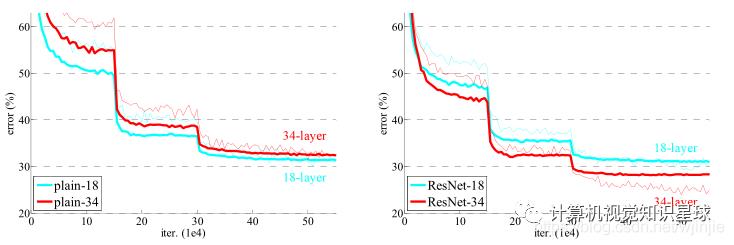 图4. 在ImageNet上的训练结果。细曲线表示
图4. 在ImageNet上的训练结果。细曲线表示训练误差,粗曲线表示中心裁剪的验证误差。左:18和34层的普通网络。右:18和34层的ResNet。在该图中,残差网络与普通网络相比没有额外的参数。
我们认为,这种优化困难不太可能是由梯度弥散引起的。这些普通网络使用BN [16]进行训练,可确保前向传播信号具有非零方差。我们还验证了向后传播的梯度具有BN的健康规范。因此,前向或反向传播信号都不会消失。实际上,34层普通网络仍然能够达到具有竞争力的精度(表3),这表明求解器在某种程度上可以工作。我们推测,很深的普通网络可能具有指数级的收敛速度,这会降低训练误差。将来将研究这种优化困难的原因。
残差网络。接下来,我们评估18层和34层残差网络(ResNets)。基线架构与上述普通网络相同,希望将快捷连接添加到图3(右)中的每对3×3卷积核中。在第一个比较中(右表2和图4),我们将恒等映射用于所有快捷方式,将零填充用于增加尺寸(选项A)。因此,与普通副本相比,它们没有额外的参数。
我们从表2和图4中获得了三个主要观察结果。首先,这种情况通过残差学习得以逆转34层ResNet优于18层ResNet(降低了2.8%)。更重要的是,34层ResNet表现出低得多的训练误差,并且可以推广到验证数据。这表明在这种情况下可以很好地解决退化问题,并且我们设法从增加的深度中获得准确性的提高。
其次,与普通的相比,34层ResNet将top-1错误减少了3.5%(表2),这是由于成功减少了训练错误(图4右与左)。这项比较验证了残差学习在极深系统上的有效性。
最后,我们还注意到18层普通/残差网络比较准确(表2),但是18层ResNet收敛更快(图4右与左)。当网“不是太深”(此处为18层)时,当前的SGD解算器仍然能够为纯网找到良好的解决方案。在这种情况下,ResNet通过在早期提供更快的收敛来简化优化。
恒等与投影捷径。我们已经证明,无参数的恒等快捷方式有助于训练。接下来,我们研究投影快捷方式(等式(2))。在表3中,我们比较了三个选项:(A)零填充快捷键用于增加尺寸,并且所有快捷键都没有参数(与表2和右图4相同);(B)投影快捷方式用于增加尺寸,其他快捷方式用于标识。(C)所有快捷方式都是投影。
表3显示,所有三个选项都比普通选项好得多。B稍好于A。我们认为这是因为A中的零填充维确实已经实现。CismarginallyB优于B,我们将此归因于许多(十三)投影快捷方式引入的额外参数。但是,A / B / C之间的细微差异表明,投影捷径对于解决降级问题并不是必不可少的。因此,在本文的其余部分中,我们不使用选项C来减少内存/时间的复杂性和模型大小。恒等快捷方式对于不增加下面介绍的瓶颈架构的复杂性尤其重要。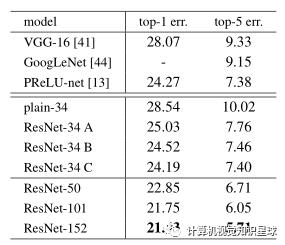 表3. ImageNet验证集上的错误率(%,10次裁剪测试)。VGG-16基于我们的测试。ResNet-50 / 101/152是选项B的选项,仅使用投影来增加尺寸。
表3. ImageNet验证集上的错误率(%,10次裁剪测试)。VGG-16基于我们的测试。ResNet-50 / 101/152是选项B的选项,仅使用投影来增加尺寸。
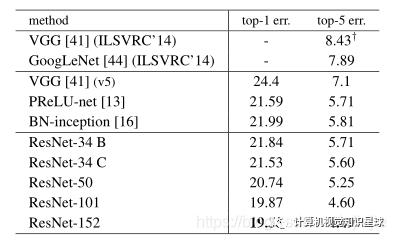 表4. ImageNet验证集上单模型结果的错误率(%)(测试集上报告的†除外)。
表4. ImageNet验证集上单模型结果的错误率(%)(测试集上报告的†除外)。
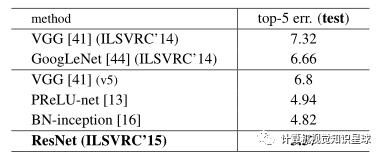 表5. 整体的错误率(%)。在ImageNet测试集上的Top-5错误率,并且由测试服务器报告。
表5. 整体的错误率(%)。在ImageNet测试集上的Top-5错误率,并且由测试服务器报告。
更深的瓶颈架构。接下来,我们将介绍ImageNet上的更深层网络。考虑到我们负担不起的训练时间,我们将构建模块修改为瓶颈设计。对于每个残差函数F FF,我们使用3层而不是2层的堆栈(图5)。 这三层分别是1×1、3×3和1×1卷积,其中1×1层负责减小然后增加(还原)尺寸,使3×3层成为输入/输出尺寸较小的瓶颈 。图5显示了一个示例,其中两种设计都具有相似的时间复杂度。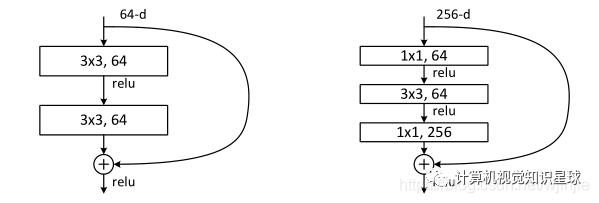 图5. ImageNet的更深的残差函数F FF。左:如图3中的ResNet34的构建块(在56×56特征图上)。右:ResNet-50 / 101/152的“瓶颈”构建基块。
图5. ImageNet的更深的残差函数F FF。左:如图3中的ResNet34的构建块(在56×56特征图上)。右:ResNet-50 / 101/152的“瓶颈”构建基块。
无参数标识快捷方式对于瓶颈体系结构特别重要。如果将图5(右)中的恒等快捷方式替换为投影,则可以显示时间复杂度和模型大小增加了一倍,因为快捷方式连接到两个高维端。因此,恒等快捷方式可以为瓶颈设计提供更有效的模型。
50层的残差网络:我们将3层瓶颈模块替换为34层网络中的每个2层模块,从而得到50层ResNet(表1)。我们使用选项B来增加尺寸。该模型具有38亿个FLOP。
101层和152层ResNet:我们通过使用更多的3层块来构建101层和152层ResNet(表1)。值得注意的是,尽管深度大大增加,但152层ResNet(113亿个FLOP)的复杂度仍然低于VGG-16/19网络(153.96亿个FLOP)。
50/101/152层ResNet比34层ResNet准确度高得多(表3和表4)。我们没有观察到退化问题,因此从深度的增加中获得了显着的精度提升。所有评估指标都证明了深度的好处(表3和表4)。
与最新方法的比较。在表4中,我们与以前的最佳单模型结果进行了比较。我们的基准34层ResNet获得了非常具有竞争力的准确性。我们的152层ResNet的单模型top-5验证错误为4.49%。这个单一模型的结果优于所有先前的整体结果(表5)。我们将六个不同深度的模型组合在一起以形成一个整体(提交时只有两个152层模型)。这导致测试集上3.57的top-5错误(表5)。此项获得了2015年ILSVRC的第一名。
4.2 CIFAR-10与分析
我们对CIFAR-10数据集[20]进行了更多研究,该数据集包含10个类别的5万张训练图像和1万张测试图像。我们介绍在训练集上训练的实验,并在测试集上进行评估。我们的重点是极度深度的网络的行为,而不是推动最先进的结果,因此,我们特意使用以下简单架构。
普通/残差体系结构遵循图3中的形式(中/右)。网络输入为32×32图像,每像素均值被减去。第一层是3×3卷积。然后,我们分别在大小为{32,16,8}的特征图上使用具有3×3卷积的6n层堆栈,每个特征图尺寸为2n层。卷积核的数量分别为{16,32,64}。二次采样是通过2个以上的卷积进行的。网络以全球平均池,10路全连接层和softmax结尾。总共有6n + 2个堆叠的加权层。下表总结了体系结构: 使用快捷方式连接时,它们将连接到成对的3×3层对(总共3n个快捷方式)。在此数据集上,我们在所有情况下都使用了恒等快捷方式(即选项A),因此我们的残差模型的深度,宽度和参数数量与普通模型完全相同。
使用快捷方式连接时,它们将连接到成对的3×3层对(总共3n个快捷方式)。在此数据集上,我们在所有情况下都使用了恒等快捷方式(即选项A),因此我们的残差模型的深度,宽度和参数数量与普通模型完全相同。
我们使用0.0001的权重衰减和0.9的动量,并在[13]和BN [16]中采用权重初始化,但是没有丢失。这些模型在两个GPU上的最小批量为128。我们以0.1的学习率开始,将其在32k和48k迭代中除以10,然后以64k迭代终止训练,这是由45k / 5k的火车/ val分配决定的。我们按照[24]中的简单数据增强进行训练:在每侧填充4个像素,并从填充的图像或其水平翻转中随机采样32×32的作物。为了进行测试,我们仅评估原始32×32图像的单个视图。
我们比较n = {3,5,7,9},得出20、32、44和56层网络。图6(左)显示了普通网络的行为。较深的平原网会增加深度,并且在深入时会表现出较高的训练误差。这种现象类似于ImageNet(图4,左)和MNIST(参见[42]),表明这种优化困难是一个基本问题。
图6(中)显示了ResNets的行为。同样类似于ImageNet的情况(图4,右),我们的ResNet设法克服了优化难题,并证明了深度增加时精度的提高。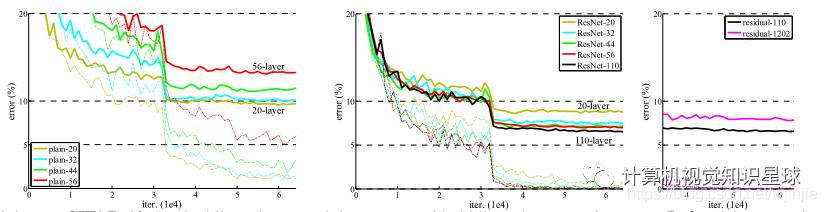 图6. 在CIFAR-10上的训练结果。虚线表示训练错误率,而粗线表示测试错误率。左:普通网络。Plain-110的错误高于60%,没有显示。中:ResNets。右:具有110和1202层的ResNet。
图6. 在CIFAR-10上的训练结果。虚线表示训练错误率,而粗线表示测试错误率。左:普通网络。Plain-110的错误高于60%,没有显示。中:ResNets。右:具有110和1202层的ResNet。
我们进一步探索n = 18导致的110层ResNet。在这种情况下,我们发现初始学习速率0.1太大了,无法开始收敛。因此,我们使用0.01来预训练,直到训练误差低于80%(约400次迭代),然后回到0.1并继续训练。学习时间表的其余部分如前所述。这个110层的网络可以很好地融合(图6,中间)。与其他深层和瘦网络(例如FitNet [35]和Highway [42])相比,它的参数更少(表6),但仍属于最新技术成果(6.43%,表6)。
层响应分析。图7显示了层响应的标准偏差(std)。响应是BN之后以及其他非线性(ReLU /加法)之前每个3×3层的输出。对于ResNet,此分析揭示了残差函数的响应强度。图7显示ResNet的响应通常比普通响应小。这些结果支持我们的基本动机(第3.1节),即与非残差函数相比,残差函数通常可能更接近于零。我们还注意到,更深的ResNet具有较小的响应幅度,如图7中ResNet-20、56和110的比较所证明的。当有更多层时,ResNets的单个层往往对信号的修改较少。
探索超过1000层的参数网络。我们探索了一个超过1000层的深度模型。我们将n设置为200,从而得出1202层网络,该网络如上所述进行了训练。我们的方法没有优化困难,并且这个1000层网络能够实现训练误差率<0.1%(图6,右)。其测试误差仍然相当不错(7.93%,表6)。
但是,在如此积极的深度模型上仍然存在未解决的问题。尽管这两个1202层网络的训练误差相似,但其测试结果却比我们的110层网络的测试结果差。我们认为这是由于过度拟合。对于这个小的数据集,1202层网络可能会不必要地大(19.4M)。使用强正则化(例如maxout [10]或dropout [14])可在此数据集上获得最佳结果([10、25、24、35])。在本文中,我们不使用maxout / dropout,而只是通过设计通过深度和精简架构强加正则化,而不会分散对优化困难的关注。但是,结合更强的正则化可能会改善结果,我们将在以后进行研究。
4.3 在PASCAL和MS COCO上的目标检测
我们的方法在其他识别任务上具有良好的泛化性能。表7和8显示了PASCAL VOC 2007和2012 [5]和COCO [26]上的对象检测基线结果。我们采用Faster R-CNN [32]作为检测方法。在这里,我们对用ResNet-101替换VGG-16 [41]的改进感兴趣。使用这两种模型的检测实现方式(请参阅附录)是相同的,因此只能将收益归因于更好的网络。最引人注目的是,在具有挑战性的COCO数据集上,我们的COCO标准指标(mAP @ [。5,.95])增加了6.0%,相对改进了28%。该收益完全归因于残差网络所学的表示。
表7.使用基准Faster R-CNN在PASCAL VOC 2007/2012测试集中进行的对象检测mAP(%)。
表8. 使用基线Faster R-CNN在COCO验证集上进行的目标检测mAP(%)。
基于深层残差网络,我们在ILSVRC和COCO 2015多个竞赛中均获得了第一名:ImageNet检测,ImageNet定位,COCO检测和COCO分割。详细信息在附录中。
以上是关于ResNet:用于图像识别的深度残差网络的主要内容,如果未能解决你的问题,请参考以下文章