ResNet图像识别准确率暴降40个点!这个ObjectNet让世界最强视觉模型秒变水货
Posted 极市平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ResNet图像识别准确率暴降40个点!这个ObjectNet让世界最强视觉模型秒变水货相关的知识,希望对你有一定的参考价值。
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
来源: 新智元@微信公众号
【导读】MIT和IBM的研究团队近日发布一个不同寻常的目标识别数据集ObjectNet,包含50000张特意拍摄的照片,尽可能接近真实世界。该数据集让AlexNet、ResNet、Inception等最先进的图像识别模型纷纷栽倒,性能暴降40%~45%。
计算机视觉模型已经学会了非常精确地识别照片中的物体,甚至有些模型在某些数据集上的表现比人类更好。但是,同样的物体检测器如果在现实世界中使用,它们的性能会显著下降,这就给自动驾驶汽车和其他使用机器视觉的安全至关重要的系统带来了可靠性方面的担忧。
为了缩小模型在数据集和现实世界之间的性能差距,麻省理工学院(MIT)和IBM的研究人员着手创建了一个非常不同的目标识别数据集。该数据集名为ObjectNet,形式与ImageNet类似,ImageNet是一个众包的图片数据集,在很大程度上推动了现代人工智能的蓬勃发展。
与ImageNet不同的是,ObjectNet上的照片是付费请自由职业者拍摄的,而ImageNet则是从Flickr和其他社交媒体网站上收集照片。
ObjectNet数据集以不同的角度、不同的背景展示物体,以更好地表征3D对象的复杂性。
ObjectNet照片的拍摄还有诸多要求,例如物品要从侧面展示,以奇怪的角度拍摄,房间背景要杂乱,等等,目的是尽可能地接近现实世界。
当在ObjectNet上测试领先的目标检测模型时,它们的准确率从ImageNet上的97%下降到50% - 55%。
ObjectNet数据集
一个全新的视觉数据集,借鉴了其他科学领域的控制理念。
没有训练集,只有测试集!
有意识地从新的视角、在新的背景下展示物体。
测试集包含50000个图像,与ImageNet规模相当,具有旋转、背景和视点的控制。
313个对象类,其中113个与ImageNet重叠
模型性能大幅下降,这是现实世界中视觉系统的表现!
稳健的微调和非常困难的迁移学习问题
MIT计算机科学与人工智能实验室(CSAIL)和大脑、心智与机器中心(CBMM)的研究科学家Boris Katz说:“我们创建这个数据集是为了告诉人们,物体识别仍然是一个难题。我们需要更好、更智能的算法。”Katz和他的同事将在NeurIPS会议上介绍ObjectNet及其结果。
深度学习是推动AI最新进展的主要技术,它使用人工“神经元”层,在大量原始数据中寻找模式。比如,在对成百上千个样本进行训练后,AI能学会在照片中识别出椅子。但是,即使拥有数百万张图像的数据集也无法展示每个对象的所有可能的方向和设置,因此模型在现实生活中遇到这些对象时准确率可能大幅下降。

ObjectNet与ImageNet的对比
ObjectNet与传统图像数据集的另一个重要区别是:它不包含任何训练图像。大多数数据集被分成训练集和测试集,分别用于训练模型和测试模型的性能。但是训练集通常与测试集有着细微的相似之处,实际上导致了模型在测试时性能提升。
ImageNet拥有1400万张图片,看起来非常庞大。但是,如果不包括训练集,它只有50000张图片,与ObjectNet的规模相当。
“如果我们想知道算法在现实世界中的表现如何,我们应该在没有偏见的图像上测试它们,而且这些图像应该是它们从未见过的,”该研究的合著者、CSAIL和CBMM的研究科学家Andrei Barbu说。
ObjectNet:试图捕获真实世界物体的复杂性
很少有人会考虑与朋友分享来自ObjectNet的照片,这就是重点。研究人员从Amazon Mechanical Turk 上聘请自由职业者,为数百个随机摆放的家居物品拍照。他们需要在一个APP上收到分配给他们的拍摄任务,并且会有动画说明告诉他们如何摆放分配的物体,从什么角度拍摄,以及将物体摆放在厨房,浴室,卧室,还是客厅。
研究人员希望消除三种常见的偏见:物体从正面展示,处于标志性的位置,以及高度相关的场景——例如,厨房中堆放的盘子。
他们花了三年时间来构思这个数据集,并设计了一个APP来规范数据收集过程。“我们发现如何在控制各种偏差的条件下收集数据是非常棘手的,”该研究的合著者、MIT电子工程与计算机科学系的研究生David Mayo说:“我们还必须进行实验,确保我们提供的指示清晰明了,让拍摄者完全理解要求他们做什么。”
他们又花了一年的时间来收集实际数据,最后,兼职提交的所有照片中,有一半因为没有达到研究人员的要求而被丢弃。
许多照片都是在美国以外的地方拍摄的,因此,有些物体可能看起来很陌生。比如,熟透的橙子是绿色的,香蕉大小不一,衣服的样式和质地也各不相同。
ObjectNet vs. ImageNet:模型性能暴降40%-45%
当研究人员在ObjectNet上测试最先进的计算机视觉模型时,他们发现与ImageNet相比,模型性能下降了40-45个百分点。研究人员说,这些结果表明,目标检测器仍然很难理解物体是三维的,是可以旋转或移动到新环境中的。“这些概念并没有被构建到现代目标检测器的架构中,”研究的合著者、IBM的研究员Dan Gutfreund说。
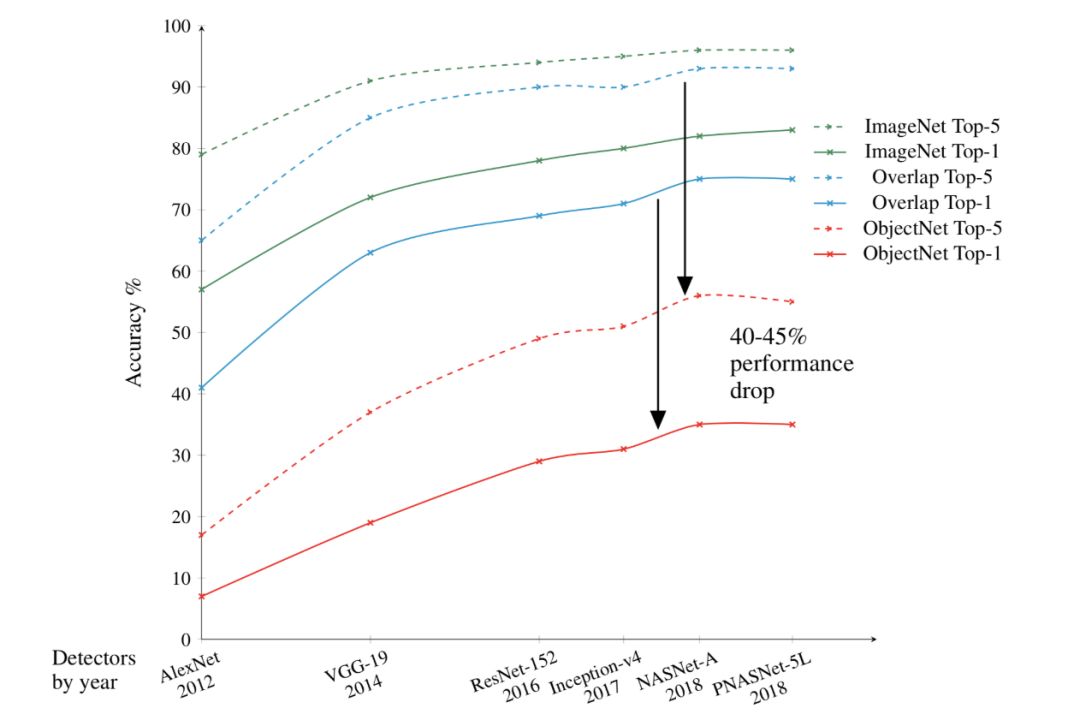
为了证明ObjectNet之所以难倒最先进的模型正是由于图像中物体的拍摄角度和摆放位置,研究人员允许模型先用ObjectNet的一半数据进行训练,然后再用另一半数据进行测试。在相同的数据集上进行训练和测试通常可以提高性能,但这里的模型只得到了轻微的改进,这表明目标检测器并没有完全理解现实世界中物体存在的方式。
2012年,AlexNet在ImageNet竞赛中大获全胜。自那以后,计算机视觉模型不断得到改进。随着数据集变得越来越大,模型的性能也越来越好。
但是,研究人员警告说,设计更大版本的ObjectNet并增加观察角度和方向,并不一定会带来更好的结果。ObjectNet的目标是激励研究人员提出下一波革命性的技术,就像ImageNet挑战赛最初的目标一样。
Katz说:“人们为这些检测器提供了大量数据,但回报却在递减。”“你不可能从任何角度、任何环境观察一个物体。我们希望这个新的数据集能够产生在现实世界中表现强大的计算机视觉算法,而不会出现意外的失败。”
该研究的其他作者是包括麻省理工学院的Julian Alvero、William Luo、Chris Wang和Joshua Tenenbaum。这项研究由美国国家科学基金会、MIT大脑、心智和机器中心、MIT-IBM Watson AI实验室、丰田研究所和SystemsThatLearn@CSAIL资助。
原文:
http://news.mit.edu/2019/object-recognition-dataset-stumped-worlds-best-computer-vision-models-1210
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割、OCR、姿态估计等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手
△长按关注极市平台
觉得有用麻烦给个在看啦~
以上是关于ResNet图像识别准确率暴降40个点!这个ObjectNet让世界最强视觉模型秒变水货的主要内容,如果未能解决你的问题,请参考以下文章